《数据结构与算法之美》21~25笔记
文章目录
- 关于我的仓库
- 前言
- 21讲哈希算法(上):如何防止数据库中的用户信息被脱库
- 哈希算法
- MD5初识
- 哈希算法七应用【前四】
- 应用一:安全加密
- 应用二:唯一标识
- 应用三:数据校验
- 应用四:散列函数
- 解答开篇:守护最好的用户数据库
- 课后题:现在,区块链是一个很火的领域,它被很多人神秘化,不过其底层的实现原理并不复杂。其中,哈希算法就是它的一个非常重要的理论基础。你能讲一讲区块链使用的是哪种哈希算法吗?是为了解决什么问题而使用的呢?
- 22讲哈希算法(下):哈希算法在分布式系统中有哪些应用
- 哈希算法七应用【后三】
- 应用五:负载均衡
- 应用六:数据分片
- 如何统计“搜索关键词”出现的次数?
- 如何快速判断图片是否在图库中?
- 应用七:分布式存储
- 23讲二叉树基础(上):什么样的二叉树适合用数组来存储
- 基础概念
- 疑点
- 二叉树(Binary Tree)
- 二叉树的遍历
- 课后题
- 给定一组数据,比如1,3,5,6,9,10。你来算算,可以构建出多少种不同的二叉树?
- 我们讲了三种二叉树的遍历方式,前、中、后序。实际上,还有另外一种遍历方式,也就是按层遍历,你知道如何实现吗?
- 24讲二叉树基础(下):有了如此高效的散列表,为什么还需要二叉树
- 二叉查找树(Binary Search Tree)
- 二叉查找树的查找操作
- 二叉查找树的插入操作
- 二叉查找树的删除操作
- 二叉查找树的其他操作
- 支持重复数据的二叉查找树
- 二叉查找树的时间复杂度分析
- 解答开篇:二叉树相对于散列表优势所在
- 课后题:如何通过编程,求出一棵给定二叉树的确切高度呢?
- 25讲红黑树(上):为什么工程中都用红黑树这种二叉树
- 平衡二叉查找树
- 定义一棵“红黑树”
- 红黑树->静态平衡?
- 解答开篇:为什么都喜欢使用红黑树,而不是其他平衡二叉查找树呢?
- 课后思考:动态数据结构支持动态地数据插入、删除、查找操作,除了红黑树,我们前面还学习过哪些呢?能对比一下各自的优势、劣势,以及应用场景吗?
关于我的仓库
- 这篇文章是我为面试准备的学习总结中的一篇
- 我将准备面试中找到的所有学习资料,写的Demo,写的博客都放在了这个仓库里iOS-Engineer-Interview
- 欢迎star??
- 其中的博客在简书,CSDN都有发布
- 博客中提到的相关的代码Demo可以在仓库里相应的文件夹里找到
前言
- 该系列为学习《数据结构与算法之美》的系列学习笔记
- 总结规律为一周一更,内容包括其中的重要知识带你,以及课后题的解答
- 算法的学习学与刷题并进,希望能真正养成解算法题的思维
- LeetCode刷题仓库:LeetCode-All-In
- 多说无益,你应该开始打代码了
21讲哈希算法(上):如何防止数据库中的用户信息被脱库
- 哦,开局就是上古秘辛,2011年CSDN还是用明文保存的账户密码,这也忒靠谱了
- 幸好那个时候还不知道CSDN是个虾米玩意呢
哈希算法
- 从哈希值不能反向推导出原始数据(所以哈希算法也叫单向哈希算法)
- 对输入数据非常敏感,哪怕原始数据只修改了一个Bit,最后得到的哈希值也大不相同
- 散列冲突的概率要很小,对于不同的原始数据,哈希值相同的概率非常小
- 哈希算法的执行效率要尽量高效,针对较长的文本,也能快速地计算出哈希值
MD5初识
- 之前在写网络下载的时候就大概了解过这个算法,这里正好讲到了,我就多查了点资料看了下
- 首先MD5被称之为不可逆算法,无法从哈希值逆推出原始数据,为什么MD5源码开放的情况下我们会无法逆推呢?因为在哈希过程中,我们不会去刻意保存原数据
- 比如我们进行了>>操作,将一个二进制数右移了两位,这样子必然会丢失掉最左边的两位,在这样的情况下就算我们有源码知道它进行了右移操作,进行左移,也无法得到原来的那两位,也就无法推倒到原来的数据【这只是一个很简单的例子】
- 所以对于这样的单向哈希算法,我们在意的只是加密这一过程,因此很多人说MD5不能算加密算法,因为加密会包括加密和解密,而MD5只管杀,不管埋,跟多的是视作一个生成数字签名的算法,从这个角度可能会更好理解这一部分
- 而我查到的资料提到2004年山东大学一位教授已经破译MD5,是说能够加快碰撞,就是说假如A哈希完结果是B,我现在能找到一个C哈希完也是B,加快了碰撞
