华为手撕代码+剑指offer总结 (python+c语言)
文章目录
- 1.华为手撕代码总结
- 1.1排序问题
- 1.2链表求和
- 1.3树的前中后序遍历(递归/循环写法)
- 1.4树的链表化
- 1.5给一个初始饮料瓶数,三个空瓶换一瓶,可以赊一瓶,求最后能喝几瓶
- 1.6岛屿最大面积问题
- 1.7自己面试手撕的5道算法题
- 2.剑指offer
- 2.1 数字中重复的数字
- 2.1 二维数组中的查找
- 2.2 替换空格
- 2.3 从尾到头打印链表
- 2.4 重建二叉树
- 2.5用两个栈实现队列
- 2.6旋转数组的最小数
- 2.7斐波那契数列
- 2.8 跳台阶
- 2.8 变题:变态跳台阶
- 2.9 矩形覆盖
- 2.10二进制中1的个数
- 2.11数值的整数次方
- 2.12 打印从1到最大的n位数
- 2.13删除链表中的节点
- 2.14正则表达式匹配
- 2.15调整数组顺序使奇数位于偶数前面
- 2.13 链表中倒数第K个节点
- 2.14 反转链表
- 2.15 合并两个排序的链表
- 2.16 树的子结构
- 2.17 二叉树的镜像
- 2.18 顺时针打印矩阵
- 2.19 包含min函数的栈
- 2.20栈的压入弹出序列
- 2.21 从上往下打印二叉树
- 2.22 二叉搜索树的后序遍历结果
- 2.23 二叉树中和为某一值的路径
- 2.24 复杂链表的复制
- 2.25 二叉搜索树与双向链表
- 2.26 字符串的排序 (思路有些绕)
- 2.27 数组中出现次数超过一半的数字
- 2.28 最小的K个数
- 2.29 连续子数组的最大和
- 2.30 整数中1出现的次数
- 2.31 把数组排成最小的数
- 2.32 丑数
- 2.33 第一次只出现一次的字符串
- 2.34 数组中的逆序对
- 2.35 两个链表的公共节点
- 2.36 数字在排列数组中出现的次数
- 2.37 二叉树的深度
- 2.38 平衡二叉树
1.华为手撕代码总结
1.1排序问题
- 冒泡排序
def bubbleSort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1] :
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
- 快排
思路:快速排序基本思想是:如序列[6,8,1,4,3,9],选择6作为基准数。从右向左扫描,寻找比基准数小的数字为3,交换6和3的位置,[3,8,1,4,6,9],接着从左向右扫描,寻找比基准数大的数字为8,交换6和8的位置,[3,6,1,4,8,9]。重复上述过程,直到基准数左边的数字都比其小,右边的数字都比其大。然后分别对基准数左边和右边的序列递归进行上述方法。详细可见:https://www.jianshu.com/p/2b2f1f79984e
def q_sort(L, left, right):
if left < right:
pivot = Partition(L, left, right)
q_sort(L, left, pivot - 1)
q_sort(L, pivot + 1, right)
return L
def Partition(L, left, right):
pivotkey = L[left]
while left < right:
while left < right and L[right] >= pivotkey:
right -= 1
L[left] = L[right]
while left < right and L[left] <= pivotkey:
left += 1
L[right] = L[left]
L[left] = pivotkey
return left
1.2链表求和
题目解析:
3->1->5->null
5->9->2->null
3+5=8
1+9=10,得到的进位1到下一个节点,第二个节点为0
1(上一个节点的进位)+5+2=8
结果为:
8->0->8->null
代码实现:
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def addLists(self, l1, l2):
#判断是否某一链表为None,是返回另一条
if l1==None:return l2
if l2 == None:return l1
h1=l1
h2=l2
#只有两个链表的下一个节点数都为None,退出循环
while h1.next is not None or h2.next is not None:
#若只有一条链表的下一个节点为None,补充为0,不影响后续的加法结果
if h1.next ==None:h1.next=ListNode(0)
if h2.next ==None:h2.next=ListNode(0)
h1.val=h1.val+h2.val
#当加结果>=10,当前结果节点为个位数,下一个节点+1
if h1.val>=10:
h1.val=h1.val%10
h1.next.val+=1
h1=h1.next
h2=h2.next
else:
h1.val=h1.val+h2.val
#链表尾部的计算,如果>=10,则在尾部再添加一个节点
if h1.val>=10:
h1.val=h1.val%10
h1.next=ListNode(1)
return l1
1.3树的前中后序遍历(递归/循环写法)
- 递归
class Solution:
def inorderTraversal(self, root): #中序遍历
if not root:
return []
return self.inorderTraversal(root.left) + [root.val] + self.inorderTraversal(root.right)
def preorderTraversal(self, root): #前序遍历
if not root:
return []
return [root.val] + self.inorderTraversal(root.left) + self.inorderTraversal(root.right)
def postorderTraversal(self, root): #后序遍历
if not root:
return []
return self.inorderTraversal(root.left) + self.inorderTraversal(root.right) + [root.val]
- 循环实现
原理详细解释:https://www.cnblogs.com/bjwu/p/9284534.html
class Solution:
def inorderTraversal(self, root): #中序遍历
stack = [] #用栈实现
sol = [] #结果
curr = root #节点运动位置
while stack or curr:
if curr:
stack.append(curr)
curr = curr.left
else:
curr = stack.pop()
sol.append(curr.val)
curr = curr.right
return sol
def preorderTraversal(self, root): # 前序遍历
stack = []
sol = []
curr = root
while stack or curr:
if curr:
sol.append(curr.val)
stack.append(curr.right)
curr = curr.left
else:
curr = stack.pop()
return sol
def postorderTraversal(self, root): # 后序遍历
stack = []
sol = []
curr = root
while stack or curr:
if curr:
sol.append(curr.val)
stack.append(curr.left)
curr = curr.right
else:
curr = stack.pop()
return sol[::-1]
