malloc原理学习:隐式空闲链表
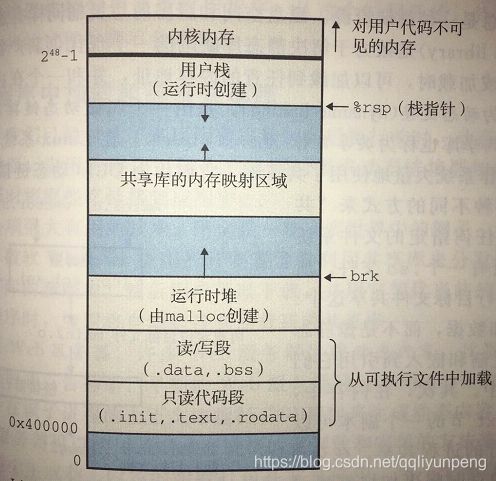
1. 堆在内存中的位置:
两张图可以看出,堆所在的位置是在bss段后边,生长也是向上生长的。

2. 隐式空闲链表的方式简介:
这是种简单方法,但是因为块分配和堆块的总数呈线性关系,所以对于通用的分配器,隐式空闲链表是不合适的。也就是说对于堆块数量预先就知道很小的特殊的分配器是可用的。。
隐式空闲链表有个恒定的形式:

3. 代码实现:
1)初始化和基本的宏
code/vm/malloc/memlib.c
static char *mem_heap; // 堆开始的地址
static char *mem_brk; // 指向用户空间使用了的空间地址加1
static char *mem_max_addr; // 最大逻辑堆的地址加1
/*
* 初始化
*/
void mem_init(void) {
mem_heap = (char *)Malloc(MAX_HEAP);
mem_brk = (char *))mem_heap;
mem_max_addr = (char *)(mem_heap + MAX_HEAP);
}
/*
* 扩展堆加 incr 字节并且返回新区域的开始地址,
* 这个模块堆不能收缩
* mem_brk += incr;
*/
void *mem_sbrk(int incr) {
char *old_brk = mem_brk;
if ( (incr < 0) || ((mem_brk+incr) > mem_max_addr) ) {
errno = ENOMEM;
fprintf(stderr, "ERROR: mem_sbrk failed. Ran out of memory...\n");
return (void *)-1;
}
mem_brk += incr;
return (void *)old_brk;
}code/vm/malloc/mm.c
#define WSIZE 4 /* 字或者说头或者尾的大小(单位字节) */
#define DSIZE 8
#define CHUNKSIZE (1<<12) /* 扩展堆 4096 个字节 */
#define MAX(x, y) ((x) > (y)? (x) : (y))
/* Pack a size and allocated bit into a word */
#define PACK(size, alloc) ((size) |(alloc))
/* Read and write a word at address p */
#define GET(p) (*(unsigned int *)(p))
#define PUT(p, val) (*(unsigned int *)(p) = (val))
/* Read the size and allocated fields from address p */
#define GET_SIZE(p) (GET(p) & ~0x7)
#define GET_ALLOC(p) GET(p) & 0x1)
/* Given block ptr bp, compute address of its header and footer */
#define HDRP(bp) ((char *)(bp) - WSIZE)
#define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* Given block ptr bp, compute address of next and previous blocks */
#define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp) - WSIZE)))
#define PREV_BLKP(bp) ((char *)(bp) - GET_SIZE(((char *)(bp) - DSIZE)))
GET_SIZE 是得到的整个区域的大小
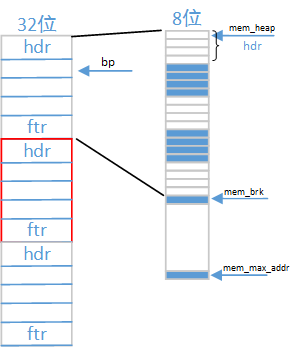
假设块的大小是 5 个块(每个块的大小是32位,4字节)
可以看到 bp 均是指向有效区间的指针,
其中 NEXT_BLKP 和 PREV_BLKP 得到的也是有效区域的指针。
code/vm/malloc/mm.c
int mm_init(void) {
/* Create the initial empty heap */
/* 1. 创建一个空的空闲链表 */
if (heap_listp = mem_sbrk(4*WSIZE)) == (void *)-1) // heap_listp = (mem_brk += 16); 16字节,
return -1;
PUT(heap_listp, 0); // *(unsigned int *)heap_listp = 0
PUT(heap_listp + (1*WSIZE), PACK(DSIZE, 1)); // *(heap_listp+4) = PACK(8, 1)
PUT(heap_listp + (2*WSIZE), PACK(DSIZE, 1)); // *(heap_listp+8) = PACK(8, 1)
PUT(heap_listp + (3*WSIZE), PACK(0, 1)); // *(heap_listp+12) = PACK(0, 1)
heap_listp += (2*WSIZE); // heap_listp += 8,heap_listp 是 char *
/* 扩展4096字节空间 */
/* Extend the empty heap with a free block of CHUNKSIZE bytes */
if (extend_heap(CHUNKSIZE/WSIZE) == NULL)
return -1;
return 0;
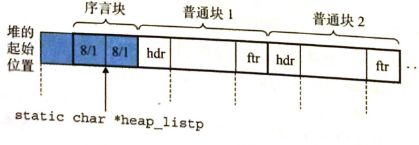
}理解上边的代码需要知道的:
一个指针指向的区域存储的数据是一个字节的数据,因此第二个PUT需要加4,用4个地址位置保存一个地址(32位地址)信息。
上边函数的目的是构建如下的序言块

