深度之眼Paper带读笔记NLP.Baseline.10.SGM
文章目录
- 前言
-
- 论文总览
- 学习目标
- 论文背景知识
-
- 多标签文本分类
-
- 解决思路
- 论文背景小结
- 研究成果
-
- SGM历史意义
- 论文其他部分写法介绍
-
- 模型写法
- 实验写法
- 结论写法
- 论文精读
-
- 论文结构
-
- 摘要
- 论文标题
- SGM模型
-
- Encoder
- Decoder介绍
- Output介绍
- 其他
- Global Embedding
- SGM模型应用与思考:
- 实验结果及分析
-
- Datasets
- 实验结果
- 论文总结
- 代码实现
前言
SGM: Sequence Generation Model for Multi-Label Classification
使用序列生成模型进行多标签文本分类
作者:Pengcheng Yang(一作)
单位:Peking University
会议:Coling2018 Best Paper(CCF B,2年一次)
这里的多标签是指一个样本有多个标签,且标签数目不确定。
在线LaTeX公式编辑器
论文总览
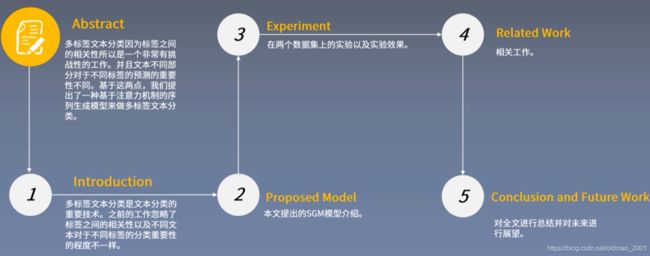
学习目标

论文背景知识
多标签文本分类
什么是:多标签文本分类(Multi-label Classification)
例如下面这道题目

其分类是:高中试题-理科试题-物理试题-选择题
注意,这里的分类是有相互关系的。
解决思路
1.使用softmax多分类器:softmax原来是取概率最高的那个作为结果,如果有两个分类,那么就是取最大的两个概率,如果第一次有4个概率(0.3,0.4,0.2,0.1),如果取阈值为0.3,那么就是得到两个分类为(0.3和0.4),第二次计算得到4个概率(0.29,0.4,0.2,0.11),这里如果使用阈值0.3那么就会只得到一个分类,因此,这里使用softmax的缺点是不好对每个分类的阈值进行划分。
2.使用多层sigmoid:这种方法有如下缺点:
无法处理分类数量不固定的场景;
而且计算量较大,如果分类类别很多,例如1000个,那么就要算1000次sigmoid;
无法学习到各个类别之间的关系
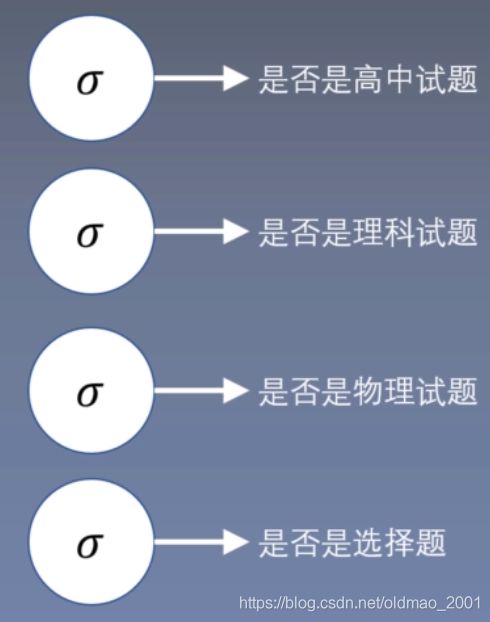
3.训练如下图所示的分类器(Classifier chains for multi-label classification)