1.4树的链表化
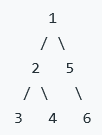 输入
输入  输出
输出
思路:对于每一颗子树进行后序遍历,将右子树连接到左子树的右子树上,将左子树连接到根节点的右子树上;递归进行遍历
# Definition for a binary tree node.
# class TreeNode(object):
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution(object):
def flatten(self, root):
if root == None:
return None
self.flatten(root.left)
self.flatten(root.right)
if root.left != None:
p = root.left
while p.right != None:
p = p.right
p.right = root.right
root.right = root.left
root.left = None
1.5给一个初始饮料瓶数,三个空瓶换一瓶,可以赊一瓶,求最后能喝几瓶
def changeWater(cout_0):
# 喝水的瓶数
cout_1=0
if cout_0<2:
return 0
while cout_0>2:
cout_1+=cout_0//3
cout_0=cout_0//3+cout_0%3
if cout_0==2:
cout_1+=1
return cout_1
1.6岛屿最大面积问题
一个二维的01矩阵,上下左右都是1时算联通,求1组成岛的最大面积。
思路:递归思想,若发现某一位置的数为1,则它周围上下左右都要递归,但是!!!此处递归时需要注意的是,每找到一个位置的数为1时,就要把这个位置的数变为0,否则会进入死循环。
def max_area_of_island(grid):
if not grid:
return 0
l, h = len(grid), len(grid[0])
def dfs(i, j):
if 0 <= i < l and 0 <= j < h and grid[i][j]:
grid[i][j] = 0 #每找到一个位置的数为1时,就要把这个位置的数变为0
return 1 + dfs(i - 1, j) + dfs(i + 1, j) + dfs(i, j - 1) + dfs(i, j + 1)
return 0
#1)通俗写法
for i in range(lenr):
for j in range(lenc):
if grid[i][j] == 1:
count = dfs(i,j)
result = max(result,count)
return result
#2)精简写法
result = [dfs(i, j) for i in range(l) for j in range(h) if grid[i][j]]
return max(result) if result else 0
1.7自己面试手撕的5道算法题
看面经人家两轮技术面手撕两道算法题,到我这…手撕了5道…大概…也许…因为我不是科班出身???
一面(45min):
首先四道算法题,选一道15分钟写完,时间紧迫我选了第一道,给一个列表,求最大连续子序列和问题。
然后笔试题复盘,字符串反转问题改进版,("hello world"变成"world hello"的复杂版,只不过会有些字符干扰,需要判断删除。)
二面(1h):
给一个n数,返回列表,比如n = 13,输出值[1,10,11,12,13,2,3,4,5,6,7,8,9],0 链表反转;
给一个链表,遍历一次,找出倒数第k个节点(这个只说思路,不用手写代码了)
2.剑指offer
2.1 数字中重复的数字
思路1:建立一个同等大小的空数组,原数组的值为新数组的下标,访问一次置1,再次访问直接返回该值。
思路2:若当前值的hash值已经加过1了,则直接返回。
//思路1
int findRepeatNumber(int* nums, int numsSize){
int* arr = calloc(numsSize,sizeof(int)); //函数calloc()会将所分配的内存空间中的每一位都初始化为零
for (int i=0; i< numsSize; i++){
if (0 == arr[nums[i]]){
arr[nums[i]] = 1;
}
else{
return nums[i];
}
}
return -1;
}
//思路2:
int findRepeatNumber(int* nums, int numsSize){
int *hash = (int *)calloc(numsSize, sizeof(int));
for(int i = 0; i < numsSize; i++){
if(hash[nums[i]] == 1){
return nums[i];
} else {
hash[nums[i]]++;
}
}
return -1;
}
2.1 二维数组中的查找
def Find(target, array): # array 二维列表
if array == [[]]:
return False
m = len(array) # m行n列
n = len(array[0])
i = 0
j = n - 1
while i < m or j >= 0:
if target == array[i][j]: #从右上角遍历
return True
elif target > array[i][j]: # 右上角小于此数,删除行;否则删除列
i += 1
if i >= m:
return False
else:
j -= 1
if j < 0:
return False
c语言实现:
bool findNumberIn2DArray(int** matrix, int matrixSize, int* matrixColSize, int target){
// printf("%d\n",*matrixColSize);
int m = 0, n = *matrixColSize -1 ; //注意带*,否则表示的是地址。
if (matrixSize==0 && *matrixColSize ==0){
return false;
}
while(m < matrixSize && n >=0){
if (matrix[m][n] == target){
return true;
}
else if(matrix[m][n] > target){
n--;
}
else{
m++;
}
}
return false;
2.2 替换空格
问题:请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
def replaceSpace(s):
li = []
tmp = ""
for item in s:
if item!= " ":
tmp += item
else:
li.append(tmp)
li.append("%20")
tmp = ""
li.append(tmp)
result = "".join(li)
return result
c语言实现:
char* replaceSpace(char* s){
int l = strlen(s),i = 0,j = 0;
char *s_n = calloc(3*l+1,sizeof(char)); //申请动态内存,所以用指针,指向地址
//3*l+1 是考虑最差的情况,倘若字符串都是空格,则是3倍,且还要考虑到结束符'\0'
while(s[i]!= '\0'){
if (s[i]!= ' '){ //用单引号,不是双引号!!!