- MD5“解密”过程正确来说不应该叫做“解密”,应该叫做MD5碰撞算法,只是拿到一个原始值再做一次MD5算法,看得到的的MD5值和你之前的MD5是不是一致,如果一致,我们就大体认为是原始值一致。为什么说大体呢?老师也说过了,会有HASH碰撞,可能不一样的原始值长生一样的HASH值,概率为1/2^128
哈希算法七应用【前四】
应用一:安全加密
- 加密哈希算法举例:MD5(MD5 Message-Digest Algorithm,MD5消息摘要算法)、SHA(Secure Hash Algorithm,安全散列算法)、 DES(Data Encryption Standard,数据加密标准)、AES(Advanced Encryption Standard,高级加密标准)
- 加密哈希算法的两个特点:
- 第一点是很难根据哈希值反向推导出原始数据
- 第二点是散列冲突的概率要很小
- 首先散列冲突一定会出现,这基于鸽巢原理【如果有10个鸽巢,有11只鸽子,那肯定有1个鸽巢中的鸽子数量多于1个,换句话说就是,肯定有2只鸽子在1个鸽巢内】
- 而以MD5举例,其哈希值是固定的128位二进制串,最多只有2^128个数据,而我们要哈希的数据是无限的
- 所有的安全措施,只是增加攻击的成本而已
应用二:唯一标识
- 这里假如我们要在图库里搜索一张图片是否存在,我们知道所有图片的本质是二进制,如果我们是根据二进制码一个一个对照搜索显然十分耗时【图片大的会有数MB,会很大】
- 我们可以给每一个图片取一个唯一标识,或者说信息摘要。比如,我们可以从图片的二进制码串开头取100个字节,从中间取100个字节,从最后再取100个字节,然后将这300个字节放到一块,通过哈希算法(比如MD5),得到一个哈希字符串,用它作为图片的唯一标识。通过这个唯一标识来判定图片是否在图库中,这样就可以减少很多工作量
- 如果还想继续提高效率,我们可以把每个图片的唯一标识,和相应的图片文件在图库中的路径信息,都存储在散列表中。当要查看某个图片是不是在图库中的时候,我们先通过哈希算法对这个图片取唯一标识,然后在散列表中查找是否存在这个唯一标识
应用三:数据校验
- BT下载的原理是基于P2P协议的。我们从多个机器上并行下载一个2GB的电影,这个电影文件可能会被分割成很多文件块(比如可以分成100块,每块大约20MB)。等所有的文件块都下载完成之后,再组装成一个完整的电影文件就行了
- 这样就会存在,在某台机器上的资源看你是被恶意修改过的,或者是在下载过程中出现过问题,导致其文件块是不完整的
- 我们通过哈希算法,对100个文件块分别取哈希值,并且保存在种子文件中。我们在前面讲过,哈希算法有一个特点,对数据很敏感。只要文件块的内容有一丁点儿的改变,最后计算出的哈希值就会完全不同。所以,当文件块下载完成之后,我们可以通过相同的哈希算法,对下载好的文件块逐一求哈希值,然后跟种子文件中保存的哈希值比对。如果不同,说明这个文件块不完整或者被篡改了,需要再重新从其他宿主机器上下载这个文件块
- 有趣啊,我感觉计算机最有意思的地方就是很多东西完全不是你空想能想到的,想这个数据校验会出现的情况就那么复杂
应用四:散列函数
- 散列函数是设计一个散列表的关键。它直接决定了散列冲突的概率和散列表的性能。不过,相对哈希算法的其他应用,散列函数对于散列算法冲突的要求要低很多。即便出现个别散列冲突,只要不是过于严重,我们都可以通过开放寻址法或者链表法解决
- 散列函数对于散列算法计算得到的值,是否能反向解密也并不关心。散列函数中用到的散列算法,更加关注散列后的值是否能平均分布,也就是,一组数据是否能均匀地散列在各个槽中。除此之外,散列函数执行的快慢,也会影响散列表的性能,所以,散列函数用的散列算法一般都比较简单,比较追求效率
解答开篇:守护最好的用户数据库
- 选择相对安全的加密算法
- 引入一个盐(salt),跟用户的密码组合在一起,增加密码的复杂度。我们拿组合之后的字符串来做哈希算法加密,将它存储到数据库中,进一步增加破解的难度
- 现在大多公司都采用无论密码长度多少,计算字符串hash时间都固定或者足够慢的算法如PBKDF2WithHmacSHA1,来降低硬件计算hash速度,减少不同长度字符串计算hash所需时间不一样而泄漏字符串长度信息,进一步减少风险
课后题:现在,区块链是一个很火的领域,它被很多人神秘化,不过其底层的实现原理并不复杂。其中,哈希算法就是它的一个非常重要的理论基础。你能讲一讲区块链使用的是哪种哈希算法吗?是为了解决什么问题而使用的呢?