也是多个sigmoid分类器,但是每个分类器的结果都做为特征输入到下一个分类器中,这个方法比上一个方法多使用到了类别之间的关系,缺点还是一样分类数量大的时候计算量大。
该方法在数据集小,类别少的任务表现还可以
4.深度学习解决方案(本文的baseline)
Ensemble Application of Convolutional and Recurrent Neural Networks for Multi-label Text Categorization

左边是一个CNN,做特征提取,相当于Encoder
中间是特征提取结果
右边是RNN,相当于Decoder
这个模型没有Attention,无法学习到类别之间的联系。
论文背景小结
- 多标签文本分类是自然语言处理的重要任务,多标签文本分类可以用到文本分类、推荐以及信息检索中。
Multi-label classification (MLC) is an important task in the field of natural language processing (NLP), which can be applied in many real-world scenarios, such as text categorization (Schapire and Singer, 2000), tag recommendation (Katakis et al., 2008), information retrieval (Gopal and Yang, 2010), and so on. The target of the MLC task is to assign multiple labels to each instance in the dataset. - 但是目前的多标签文本分类模型存在两个问题:没有注意到标签之间的相关性以及不同文本对于不同标签分类的重要性不同。(上面提到的法2和法3)
Binary relevance (BR就是二分类器) (Boutell et al., 2004) is one of the earliest attempts to solve the MLC task by transforming the MLC task into multiple single-label classification problems. However, it neglects the correlations between labels. Classifier chains (CC) proposed by Read et al. (2011) converts the MLC task into a chain of binary classification problems to model the correlations between labels. However, it is computationally expensive for large datasets. Other methods such as ML-DT (Clare and King, 2001), Rank-SVM (Elisseeff and Weston, 2002), and ML-KNN (Zhang and Zhou, 2007) can only be used to capture the first or second order label correlations or are computationally intractable when high-order label correlations are considered.
In recent years, neural networks have achieved great success in the field of NLP. Some neural network models have also been applied in the MLC task and achieved important progress. For instance, fully connected neural network with pairwise ranking loss function is utilized in Zhang and Zhou (2006). Kurata et al. (2016) propose to perform classification using the convolutional neural network (CNN). Chen et al. (2017这个是法四,当时的STOA) use CNN and recurrent neural network (RNN) to capture the semantic information of texts. However, they either neglect the correlations between labels or do not consider differences in the contributions of textual content when predicting labels.(这里是前人研究的两个缺点总结) - 为了解决这两个问题,我们使用Seq2Seq模型学习标签之间的相关性,使用注意力机制学习不同文本的重要性。(法4没有attention)
In this paper, inspired by the tremendous success of the sequence-to-sequence (Seq2Seq) model in machine translation (Bahdanau et al., 2014; Luong et al., 2015; Sun et al., 2017), abstractive summarization (Rush et al., 2015; Lin et al., 2018), style transfer (Shen et al., 2017; Xu et al., 2018) and other domains, we propose a sequence generation model with a novel decoder structure to solve the MLC task. The proposed sequence generation model consists of an encoder and a decoder with the attention mechanism. The decoder uses an LSTM to generate labels sequentially, and predicts the next label based on its previously predicted labels. Therefore, the proposed model can consider the correlations between labels by processing label sequence dependencies through the LSTM structure. Furthermore, the attention mechanism considers the contributions of different parts of text when the model predicts different labels. In addition, a novel decoder structure with global embedding is proposed to further improve the performance of the model by incorporating overall informative signals. - 实验表明,我们的模型能够在两个多标签文本分类数据集上大幅度领先基准模型,并且实验结果表明我们的模型可以学习到标签之间的相关性以及文本对于不同标签的重要性。
Extensive experimental results show that our proposed methods outperform the baselines by a large margin. Further analysis demonstrates the effectiveness of the proposed methods on correlation representation.
研究成果
HL:相关标签miss和不相关标签被预测比例。(就是把预测错的和没有预测到的标签加起来,求比例)
GE:Global Embedding。
SGM历史意义
·Coling2018的Best Paper,提出了一种新奇的模型SGM。
·给多标签文本分类提供了一种新的解决思路。
·在两个多标签文本分类数据集上取得了最好的结果。
论文其他部分写法介绍
模型写法
采用总分法来写
1.先写中的模型概述:Overview
2.写模型中每一个部分,例如:Encoder、Decoder、Global Embedding等
实验写法
1.数据集介绍,多个数据集要画表
2.实验设置:训练的硬件、训练使用的trick(早停)
3.对比模型(3个左右)
4.主实验:在那些任务或数据集上表现好,那些不好,为什么
5.实验分析,例如某些变量对于实验结果的影响;一些可视化结果(Attention);增量实验;消融实验;典型实验例子
结论写法
和introduction差不多,总结提出了什么模型,模型表现如何
展望可有可无。
论文精读
论文结构
摘要
1.多标签文本分类是自然语言处理一个重要的并且有挑战性的任务,相对于单标签分类,多标签文本分类更复杂的地方在于它的标签之间具有依赖关系。
2.此外,当前的模型也没有注意到不同的文本对于不同标签分类具有不同的重要性。
3.本文将多标签文本分类任务看成序列生成问题,并们使用了一种新的decoder结构来生成标签。
4.实验结果表明,我们的SGM模型能够大幅度提高多标签文本分类的效果,并且我们发现我们的模型能够捕捉标签之间的关系,并且对于不同标签,自动选择不同的词进行分类。
论文标题
- Introduction
- Proposed Model
2.1Overview
2.2 Sequence Generation
2.3 Global Embedding - Experiments
3.1Datasets
3.2Evaluation Metrics
3.3Details
3.4 Baselines
3.5Results
3.6Analysis and Discussion
3.6.1 Exploration of Global Embedding
3.6.2The impact of Mask and Sorting
3.6.3 Error Analysis
3.6.4 Visualization of Attention
3.6.5 Case Study - Related Work
- Conclusion
SGM模型
左边Encoder是双向的LSTM
右边Decoder包含:MS(mask softmax),GE(Global Embedding)