s_n[j++] = s[i];
i++;
}
else{
// printf("%d",1);
s_n[j++] = '%';
s_n[j++] = '2';
s_n[j++] = '0';
i++;
}
}
return s_n;
}
学习:
1.calloc,malloc的区别
函数malloc()和函数calloc()的主要区别是前者不能初始化所分配的内存空间,而后者能。如果由malloc()函数分配的内存空间原来没有被使用过,则其中的每一位可能都是0;反之,如果这部分内存曾经被分配过,则其中可能遗留有各种各样的数据。
函数calloc()会将所分配的内存空间中的每一位都初始化为零,也就是说,如果你是为字符类型或整数类型的元素分配内存,那麽这些元素将保证会被初始 化为0;如果你是为指针类型的元素分配内存,那麽这些元素通常会被初始化为空指针;如果你为实型数据分配内存,则这些元素会被初始化为浮点型的零。
2.strlen(s)计算字符串长度
2.3 从尾到头打印链表
问题:输入一个链表,按链表从尾到头的顺序返回一个ArrayList。
def printListFromTailToHead(listNode):
tmp = []
while listNode:
tmp.append(listNode.val)
listNode = listNode.next
tmp.reverse()
return tmp
c语言:
//思路1:先将链表反转,再逐个打印各个节点。该算法时间复杂度为O(N)。
int* reversePrint(struct ListNode* head, int* returnSize){
if(head==0){
*returnSize=0;
return 0;
}
struct ListNode*tmp,*header=head;
int length=1,i;
while(head->next!=0){
length++;
tmp=head->next;
head->next=tmp->next;
tmp->next=header;
header=tmp;
}
*returnSize=length;
int *res=malloc(length*sizeof(int));
for(i=0;i<length;i++){
res[i]=header->val;
header=header->next;
}
return res;
}
//思路2:用一个数组反向存储链表节点。
int* reversePrint(struct ListNode* head, int* returnSize){
struct ListNode* p=head;
int * a=(int*)malloc(sizeof(int)*10000); //malloc的使用,分配动态内存,定义为指针的形式!!
int n=0;//计算出链表大小
while(p!=NULL){
n++;
p=p->next;
}
*returnSize=n;
p=head;
while(n--){ //用一个数组反向存储链表节点。
a[n]=p->val;
p=p->next;
}
return a;
}
学习:
1.链表的表示
2.4 重建二叉树
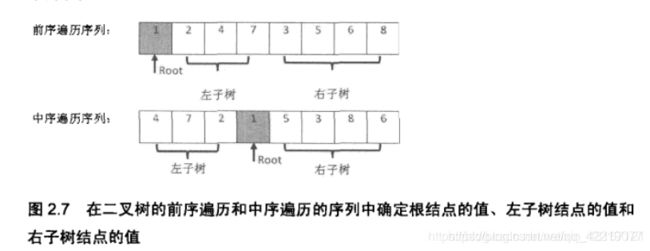
class Solution:
def reConstructBinaryTree(self, pre, tin):
# write code here
if pre == [] or tin == []:
return None
root = TreeNode(pre[0])
tmp = pre.pop(0)
index = tin.index(tmp)
left = tin[:index]
right = tin[index+1:]
root.left = self.reConstructBinaryTree(pre[:len(left)],left)
root.right = self.reConstructBinaryTree(pre[len(left):],right)
return root
c语言解法:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* };
*/
struct TreeNode* buildTree(int* preorder, int preorderSize, int* inorder, int inorderSize){
if(preorderSize==0) {
return NULL;
}
int all,num=preorderSize; //标记先序数组第一个元素在中序数组位置
struct TreeNode* node=malloc(sizeof(struct TreeNode));
node->val=preorder[0];
while(num--) {
if(inorder[num]==preorder[0]){ 匹配preorder[0]在inorder的下标
break;
}
}
all=num+1;
node->left=buildTree(preorder+1,num,inorder,num); //数组名preorder表示其首地址preorder[0],加1表示preorder[1] 另外:没有struct TreeNode*前缀!!!!