- 区块链是一块块区块组成的,每个区块分为两部分:区块头和区块体。
- 区块头保存着 自己区块体 和 上一个区块头 的哈希值。
- 因为这种链式关系和哈希值的唯一性,只要区块链上任意一个区块被修改过,后面所有区块保存的哈希值就不对了。
- 区块链使用的是 SHA256 哈希算法,计算哈希值非常耗时,如果要篡改一个区块,就必须重新计算该区块后面所有的区块的哈希值,短时间内几乎不可能做到。
22讲哈希算法(下):哈希算法在分布式系统中有哪些应用
哈希算法七应用【后三】
- 个人认为这三点基本上都是一个东西本质上
- 就是说,怎么追求极致的均衡,方便扩容,缩容
- 所以思想都一样,注意下应用的场景吧,话说,我觉得这个网课真没白学,是挺有意思的,有一种世界开阔了的感觉
应用五:负载均衡
- 实现一个会话粘滞(session sticky)的负载均衡算法,我们需要在同一个客户端上,在一次会话中的所有请求都路由到同一个服务器上
- 。我们可以通过哈希算法,对客户端IP地址或者会话ID计算哈希值,将取得的哈希值与服务器列表的大小进行取模运算,最终得到的值就是应该被路由到的服务器编号。 这样,我们就可以把同一个IP过来的所有请求,都路由到同一个后端服务器上
应用六:数据分片
- 这个很像sideTables和sideTable的设计思想,面试的时候可以提一下,我觉得会高端很多,哈希真的运用很广泛,很有意思
如何统计“搜索关键词”出现的次数?
- 假如我们有1T的日志文件,这里面记录了用户的搜索关键词,我们想要快速统计出每个关键词被搜索的次数
- 难点有两个,第一个是搜索日志很大,没办法放到一台机器的内存中。第二个难点是,如果只用一台机器来处理这么巨大的数据,处理时间会很长
- 针对方法就是先对数据分片,采用多台机器处理的方法,提高处理速度
- 为了提高处理的速度,我们用n台机器并行处理。我们从搜索记录的日志文件中,依次读出每个搜索关键词,并且通过哈希函数计算哈希值,然后再跟n取模,最终得到的值,就是应该被分配到的机器编号
- 这样能保证的是哈希值相同的机器会被分配到同一台机器
如何快速判断图片是否在图库中?
- 假设我们的图库里面有上亿张图片,我们将无法简单的在一台机器上进行构建散列表
- 我们每次从图库中读取一个图片,计算唯一标识,然后与机器个数n求余取模,得到的值就对应要分配的机器编号,然后将这个图片的唯一标识和图片路径发往对应的机器构建散列表
- 当我们要判断一个图片是否在图库中的时候,我们通过同样的哈希算法,计算这个图片的唯一标识,然后与机器个数n求余取模。假设得到的值是k,那就去编号k的机器构建的散列表中查找
应用七:分布式存储
- 参考百话解析:一致性哈希算法 consistent hashing
- 假设我们有三台机器,将其哈希值对2的32次取余,投射到环上

- 这样的好处在于:我们不用修改我们的哈希算法,不会出现同一个文件会被先后放到不同的服务器上