Encoder
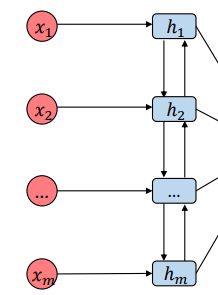
双向LSTM,应该写过很多了:
正向的输入是前一个时间步的结果和数据:
h → i = LSTM → ( h → i − 1 , x i ) \overrightarrow{h}_i=\overrightarrow{\text{LSTM}}(\overrightarrow{h}_{i-1},x_i) hi=LSTM(hi−1,xi)
反向的输入是后一个时间步的结果和数据:
h ← i = LSTM ← ( h ← i − 1 , x i ) \overleftarrow{h}_i=\overleftarrow{\text{LSTM}}(\overleftarrow{h}_{i-1},x_i) hi=LSTM(hi−1,xi)
然后把最后两个方向最后一个时间步的结果concat起来:
h i = [ h → i ; h ← i ] h_i=[\overrightarrow{h}_i;\overleftarrow{h}_i] hi=[hi;hi]
Decoder介绍
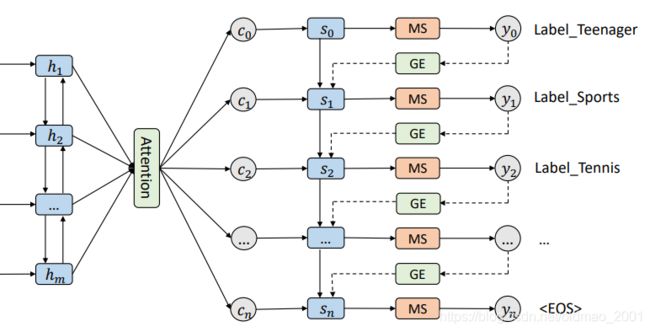
整个Decoder公式:
s t = LSTM ( s t − 1 , [ g ( y t − 1 ; c t − 1 ) ] ) s_t=\text{LSTM}(s_{t-1},[g(y_{t-1};c_{t-1})]) st=LSTM(st−1,[g(yt−1;ct−1)])
s 0 = h m s_0=h_m s0=hm
整个计算流程是根据 s 0 s_0 s0算 c 0 c_0 c0,然后用 s 0 , c 0 , y 0 s_0,c_0,y_0 s0,c0,y0算 s 1 s_1 s1,然后根据 s 1 s_1 s1算 c 1 c_1 c1,然后用 s 1 , c 1 , y 1 s_1,c_1,y_1 s1,c1,y1算 s 2 s_2 s2,以此类推。
根据 s t s_t st算 c t c_t ct的过程如下:
e t i = v a T tanh ( W a s t + U a h i ) e_{ti}=v_a^T\text{tanh}(W_as_t+U_ah_i) eti=vaTtanh(Wast+Uahi)
上式中 v a T v_a^T vaT可以看做attention的Query, tanh ( W a s t + U a h i ) \text{tanh}(W_as_t+U_ah_i) tanh(Wast+Uahi)可以看做Key和Value(这两个东西通常一样)
α t i = exp ( e t i ) ∑ j = 1 m exp ( e t i ) \alpha_{ti}=\cfrac{\text{exp}(e_{ti})}{\sum_{j=1}^m\text{exp}(e_{ti})} αti=∑j=1mexp(eti)exp(eti)
上式求的是attention的weight
c t = ∑ j = 1 m α t i h i c_t=\sum_{j=1}^m\alpha_{ti}h_i ct=j=1∑mαtihi
最后attention的结果就是加权求和
Output介绍
下面来看看MS(Mask Softmax),之前的分类如果已经输出之后,那么后面就不用再出现了,不然会出现重复标记的问题。
先是两层的FC:
o t = W o f ( W d s t + V d c t ) o_t=W_of(W_ds_t+V_dc_t) ot=Wof(Wdst+Vdct)
然后接softmax:
y t = s o f t m a x ( o t + I t ) y_t=softmax(o_t+I_t) yt=softmax(ot+It)
其中 I t I_t It表示之前t-1个时间步内已经预测过该标签,将值设置为负无穷大经过softmax的就变成0
( I t ) i = { − ∞ if the label l i has been predicted at previous t-1 time steps. 0 otherwise (I_t)_i=\begin{cases} -\infty & \text{ if the label } l_i \text{ has been predicted at previous t-1 time steps. } \\ 0 & \text{ otherwise } \end{cases} (It)i={ −∞0 if the label li has been predicted at previous t-1 time steps. otherwise
其他
注意看黑体
At the training stage, the loss function is the cross-entropy loss function. We employ the beam search algorithm (Wiseman and Rush, 2016) to find the top-ranked prediction path at inference time. The prediction paths ending with the eos are added to the candidate path set.
Global Embedding
背景:
·上一个时间步预测错误会导致后续的都出错(学名:曝光误差),如何缓解这一问题。
·解决思路:减少上一时间步的影响,或者自适应选择上一时间步对下一时间步的影响。
g ( y t − 1 ) = ( 1 − H ) ⊙ e + H ⊙ e ˉ g(y_{t-1})=(1-H)\odot e+H\odot \bar e g(yt−1)=(1−H)⊙e+H⊙eˉ
H相当于权重,当H为1的时候意思是全部embedding来自 e ˉ \bar e eˉ(平均embedding),相当于减少上一个时间步的embedding影响,当H为1的时候意思是全部embedding来自 e e e(上一个时间步的embedding)
平均embedding的公式,y是softmax的输出概率,这里作为权重:
e ˉ = ∑ i = 1 L y t − 1 ( i ) e i \bar e=\sum_{i=1}^Ly_{t-1}^{(i)}e_i eˉ=i=1∑Lyt−1(i)ei
权重公式(相当于两个FC操作):
H = W 1 e + W 2 e ˉ H=W_1e+W_2\bar e H=W1e+W2eˉ
SGM模型应用与思考:
1.直接应用在多标签文本分类当中。
2.可以结合BERT一起用于多标签文本分类。
3.将任务和模型结合的更密切是很好的idea。
实验结果及分析
Datasets
两个,最后一列是平均每个样本对应的标签数量