上图中一个小块代表 4个字节/1个字/32位
参照开头说的恒定的格式
code/vm/malloc/mm.c
static void *extend_heap(size_t words) { // 以4字节为单位
char *bp;
size_t size; // 单位 字节
/* Allocate an even(偶数) number of words to maintain alignment */
size = (words % 2) ? (words+1) * WSIZE : words * WSIZE; // 维持偶数块
if ((long)(bp = mem_sbrk(size)) == -1)
return NULL;
/* Initialize free block header/footer and the epilogue header */
PUT(HDRP(bp), PACK(size, 0)); // 4096 字节的空间大小,包括头和尾
PUT(FTRP(bp), PACK(size, 0)); // ...
PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); // 结尾块
/* Coalesce if the previous block was free */
return coalesce(bp);
}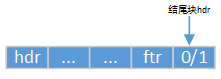
extend_heap 在两种情况下被调用:1)当堆被初始化时;2)当mm_malloc 不能找到一个合适的匹配块时。
mem_sbrk 的每次调用都返回一个双字对齐的内存片,紧跟在结尾块的头部后面,这个头部变成了新的空闲块的头部,并且这个片的最后一个字变成了新的结尾块的头部,最后,在很可能出现的前一个堆以一个空闲快结束的情况下,调用 coalesce 合并两个空闲块,并返回合并后块指针。
2)释放和合并块
code/vm/malloc/mm.c
void mm_free(void *bp)
{
size_t size = GET_SIZE(HDRP(bp));
PUT(HDRP(bp), PACK(size, 0)); // 变成空闲快
PUT(FTRP(bp), PACK(size, 0));
coalesce(bp);
}
static void *coalesce(void *bp)
{
size_t prev_alloc = GET_ALLOC(FTRP(PREV_BLKP(bp)));
size_t next_alloc = GET_ALLOC(HDRP(NEXT_BLKP(bp)));
SIZE_T size = GET_SIZE(HDRP(bp));
if (prev_alloc && next_alloc) {
return bp;
}
else if (prev_alloc && !next_alloc) {
size += GET_SIZE(HDRP(NEXT_BLKP(bp)));
PUT(HDRP(bp), PACK(size, 0));
PUT(FTRP(bp), PACK(size, 0));
}
else if (!prev_alloc && next_alloc) {
size += GET_SIZE(HDRP(PREV_BLKP(bp)));
PUT(FTRP(bp), PACK(size, 0));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
else {
size += GET_SIZE(HDRP(PREV_BLKP(bp))) +
GET_SIZE(FTRP(NEXT_BLKP(bp)));
PUT(HDRP(PREV_BLKP(bp)), PACK(size, 0));
PUT(FTRP(NEXT_BLKP(bp)), PACK(size, 0));
bp = PREV_BLKP(bp);
}
return bp;
}coalesce 合并的情况
情况1 前面的块和后边的块都是已分配的。
情况2 前面的块是已分配的,后面的块是空闲的。
情况3 前面的块是空闲的,而后边的块是已分配的。
情况4 前面的和后面的块都是空闲的。
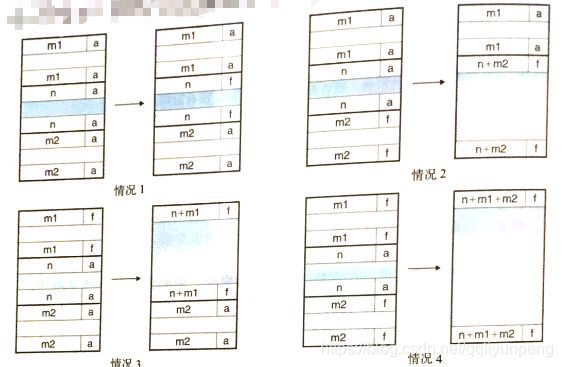
在coalesce函数中有个微妙的方面。我们的空闲链表的格式(序言块和结尾块总是标记为已分配)允许我们忽略潜在的麻烦边界情况。
3)分配快
一个应用通过调用 mm_malloc 函数来向内存请求大小为 size 字节的块,分配器需要调整请求块的大小。从而为头部和尾部留有空间,并满足双字节的要求。
code/vm/malloc/mm.c
void *mm_malloc(size_t size)
{
size_t asize; // 调整块的大小,要为头和尾留有空间
size_t extendsize; // 堆中如果没有合适的块,需要扩展的扩展的块的大小
char *bp;
if(size == 0)
reutrn NULL;
if (size <=DSIZE)
asize = 2*DSIZE; // 最小块大小16字节(头+尾=8字节,另外8字节对齐要求,包括了size的大小)
else
asize = DSIZE * ((size + (DSIZE) +(DSIZE-1)) / DSIZE); // 向上舍入最接近的8的整倍数
if((bp = find_fit(asize)) != NULL) { // 搜索空闲快,找到合适的空闲块
place(bp, asize); // 分割出多余部分
return bp; // 返回新分配的地址
}
/* 如果没有找到,需要扩展,最小扩展4096字节 */
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize/WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}上面代码是从空闲链表中分配一个块
find_fit() 和 place() 先不提供,隐式空闲链表就先介绍到这里。