- 因为在这样的背景下,增加/去除服务器,只会影响到很小一部分的服务器,不会影响到所有人

- 同时,我们还会引入虚拟节点的概念,因为我们在环上的节点不一定均匀,有可能会导致某个服务器运作量大增

- 真他娘的妙,这也许就是传说中的美丽的算法吧
23讲二叉树基础(上):什么样的二叉树适合用数组来存储
- 终于到树的章节了,冲冲冲
基础概念
- 基本课上都讲过,滑一滑

- A节点就是B节点的父节点,B节点是A节点的子节点。B、C、D这三个节点的父节点是同一个节点,所以它们之间互称为兄弟节点。我们把没有父节点的节点叫作根节点,也就是图中的节点E。我们把没有子节点的节点叫作叶子节点或者叶节点,比如图中的G、H、I、J、K、L都是叶子节点
- 分清楚高度 深度 叶子结点之类的问题是比较重要的

- 可以这么记:高度就是数有几楼,数的时候肯定是从下往上数的,所以根结点高度最高;深度就是从地平线往下数的,所以根结点会是0
疑点
- 这里有一个地方很奇怪在于对于树的高度存在两种说法,在这里做一下摘录
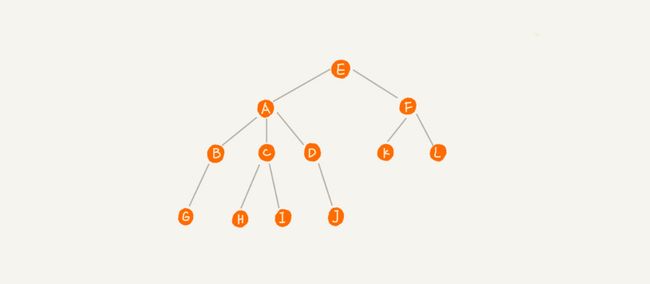
- 根据《数据结构与算法(王曙燕主编,人民邮电出版社出版)》,高度就是树的深度,为所有节点层次的最大值,也就是说对于上图,树的高度为4
- 而根据网课的说法,树的高度是经过路径最大值,也就是说是三
- 这个的区别就在于只有一个节点的时候,将其视作是高度0还是1
- 这两种观点据我搜索,确实都有,那么先按照王老师的观点来写吧
二叉树(Binary Tree)
-
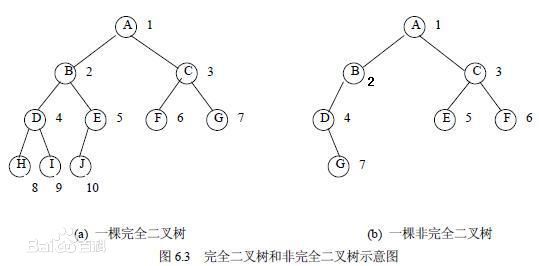
二叉树主要分清楚完全二叉树和满二叉树
-
满二叉树是完全二叉树的一种
-
全二叉树是由满二叉树而引出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树
-
特点:叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大

- 完全二叉树的定义来源于数组存储的顺序存储法,把根节点存储在下标i = 1的位置
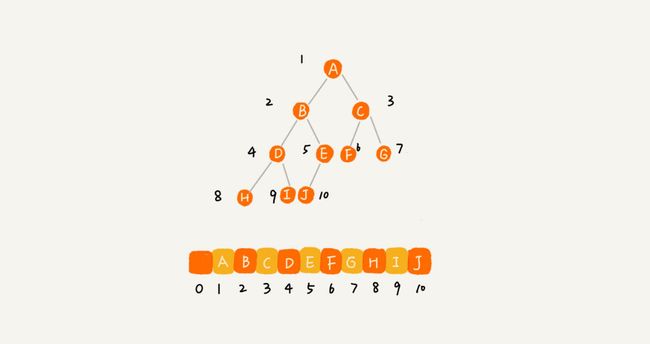
- 这样也就是完全按照编号作为数组下标去存储

- 我们不能简单的对二叉树进行存储,必须要在遵循这样的规则的基础上去存储,标准很简单,就是能不能在这个数组的基础上重构出一棵二叉树
- 如果某棵二叉树是一棵完全二叉树,那用数组存储无疑是最节省内存的一种方式。因为数组的存储方式并不需要像链式存储法那样,要存储额外的左右子节点的指针。这也是为什么完全二叉树会单独拎出来的原因,也是为什么完全二叉树要求最后一层的子节点都靠左的原因
- 当我们讲到堆和堆排序的时候,你会发现,堆其实就是一种完全二叉树,最常用的存储方式就是数组
二叉树的遍历
- codeRunner启动,开始打代码!