node->right=buildTree(preorder+all,preorderSize-all,inorder+all,inorderSize-all);
return node;
}
学习:
1.用结构体表示一个树;
2.数组名表示其首地址。
3.递归的实现。
2.5用两个栈实现队列
class Solution:
stack1 = [] #定义两个栈为类属性
stack2 = []
def push(self, node): #stack1用来实现append操作
self.stack1.append(node)
def pop(self):
if self.stack2 == []: #stack1用来实现pop操作
while self.stack1:
self.stack2.append(self.stack1.pop())
return self.stack2.pop()
C语言
typedef struct {
int len;
int top1;
int top2;
int *s1;//栈1,入栈=入队
int *s2;//栈2,出栈=出队
} CQueue; //定义一个队列
CQueue* cQueueCreate() {
CQueue *queue = malloc(sizeof(CQueue)); //结构体定义时别忘记*号
queue->len = 10000;
queue->top1 = -1;
queue->top2 = -1;
queue->s1 = malloc(queue->len * sizeof(int));
queue->s2 = malloc(queue->len * sizeof(int));
return queue;
}
void cQueueAppendTail(CQueue* obj, int value) {
if(obj->top1 == -1)
while(obj->top2 != -1) //s2要空,将s1填满后,再添加新数。
obj->s1[++(obj->top1)] = obj->s2[obj->top2--];
obj->s1[++(obj->top1)] = value;
}
int cQueueDeleteHead(CQueue* obj) {
if(obj->top2 == -1)
while(obj->top1 != -1) //s1要抽空,填入到s2中后,再删除s2的末尾
obj->s2[++(obj->top2)] = obj->s1[obj->top1--];
return obj->top2==-1 ? -1 : obj->s2[obj->top2--];
}
void cQueueFree(CQueue* obj) {
free(obj->s1);
free(obj->s2);
free(obj);
}
学习:
1.typedef 重新定义结构体的名字为CQueue
2.i++和++i 的区别。++i是自加完后在进行下一步计算,i++是先用i计算完后,再进行自加。
3.free()释放动态内存
2.6旋转数组的最小数
问题:把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
思路:采用二分法,时间复杂度为logn
def minNumberInRotateArray(rotateArray):
if len(rotateArray) == 0:
return 0
left = 0
right = len(rotateArray)-1
while left < right:
mid = int((left+right)/2)
if rotateArray[mid] > rotateArray[right]: #最小值在右边 5>2
left = mid+1
elif rotateArray[mid] < rotateArray[right]: #最小值在右边
right = mid
else:
right -= 1 #right-left=1的情况,right-1跳出循环
return rotateArray[left]
c语言----------二分法:分三种情况。
1)首中末位相同,则首尾分别+1 -1。 比如 2 1 2 2 2 2,则减少数组至 1 2 2 2
2)中间项大于最右项,则说明最小的数在中间项与最右项的里面。比如 3 4 5 1 2,中间项5,最右项 2,则在1里面找。
3)中间项小于等于最右项,则说明最小数在最左项与中间项里面找。比如 3 1 3 3 3,最左项3,中间项3,最右项3,则在最左项与中间项之间找到。
int minArray(int* numbers, int numbersSize){
int left = 0; int right = numbersSize - 1;
while(left < right){
int mid = (left + right) / 2;
if((numbers[mid] == numbers[left] && numbers[mid] == numbers[right])){
left += 1;
right -= 1;
}else if(numbers[mid] > numbers[right]){
left = mid + 1;
}else if(numbers[mid] <= numbers[right]){
right = mid;
}
}
return numbers[left];
}
学习:二分法的思想
2.7斐波那契数列
思想:动态规划
def Fibonacci(n):
dp = []
if n<2: #n=0/1特殊情况讨论
return n
else:
dp = [0,1]
for i in range(2,n+1): #求得是第n项,而第0项为0
dp.append(dp[i-2]+dp[i-1])
return dp[-1]
C语言
int fib(int n){
if(n==0){return 0;}
if(n==1){return 1;}
int *arr = malloc(101*sizeof(int));
arr[0] = 0;
arr[1] = 1;
if (n>=2){
for (int i =2; i<=n;i++){
arr[i] = (arr[i-1] + arr[i-2]) % 1000000007; //取模==取余
}
}
return arr[n];
}
2.8 跳台阶
2.7的变题
def jumpFloor(number):
if number < 3:
return number
else: #其实有没有else都不影响,只不过有了更好理解。
dp = [0,1,2]
for i in range(3,number+1):
dp.append(dp[i-1]+dp[i-2])
return dp[-1]
c语言
int numWays(int n){
if(n==0){return 1;}
if(n==1){return 1;}
int* dp = malloc(101*sizeof(int));
dp[0] = 1;
dp[1] = 1;
for (int i=2; i<=n;i++){
dp[i] = (dp[i-1]+dp[i-2]) %1000000007;
}
return dp[n];
}
2.8 变题:变态跳台阶
def jumpFloorII(number):
if number < 3:
return number
dp = [0,1,2]
for i in range(3,number+1):
dp.append(sum(dp)+1)
return dp[-1]
2.9 矩形覆盖
原理同2.7,实现代码都一样的。
解题思路:
当n=1时,记作F(1), 共有1种方法;
当n=2时,记作F(2), 共有两种方法;
当n=3时,记作F(3), 分为两种情况:
第一次用一个矩形竖着覆盖(左图蓝色),则剩下共有F(n-1)种方法,即F(2) 种方法;
第一次用一个矩形横着覆盖(右图蓝色),则剩下绿色区域只能有图示一种方法,那么剩下F(n-2)种方法,即F(1) 种方法;

def rectCover(number):
if number < 3:
return number
dp = [0,1,2]
for i in range(3,number+1):
dp.append(dp[i-1]+dp[i-2])
return dp[-1]
2.10二进制中1的个数
def NumberOf1(self, n):
# write code here
count = 0
while n&0xffffffff !=0: #这一行不能用while n:代替,运行会超时!!!