评价指标是HL和F1

实验结果
Global Embedding两部分比例对于结果的影响。
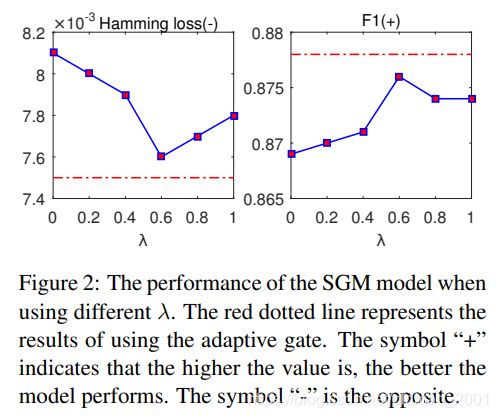
图中的 λ \lambda λ相当于下式中的H
g ( y t − 1 ) = ( 1 − H ) ⊙ e + H ⊙ e ˉ g(y_{t-1})=(1-H)\odot e+H\odot \bar e g(yt−1)=(1−H)⊙e+H⊙eˉ
可以看到,当 λ = 0.6 \lambda=0.6 λ=0.6时模型最优,相当于前一个embedding影响权重为0.6,全局平均embedding影响权重为0.4的时候模型最优。
·Mask和sort对于结果的影响。
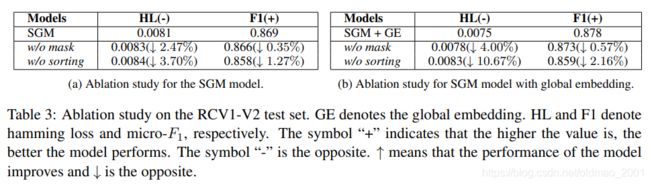
上面两个表显示了不使用Mask和sort结果都有不同程度的下降。
句子长度的影响:越长效果越差(待解决)

可视化结果:

上图显示了在不同分类标签关注的词的侧重点不一样。即不同词对不同标签贡献度不一样。
论文总结
关键点
·之前的模型没有注意到标签之间的相关性以及不同标签分类的文本重要性不同。,
·本文通过Seq2Seq模型学习标签之间的相关性,通过注意力机制学习不同标签的重要相关文本。
·提出了SGM模型。
创新点
·将多标签分类任务看成文本生成任务,这可以学习到标签之间的相关性。
·本文提出了一种新的decoder结构,它不仅可以捕捉标签之间的关系,并且可以自适应选择不同的文本去分类不同的标签。(两个优点)
·实验结果发现我们的SGM模型能够大幅度提高多标签文本分类的效果。
启发点
·它们忽略了标签之间的相关性,并且它们没有注意到不同文本对于预测不同标签的重要性不同。
However,they either neglect the correlations between labels or do not consider differences in the contributions of textual content when predicting labels.(Introduction P3)
然而,beam search不能根本上解决曝光误差(exposure bias)问题,因为这个误差可能出现在每一条可能得路径上,而beam search只是选择几条最好的路径。
However,beam search can not fundamentally solve the problem because the exposure bias phenomenon is likely to occur for all candidate paths.(Global Embedding P1)
代码实现
本文自带代码:
https://github.com/lancopku/SGM
原文的数据集也有在谷歌网盘有下载,训练集测试集统统都有,直接可以用

src是源语言
tgt是目标语言,就是对应的多个分类。
先要根据作者的提示对数据进行处理
Preprocess the downloaded data:
python3 preprocess.py -load_data ./data/ -save_data ./data/save_data/ -src_vocab_size 50000
All the preprocessed data will be stored in the folder ./data/save_data/
具体不贴了。