#include
#include
#include
#include
#include
#define random(x) (rand()%x)
char words[15] = {'A', 'B', 'D', '#', 'G', '#', '#', '#', 'C', 'E', '#', '#', 'F', '#', '#'};
//char words[15] = {ABD#G###CE##F##};
int p = 0;
typedef struct BTNode {
int data;
struct BTNode *lChild;
struct BTNode *rChild;
}BTNode;
using namespace std;
// 工具:输出结点函数
void PrintBTNodeData(BTNode *root) {
if (root) {
cout << root -> data << endl;
}
}
// 先序创建二叉树
BTNode * CreateBiTree(BTNode *root) {
char ch = 0;
cout << "输入希望生成的二叉树结构:" << endl;
cin >> ch;
if (ch == '#') {
root = NULL;
} else {
root = (BTNode *)malloc(sizeof(BTNode));
root -> data = random(100);
cout << "生成随机数:" << root -> data << endl;
root -> lChild = CreateBiTree(root -> lChild);
root -> rChild = CreateBiTree(root -> rChild);
}
return root;
}
// 递归版先序遍历
void PreOrderInternally(BTNode *root) {
if (root == NULL) {
return;
}
PrintBTNodeData(root);
PreOrderInternally(root -> lChild);
PreOrderInternally(root -> rChild);
}
// 递归版中序遍历
void InOrderInternally(BTNode *root) {
if (root == NULL) {
return;
}
InOrderInternally(root -> lChild);
PrintBTNodeData(root);
InOrderInternally(root -> rChild);
}
// 递归版后序遍历
void PostOrderInternally(BTNode *root) {
if (root == NULL) {
return;
}
PostOrderInternally(root -> lChild);
PostOrderInternally(root -> rChild);
PrintBTNodeData(root);
}
// 借助队列的层次遍历
void LevelOrder(BTNode *root) {
if (root == NULL) {
return;
}
BTNode *p = root;
queue s;
s.push(p);
while (!s.empty()) {
p = s.front();
s.pop();
PrintBTNodeData(p);
if (p->lChild != NULL) {
s.push(p->lChild);
}
if (p->rChild != NULL) {
s.push(p->rChild);
}
}
}
// 非递归版先序遍历
void PreOrder(BTNode *root) {
BTNode *p = root;
stack st;
while (p != NULL || !st.empty()) {
while (p != NULL) {
PrintBTNodeData(p);
st.push(p);
p = p->lChild;
}
if (!st.empty()) {
p = st.top();
st.pop();
p = p -> rChild;
}
}
}
// 非递归版中序遍历
void InOrder(BTNode *root) {
BTNode *p = root;
stack st;
while (p != NULL || !st.empty()) {
while (p != NULL) {
st.push(p);
p = p->lChild;
}
if (!st.empty()) {
p = st.top();
PrintBTNodeData(p);
st.pop();
p = p -> rChild;
}
}
}
// 非递归版后序遍历
void PostOrder(BTNode *root) {
BTNode *p = root;
BTNode *q = NULL;
stack st;
while (p != NULL || !st.empty()) {
while (p != NULL) {
st.push(p);
p = p->lChild;
}
if (!st.empty()) {
p = st.top();
if (p->rChild == NULL || p->rChild == q) {
p = st.top();
st.pop();
PrintBTNodeData(p);
q = p;
p = NULL;
} else {
p = p->rChild;
}
}
}
}
int main(int argc, char *argv[]) {
srand((int)time(0));
BTNode *T;
T = CreateBiTree(T);
cout << "构造完成" << endl;
cout << "开始递归版先序遍历" << endl;
PreOrderInternally(T);
cout << "开始递归版中序遍历" << endl;
InOrderInternally(T);
cout << "开始递归版后序遍历" << endl;
PostOrderInternally(T);
cout << "开始层次遍历" << endl;
LevelOrder(T);
cout << "开始非递归版先序遍历" << endl;
PreOrder(T);
cout << "开始非递归版中序遍历" << endl;
InOrder(T);
cout << "开始非递归版后序遍历" << endl;
PostOrder(T);
cout << "end" << endl;
}
- CodeRunner退出,开始自闭!
课后题
给定一组数据,比如1,3,5,6,9,10。你来算算,可以构建出多少种不同的二叉树?
思想:递归+组合
当n=1时,只有1个根节点,则只能组成1种形态的二叉树,令n个节点可组成的二叉树数量表示为h(n), 则h(1)=1;
当n=2时,1个根节点固定,还有n-1个节点,可以作为左子树,也可以作为右子树, 即:h(2)=h(0)*h(1)+h(1)*h(0)=2,则能组成2种形态的二叉树。这里h(0)表示空,所以只能算一种形态,即h(0)=1;
当n=3时,1个根节点固定,还有n-1=2个节点,可以在左子树或右子树, 即:h(3)=h(0)*h(2)+h(1)*h(1)+h(2)*h(0)=5,则能组成5种形态的二叉树。
以此类推,当n>=2时,可组成的二叉树数量为h(n)=h(0)*h(n-1)+h(1)*h(n-2)+...+h(n-1)*h(0)种。
即符合Catalan数的定义,可直接利用通项公式得出结果。
递归式: h(n)=h(n-1)*(4*n-2)/(n+1);
该递推关系的解为: h(n)=C(2n,n)/(n+1) (n=1,2,3,...)
我们讲了三种二叉树的遍历方式,前、中、后序。实际上,还有另外一种遍历方式,也就是按层遍历,你知道如何实现吗?