n = n&(n-1)
count +=1
return count
c语言
思路:https://blog.csdn.net/u014801432/article/details/81286735
int hammingWeight(uint32_t n) {
int count = 0;
while(n!=0){
n = n & (n-1); //核心!!!
count ++;
}
return count;
}
2.11数值的整数次方
def Power(base, exponent):
if exponent == 0: #递归边界条件
return 1
elif exponent == 1:
return base
elif exponent == -1:
return 1 / base
if abs(exponent) % 2 == 0: #递归+二分法,减少运行次数
result = Power(base, abs(exponent) // 2)
result *= result
else:
result = Power(base, abs(exponent) // 2)
result *= result
result *= base
if exponent < 0:
result = 1 / result
return result
c语言
//自己版本1:
double myPow(double x, int n){
long num ; //定义为long
double result;
if(n==0){return 1;}
if(n==1){return x;}
if(n==-1){return 1/x;}
// printf("%d%d\n",n,-n);
if(n < 0){
num = n;
num = -num;} //注意!!!num = -n 就报错,超出int长度
else{num = n;}
if (num%2==0){
result = myPow(x,num/2);
result *= result;
}
else{
result = myPow(x,num/2);
result *= result;
result *= x;
}
if (n<0){result = 1/result;}
return result;
}
//简易版本2:
double myPow(double x, int n) {
if (0 == n) {
return 1;
}
if (n < 0) {
return 1 / (x * myPow(x, -(n + 1)));
}
if (0 == (n & 1)) {
//判断为偶数
return myPow(x * x, n / 2);
} else {
//奇数
return x * myPow(x * x, (n - 1) / 2);
}
}
注意:
1.num 设计为long类型,因为n取负数,-n会超出int限制。
2.12 打印从1到最大的n位数
int* printNumbers(int n, int* returnSize){
int nums = 0;
for (int i =0; i<n; i++){
nums += 9*pow(10,i);
}
int* arr = (int*)malloc((nums+1)*sizeof(int));
for (int j = 0; j<=nums;j++){
arr[j] = j+1;
}
*returnSize = nums;
return arr;
}
2.13删除链表中的节点
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteNode(struct ListNode* head, int val){
if(head == NULL ){return head;}
if(head->val == val){return head->next;}
struct ListNode* tmp = head;
while(tmp->next!= NULL){
if (tmp->next->val == val){
tmp->next = tmp->next->next;
}
else{tmp = tmp->next;}
}
return head; //指针指的向地址,tmp变,head也变
}
2.14正则表达式匹配
递归思路:(简单化假设字符串中只有一个‘’)
“mississpp”
“misissp.”
1、如果模式字符串p为空,那么代表已经匹配完毕,则字符串s也必须为空,作为递归的出口。
2、由于模式中‘’和之前的一个字符有关,所以我们在递归新的p时得判断p中的第二个字符是否为‘’,若为‘*’:
新字符串"ssisspp"
“sissp.”
判断s[0]是否和p[2]一致,若一致则代表部分已经判断完毕,后边继续判断,不一致,代表个数尚未判断完毕,则s+1作为新的s继续递归,
直至判断到新字符串"isspp"
“sissp.”
之后便是"isspp"
“issp.”
这时候我们知道*判断完了,新的字符串则开始继续判断,不一致返回0,一致返回1
bool isMatch(char* s, char* p){
if(*p == '\0')
{
if(*s == '\0') return true;
else return false;
} //递归出口
if(*(p+1) == '*')
{
if(isMatch(s, p+2)) return true;
if(*s != '\0' && (*s == *p || *p == '.') && isMatch(s+1, p)) return true;
}//判断‘*’符号是否能匹配上
if(*s != '\0' && (*s == *p || *p == '.') && isMatch(s+1, p+1)) return true; //判断正常字符和‘.’的逐一匹配
else return false;
}
学习:
1)递归思想(要有递归结束条件)
2)字符串要用单引号!!!!