- 代码有,其实就是借助队列实现
24讲二叉树基础(下):有了如此高效的散列表,为什么还需要二叉树
二叉查找树(Binary Search Tree)
- 二叉搜索树的定义要求很简单:二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值
- 几个搜索二叉树的例子:
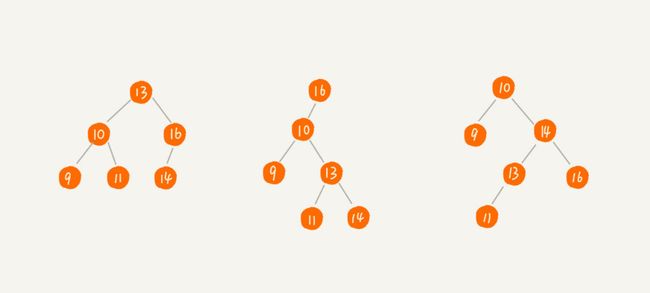
二叉查找树的查找操作
- 我们先取根节点,如果它等于我们要查找的数据,那就返回。如果要查找的数据比根节点的值小,那就在左子树中递归查找;如果要查找的数据比根节点的值大,那就在右子树中递归查找
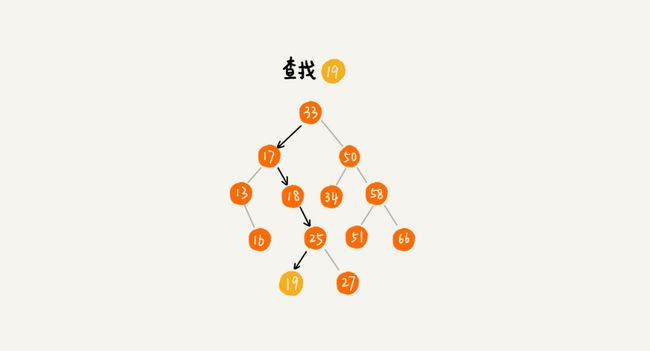
二叉查找树的插入操作
- 如果要插入的数据比节点的数据大,并且节点的右子树为空,就将新数据直接插到右子节点的位置;如果不为空,就再递归遍历右子树,查找插入位置。同理,如果要插入的数据比节点数值小,并且节点的左子树为空,就将新数据插入到左子节点的位置;如果不为空,就再递归遍历左子树,查找插入位置
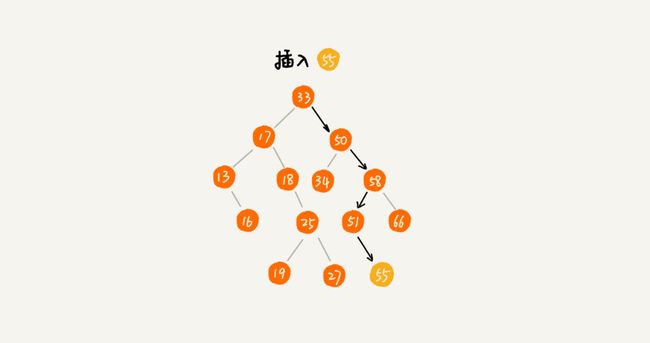
二叉查找树的删除操作
- 第一种情况是,如果要删除的节点没有子节点,我们只需要直接将父节点中,指向要删除节点的指针置为null。比如图中的删除节点55
- 第二种情况是,如果要删除的节点只有一个子节点(只有左子节点或者右子节点),我们只需要更新父节点中,指向要删除节点的指针,让它指向要删除节点的子节点就可以了。比如图中的删除节点13
- 第三种情况是,如果要删除的节点有两个子节点,这就比较复杂了。我们需要找到这个节点的右子树中的最小节点,把它替换到要删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了),所以,我们可以应用上面两条规则来删除这个最小节点。比如图中的删除节点18
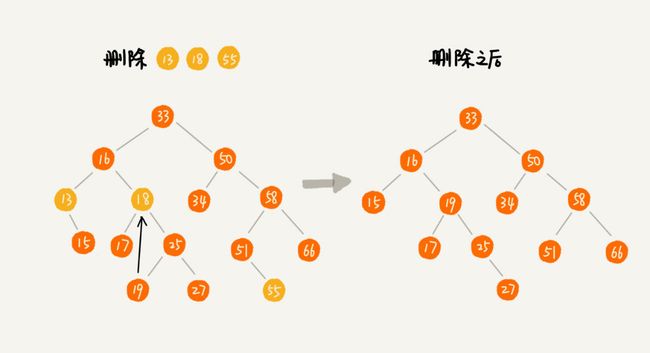
二叉查找树的其他操作
- 中序遍历二叉查找树,可以输出有序的数据序列,时间复杂度是O(n),非常高效
支持重复数据的二叉查找树
- 第一种方法:链表拉链
- 通过链表和支持动态扩容的数组等数据结构,把值相同的数据都存储在同一个节点上
- 第二种方法:将相等数据视作大的数,存在右子树
- 每个节点仍然只存储一个数据。在查找插入位置的过程中,如果碰到一个节点的值,与要插入数据的值相同,我们就将这个要插入的数据放到这个节点的右子树,也就是说,把这个新插入的数据当作大于这个节点的值来处理

- 当要查找数据的时候,遇到值相同的节点,我们并不停止查找操作,而是继续在右子树中查找,直到遇到叶子节点,才停止。这样就可以把键值等于要查找值的所有节点都找出来

- 对于删除操作,我们也需要先查找到每个要删除的节点,然后再按前面讲的删除操作的方法,依次删除

二叉查找树的时间复杂度分析
- 二叉搜索树根据构造的不同的,搜索所用的时间复杂度理所应当的也是不同的
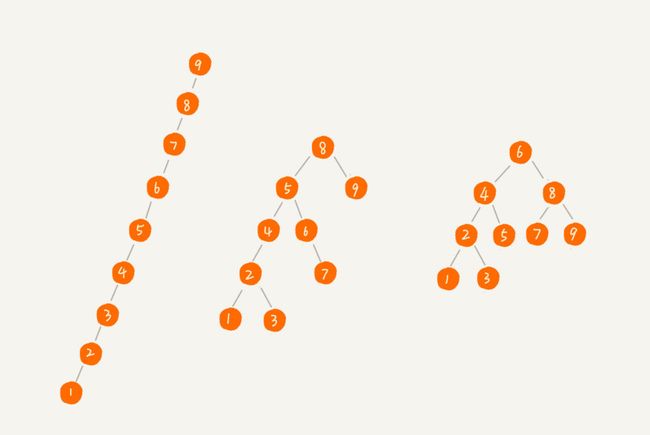
- 时间复杂度其实都跟树的高度成正比,也就是O(height)
- 树的高度就等于最大层数减一,为了方便计算,我们转换成层来表示。从图中可以看出,包含n个节点的完全二叉树中,第一层包含1个节点,第二层包含2个节点,第三层包含4个节点,依次类推,下面一层节点个数是上一层的2倍,第K层包含的节点个数就是2^(K-1)
- 但是对于最后一层的节点个数是在1个到2^(L-1)个之间
n >= 1+2+4+8+...+2^(L-2)+1
n <= 1+2+4+8+...+2^(L-2)+2^(L-1)

- L的范围是[log2(n+1), log2n +1]。完全二叉树的层数小于等于log2n +1,也就是说,完全二叉树的高度小于等于log2n
解答开篇:二叉树相对于散列表优势所在
- 散列表中的数据是无序存储的,如果要输出有序的数据,需要先进行排序。而对于二叉查找树来说,我们只需要中序遍历,就可以在O(n)的时间复杂度内,输出有序的数据序列
- 散列表扩容耗时很多,而且当遇到散列冲突时,性能不稳定,尽管二叉查找树的性能不稳定,但是在工程中,我们最常用的平衡二叉查找树的性能非常稳定,时间复杂度稳定在O(logn)
- 笼统地来说,尽管散列表的查找等操作的时间复杂度是常量级的,但因为哈希冲突的存在,这个常量不一定比logn小,所以实际的查找速度可能不一定比O(logn)快。加上哈希函数的耗时,也不一定就比平衡二叉查找树的效率高
- 散列表的构造比二叉查找树要复杂,需要考虑的东西很多。比如散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定
- 为了避免过多的散列冲突,散列表装载因子不能太大,特别是基于开放寻址法解决冲突的散列表,不然会浪费一定的存储空间
- 综合这几点,平衡二叉查找树在某些方面还是优于散列表的,所以,这两者的存在并不冲突。我们在实际的开发过程中,需要结合具体的需求来选择使用哪一个
课后题:如何通过编程,求出一棵给定二叉树的确切高度呢?