3)p+1和(p+1)的区别
2.15调整数组顺序使奇数位于偶数前面
def reOrderArray(self, array):
list1 = [item for item in array if item%2 == 1]
list2 = [item for item in array if item%2 == 0]
result = list1 + list2
return result
2.13 链表中倒数第K个节点
# -*- coding:utf-8 -*-
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
def FindKthToTail(head, k):
# write code here
if head == None or k==0: #特殊情况1:链表为空或者k=0
return None
root1 = head
root2 = head
i = 0
while i < k-1: #root1走到k-1步,第k步两个节点一同开始走
i+=1
if root1.next != None:
root1 = root1.next
else:
return None #特殊情况2:链表长度不为K
while root1.next != None:
root1 = root1.next
root2 = root2.next
return root2
2.14 反转链表
def ReverseList(pHead):
# write code here
if pHead == None:
return None
new_head = None
idencity = None
while pHead:
idencity = pHead.next
pHead.next = new_head
new_head = pHead
pHead = idencity
return new_head
2.15 合并两个排序的链表
思路:递归
def Merge(pHead1, pHead2):
if not pHead1:
return pHead2
if not pHead2:
return pHead1
if pHead1.val <= pHead2.val:
pHead1.next = self.Merge(pHead1.next, pHead2)
return pHead1
else:
pHead2.next = self.Merge(pHead1, pHead2.next)
return pHead2
2.16 树的子结构
分两步:1)树1中找到树2的根节点;2)找到之后,对比左右子树是否相等
# -*- coding:utf-8 -*-
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def HasSubtree(self, pRoot1, pRoot2):
if pRoot1 == None or pRoot2 == None:
return False
return self.issubtree(pRoot1, pRoot2)
def issubtree(self,pRoot1, pRoot2):
if pRoot2 == None: #pRoot2先遍历完则是
return True
if pRoot1 == None: #pRoot1先遍历完则不是
return False
if pRoot1 == None and pRoot2 == None: #同时遍历完也是子树
return True
res = False
if pRoot1.val == pRoot2.val: #查找该节点的左右节点是否相等
res = self.issubtree(pRoot1.left, pRoot2.left) and self.issubtree(pRoot1.right, pRoot2.right)
#如果res为True,返回True,否则继续从左节点开始查找,如果还失败,从右节点开始查找
return res or self.issubtree(pRoot1.left, pRoot2) or self.issubtree(pRoot1.right, pRoot2)
2.17 二叉树的镜像
# -*- coding:utf-8 -*-
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
# 返回镜像树的根节点
def Mirror(self, root):
# write code here
if root == None:
return None
root.left,root.right = root.right,root.left
self.Mirror(root.left)
self.Mirror(root.right)
return root
2.18 顺时针打印矩阵
问题:

def printMatrix(matrix):
res = []
while matrix:
res += matrix.pop(0) #将matrix[0][:]即第一行pop出来,放入res中,此时matrix(3*4)
if matrix and matrix[0]: #matrix[:][-1]即最后一列pop出来,接着放入res中,此时matrix(3*3)
for row in matrix:
res.append(row.pop())
if matrix:
res += matrix.pop()[::-1] #将matrix最后一行pop出来,列表[::-1]倒叙读数,此时matrix(2*3)
if matrix and matrix[0]: #matrix[:][0]即第一列pop出来,倒叙接着放入res中,此时matrix(2*2)
for row in matrix[::-1]:
res.append(row.pop(0))
return res
2.19 包含min函数的栈
思路:设置一个变量存放最小值,每一次压栈的时候进行比较。再设置一个辅助栈,用于存放当前栈的最小值(设置辅助栈是因为,若最小值出栈了,最小值需要进行更新,因此需要辅助栈来保存次小值)
class Solution:
def __init__(self):
self.stack = []
self.minstack = []
self.minm = float('inf')
def push(self, node): #push和pop都不用return,属于自操作
if node < self.minm:
self.minm = node
self.minstack.append(self.minm)
self.stack.append(node)
def pop(self):
if self.stack != []:
if self.stack[-1] == self.minm:
self.minstack.pop()
self.stack.pop(-1)
def top(self):
if self.stack != []:
return self.stack[-1]
else:
return None
def min(self):
return self.minstack[-1]
2.20栈的压入弹出序列
思路:用一个栈和一个队列来模拟,如果栈顶和队列头部元素相同,同时pop掉,若最后栈是空的代表对
def IsPopOrder(self, pushV, popV):
stack= [] #定义一个栈
while popV:
if stack and stack[-1] == popV[0]: #popV好比一个队列,与栈顶相同则pop
popV.pop(0)
stack.pop()
elif pushV: #模拟入栈,与上面的顺序不能乱
stack.append(pushV.pop(0))
else:
return False
return True
2.21 从上往下打印二叉树
问题:从上往下打印出二叉树的每个节点,同层节点从左至右打印。
思路:用队列,每次放节点时,把他的左右子树也放到尾部
def PrintFromTopToBottom(self, root):
result = []
queue = []
if root == None:
return result
queue.append(root) #储存的是节点而不是数值
while queue:
tmp = queue.pop(0)
result.append(tmp.val)
if tmp.left:
queue.append(tmp.left)
if tmp.right:
queue.append(tmp.right)
return result
2.22 二叉搜索树的后序遍历结果
思路:二叉排序树按照“左-右-根”的顺序遍历得到的序列具有这样的特点:该序列从中间分开,左边序列的值都小于序列的最后一个值,右边序列的值都大于序列的最后一个值。很明显,序列的最后一个值就是根节点,而这个分界点就是左右子树的分界点,因此,我们按顺序遍历这个序列,找到第一个大于根节点的值,就区分出了左右子树,同时,如果这个点左边的值大于根节点的值或者该点右边的值小于根节点的值,则说明此序列不符合要求,如果符合要求,则继续对左右子树按照上面的过程进行判断,明显这是个需要用递归解决的问题。
#法一:循环 *****
def VerifySquenceOfBST(sequence):
if len(sequence) == 0:
return False
length = len(sequence) - 1
i = 0
while length != 0:
while sequence[i] < sequence[length]:
i += 1
while sequence[i] > sequence[length]:
i += 1
if i < length:
return False
length -= 1
i = 0
return True
#法二:递归
class Solution:
#判断序列是否是二叉排序树的后续遍历序列
def VerifySquenceOfBST(self, sequence):
if len(sequence)==0:
return False
if len(sequence)==1:
return True
root=sequence[-1]#根节点的值
border=len(sequence)-1#必须初始化边界点的值,因为有可能没有右子树,就无法按照第一个大于root的方法找到border
for i in range(len(sequence)-1): #找出左右子树的分界处
if sequence[i]>root:
border=i
break
for i in range(len(sequence)-1): #判断左右子树是否都满足条件---边界点左边的值小于root,右边的值大于root
if sequence[i]<root and i>border:
return False
if sequence[i]>root and i<border:
return False
if border==len(sequence)-1 or border==0:#没有左子树或没有右子树
return self.VerifySquenceOfBST(sequence[:-1])
else:
return (self.VerifySquenceOfBST(sequence[:border]) and self.VerifySquenceOfBST(sequence[border:len(sequence)-1]))
2.23 二叉树中和为某一值的路径
思路:
首先要理解题意,是从根节点往子节点连。如果只有根节点或者找到叶子节点,我们就把其对应的val值返回如果不是叶子节点,我们分别对根节点的左子树、右子树进行递归,直到找到叶子结点。然后遍历把叶子结点和父节点对应的val组成的序列返回上一层;如果没找到路径,其实也返回了序列,只不过是[]。
def FindPath(self, root, expectNumber):
if not root:
return []
if root and not root.left and not root.right and root.val==expectNumber: #没有左右节点,且此节点值为目标值
return [[root.val]]
res = []
left = self.FindPath(root.left,expectNumber-root.val)
right = self.FindPath(root.right,expectNumber-root.val)
for i in left+right:
res.append([root.val]+i) #递归时减去的当前节点值此时要加上
return res
2.24 复杂链表的复制
思路2:将原链表和新链表各节点地址做字典存储下来。
# class RandomListNode:
# def __init__(self, x):
# self.label = x
# self.next = None
# self.random = None
#法一:
def Clone( head):
if not head: return
newNode = RandomListNode(head.label)
newNode.random = head.random
newNode.next = self.Clone(head.next)
return newNode
#法二:
def Clone(pHead):
newhead = RandomListNode(0)
dic = {}
temp = pHead
new = newhead # 这两个变量的目的在于:newhead,pHead遍历到尾部节点时,这两个指针还在头节点,又等价于newhead,pHead(因为浅拷贝)
while pHead: #步骤1-----正序节点赋值
newhead.next = RandomListNode(pHead.label)
dic[pHead] = newhead.next # 之所以是next,是因为newhead初始化是头节点为0
pHead = pHead.next
newhead = newhead.next
new = new.next
n = new # 同定义newhead,pHead的目的一样,备份表头
while temp: # 步骤2----随机节点复制
if temp.random:
new.random = dic[temp.random]
temp = temp.next
new = new.next
return n
2.25 二叉搜索树与双向链表
思路:二叉搜索树是有序的,只要中序遍历,就是一个从小到大有序的序列。
1).双向链表表头一定是最左的节点
2). 表尾不断以中序遍历方式向右移动:
class Solution:
def __init__(self):
self.listHead = None #头节点备份
self.listTail = None #搜索二叉树变成双向链表,指针遍历
def Convert(self, pRootOfTree):
if pRootOfTree==None: #递归终止条件
return
self.Convert(pRootOfTree.left) #中序遍历是顺序序列
if self.listHead==None: #初始化链表头节点
self.listHead = pRootOfTree
self.listTail = pRootOfTree
else:
self.listTail.right = pRootOfTree #搜索二叉树变成双向链表
pRootOfTree.left = self.listTail
self.listTail = pRootOfTree
self.Convert(pRootOfTree.right)
return self.listHead
2.26 字符串的排序 (思路有些绕)
思路:递归法,问题转换为先固定第一个字符(首位可能是a/b/c),求剩余字符的排列;求剩余字符排列时跟原问题一样。
(1) 遍历出所有可能出现在第一个位置的字符(即:依次将第一个字符同后面所有字符交换);
(2) 固定第一个字符,求后面字符的排列(即:在第1步的遍历过程中,插入递归进行实现)。
class Solution:
def Permutation(self, ss):
if len(ss) <=0:
return []
res = list() #创建一个空列表,res = []
self.perm(ss,res,'')
uniq = list(set(res))
return sorted(uniq)
def perm(self,ss,res,path):
if ss=='': #临界条件
res.append(path)
else:
for i in range(len(ss)):
#print(ss[:i] + ss[i + 1:], res, path + ss[i])
self.perm(ss[:i]+ss[i+1:],res,path+ss[i]) #********核心思想!!!