- 王争一句话,阿文做断手
// 深度优先搜索计算二叉树的高度
int GetHeightDFS(BTNode *root) {
if (root == NULL) {
// 这里存在一个问题就是对于叶子结点,他会直接视作将其高度记做1,而高度的定义是边数,也就是说对于只有一个节点的残疾树,我们直接视作高度为0,这点要注意
return 0;
}
int leftHeight = GetHeightDFS(root->lChild);
int rightHeight = GetHeightDFS(root->rChild);
return max(leftHeight, rightHeight) + 1;
}
// 后序遍历二叉树计算树的高度
int GetHeightPostOrder(BTNode *root) {
if (root == NULL) {
return 0;
}
int height = 0;
BTNode *p = root;
BTNode *q = NULL;
stack st;
while (p != NULL || !st.empty()) {
while (p != NULL) {
st.push(p);
p = p->lChild;
}
if (!st.empty()) {
p = st.top();
if (p->rChild == NULL || p->rChild == q) {
int tmpheight = (int)st.size();
height = max(height, tmpheight);
p = st.top();
st.pop();
q = p;
p = NULL;
} else {
p = p->rChild;
}
}
}
return height;
}
// 层次遍历二叉树计算树的高度
int GetHeightLevelOrder(BTNode *root) {
if (root == NULL) {
return 0;
}
int height = 0;
BTNode *p = root;
queue s;
s.push(p);
while (!s.empty()) {
height++;
int width = s.size();
for (int i = 0; i < width; i++) {
p = s.front();
s.pop();
if (p->lChild != NULL) {
s.push(p->lChild);
}
if (p->rChild != NULL) {
s.push(p->rChild);
}
}
}
return height;
}
25讲红黑树(上):为什么工程中都用红黑树这种二叉树
- 红黑将至
平衡二叉查找树
- 定义:二叉树中任意一个节点的左右子树的高度相差不能大于1

-
这里左边很明显是平衡二叉树,而右边,对于一个节点,就算其左节点为NULL,也视作高度为零,参与比较
-
红黑树不是严格的平衡二叉搜索树
-
平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些
定义一棵“红黑树”
-
红黑树中的节点,一类被标记为黑色,一类被标记为红色
-
根节点是黑色的
-
每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据
-
任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的
-
每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点
-
下面是忽略了叶子节点的红黑树

- 这里要理解下相邻节点不能同时是红色的,相邻是指有边线连着的两个节点,也就是说对于,两个红色节点想走到一起必须要经过一个黑色节点
红黑树->静态平衡?
- “平衡”的意思可以等价为性能不退化。“近似平衡”就等价为性能不会退化的太严重
- 一棵极其平衡的二叉树(满二叉树或完全二叉树)的高度大约是log2n,所以如果要证明红黑树是近似平衡的,我们只需要分析,红黑树的高度是否比较稳定地趋近log2n就好了
- 这里的分析比较绕,需要多看几遍才好理解
- 首先将所有红色节点去掉看下黑树是什么样子的

- 前面说红黑树特征时讲过:从任意节点到可达的叶子节点的每个路径包含相同数目的黑色节点。我们从四叉树中取出某些节点,放到叶节点位置,四叉树就变成了完全二叉树。所以,仅包含黑色节点的四叉树的高度,比包含相同节点个数的完全二叉树的高度还要小
- 这里理解下就是说按照同样的节点数去构建完全二叉树,显然还要多几层
- 所以黑树的高度小于log2n【因为前面讲过,完全二叉树即平衡二叉树的高度为log2n】
- 现在我们在加上红点,由于要求每两个红点之间夹一个黑点,所以最极端的情况也就是高度翻倍,及高度小于2log2n
- 所以,红黑树的高度只比高度平衡的AVL树的高度(log2n)仅仅大了一倍,在性能上,下降得并不多。这样推导出来的结果不够精确,实际上红黑树的性能更好
解答开篇:为什么都喜欢使用红黑树,而不是其他平衡二叉查找树呢?
-
AVL树是一种高度平衡的二叉树,所以查找的效率非常高,但是,有利就有弊,AVL树为了维持这种高度的平衡,就要付出更多的代价。每次插入、删除都要做调整,就比较复杂、耗时。所以,对于有频繁的插入、删除操作的数据集合,使用AVL树的代价就有点高了。
-
红黑树只是做到了近似平衡,并不是严格的平衡,所以在维护平衡的成本上,要比AVL树要低。
-
所以,红黑树的插入、删除、查找各种操作性能都比较稳定。对于工程应用来说,要面对各种异常情况,为了支撑这种工业级的应用,我们更倾向于这种性能稳定的平衡二叉查找树。
-
说白了,中庸就是最好的
课后思考:动态数据结构支持动态地数据插入、删除、查找操作,除了红黑树,我们前面还学习过哪些呢?能对比一下各自的优势、劣势,以及应用场景吗?
- 动态数据结构是支持动态的更新操作,里面存储的数据是时刻在变化的,通俗一点讲,它不仅仅支持查询,还支持删除、插入数据。而且,这些操作都非常高效。如果不高效,也就算不上是有效的动态数据结构了。所以,这里的红黑树算一个,支持动态的插入、删除、查找,而且效率都很高。链表、队列、栈实际上算不上,因为操作非常有限,查询效率不高
- 散列表:插入删除查找都是O(1), 是最常用的,但其缺点是不能顺序遍历以及扩容缩容的性能损耗。适用于那些不需要顺序遍历,数据更新不那么频繁的。
- 跳表:插入删除查找都是O(logn), 并且能顺序遍历。缺点是空间复杂度O(n)。适用于不那么在意内存空间的,其顺序遍历和区间查找非常方便。
- 红黑树:插入删除查找都是O(logn), 中序遍历即是顺序遍历,稳定。缺点是难以实现,去查找不方便。其实跳表更佳,但红黑树已经用于很多地方了