#训练过程:
"""
bc [] a i=0 因为传入的ss在变,所以里面还有小递归
c [] ab
[] abc
b ['abc'] ac
['abc'] acb
ac ['abc', 'acb'] b i=1
c ['abc', 'acb'] ba
['abc', 'acb'] bac
a ['abc', 'acb', 'bac'] bc
['abc', 'acb', 'bac'] bca
ab ['abc', 'acb', 'bac', 'bca'] c i=2
b ['abc', 'acb', 'bac', 'bca'] ca
['abc', 'acb', 'bac', 'bca'] cab
a ['abc', 'acb', 'bac', 'bca', 'cab'] cb
['abc', 'acb', 'bac', 'bca', 'cab'] cba
"""
2.27 数组中出现次数超过一半的数字
思路1:排序之后,中间的数就是答案,但是时间复杂度是 nlogn
思路2 :时间复杂度n的方法:初始化一个count ,flag设置为数组第一个,如果碰到相同的+1,否则-1,当减到0时候更换result为当前的,count归为1,最后记得验证一下。(原理–如果元素次数大于数组一半时,相同加1到最后的计数必然大于0)
def MoreThanHalfNum_Solution( numbers):
flag = numbers[0]
count = 1
if len(numbers) == 0:
return 0
for i in range(1,len(numbers)):
if numbers[i] == flag:
count +=1
else:
count -=1
if count < 0:
count = 1
flag = numbers[i]
#上述结果可能不对,需要验证次数是否超过数组长度的一半
count = 0
for num in numbers:
if num==flag:
count +=1
if count>len(numbers)//2:
return flag
else:
return 0
2.28 最小的K个数
利用堆排序,适合处理TOP-K问题
(1)遍历输入数组,将前k个数插入到推中(定义为最大堆);(利用heapq模块来做为堆的实现)
(2)继续从输入数组中读入元素做为待插入整数,并将它与堆中最大值(堆顶的值)比较:
如果待插入的值比当前已有的最大值小,则用这个数替换当前已有的最大值;
如果待插入的值比当前已有的最大值还大,则抛弃这个数,继续读下一个数。
这样动态维护堆中这k个数,以保证它只储存输入数组中的前k个最小的数,最后输出堆即可。这种方法只需要开辟一个长度为k的空间,大大节省了空间的消耗
import heapq # 利用python的heapq模块,来实现堆的操作
class Solution:
def GetLeastNumbers_Solution(self, tinput, k):
# write code here
maxheap = []
if k <= 0 or tinput == None or len(tinput)<k:
return []
for i in range(k):
heapq.heappush(maxheap,-tinput[i]) #python自带的heapq模块实现的是最小堆,没有提供最大堆的实现,所以取反为负值
for i in range(k,len(tinput)):
if maxheap[0]> -tinput[i]:
continue
else:
heapq.heappushpop(maxheap,-tinput[i]) #heappushpop(a,x)在弹出最小值之前将x推送到a上
result = []
for i in range(k):
result.insert(0,-heapq.heappop(maxheap)) #一个个弹出堆顶端元素,并保存到列表中
return result
2.29 连续子数组的最大和
思想:动态规划
def FindGreatestSumOfSubArray(array):
dp = [array[0]] #初始化第一个位置
for i in range(1, len(array)):
dp.append(max(dp[i-1] + array[i] , array[i]))
return max(dp)
2.30 整数中1出现的次数
def NumberOf1Between1AndN_Solution(self, n):
count = 0
for i in range(n+1):
s = str(i)
if "1" in s:
count += s.count("1")
return count
2.31 把数组排成最小的数
python2专用的用cmp
def PrintMinNumber(self, numbers):
if not numbers:
return ""
lmb = lambda n1, n2:int(str(n1)+str(n2))-int(str(n2)+str(n1))
array = sorted(numbers, cmp=lmb) #python2专用,用cmp
return ''.join([str(i) for i in array])
2.32 丑数
思路:
首先从丑数的定义我们知道,一个丑数的因子只有2,3,5,那么丑数p = 2 ^ x * 3 ^ y * 5 ^ z,换句话说一个丑数一定由另一个丑数乘以2或者乘以3或者乘以5得到,那么我们从1开始乘以2,3,5,就得到2,3,5三个丑数,在从这三个丑数出发乘以2,3,5就得到4,6,10,6,9,15,10,15,25九个丑数,我们发现这种方法会得到重复的丑数,而且我们题目要求第N个丑数,这样的方法得到的丑数也是无序的。那么我们可以维护三个队列:
def GetUglyNumber_Solution( index):
if (index <= 0):
return 0
uglyList = [1] # 丑数列表
indexTwo = 0 #维护三个队列,这是其位置
indexThree = 0
indexFive = 0
for i in range(index - 1):
newUgly = min(uglyList[indexTwo] * 2, uglyList[indexThree] * 3, uglyList[indexFive] * 5)
uglyList.append(newUgly)
if (newUgly % 2 == 0): #丑数列表添加谁的倍数,把谁的index后移。
indexTwo += 1
if (newUgly % 3 == 0):
indexThree += 1
if (newUgly % 5 == 0):
indexFive += 1
return uglyList[-1]
2.33 第一次只出现一次的字符串
def FirstNotRepeatingChar(s):
if not s:
return -1
for i,ch in enumerate(s):
if s.count(ch)==1:
return i
2.34 数组中的逆序对
思想:归并排序
2.35 两个链表的公共节点
def FindFirstCommonNode(pHead1, pHead2):
list1 = [] #用列表储存链表1的数值
node1 = pHead1
node2 = pHead2
while node1:
list1.append(node1.val)
node1 = node1.next
while node2:
if node2.val in list1:
return node2
else:
node2 = node2.next
2.36 数字在排列数组中出现的次数
def GetNumberOfK(data, k):
return data.count(k)
2.37 二叉树的深度
# -*- coding:utf-8 -*-
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def TreeDepth(self, pRoot):
if pRoot == None:
return 0
lDepth = self.TreeDepth(pRoot.left)
rDepth = self.TreeDepth(pRoot.right)
return max(lDepth,rDepth)+1
2.38 平衡二叉树