/**************************************************************************************************************************
文件说明:
【1】这个程序用于将图像数据集合(a set of images)和与这个图像相关的注释(annotations)转换为caffe专用的数据库LMDB/LEVELDB
格式
【2】使用方法:convert_annoset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
[1]ROOTFOLDER/----------------图像数据所在的文件夹
[2]LISTFILE-------------------输入图像数据的文件列表,其每一行为subfolder1/file1.JPEG 7
[3][FLAGS]--------------------可选参数,是否使用shuffle,颜色空间,编码等
【3】对于【分类任务】,文件的格式如下所示:imgfolder1/img1.JPEG 7
【4】对于【检测任务】,文件的格式如下所示:imgfolder1/img1.JPEG annofolder1/anno1.xml
检测任务的使用举例:
代码需要进行三处修改:
【1】DEFINE_string(anno_type, "detection","The type of annotation {classification, detection}.");
【2】DEFINE_string(label_map_file,"E://caffeInstall2013SSDCUDA//caffe-ssd-microsoft//data//ssd//labelmap_voc.prototxt",
"A file with LabelMap protobuf message.");
【3】主函数中代码修改:
argv[1] = "E://caffeInstall2013SSDCUDA//caffe-ssd-microsoft//data//ssd//";
argv[2] = "E://caffeInstall2013SSDCUDA//caffe-ssd-microsoft//data//ssd//test.txt";
argv[3] = "E://caffeInstall2013SSDCUDA//caffe-ssd-microsoft//examples//ssd//ssd_test_lmdb";
开发环境:
Win10+cuda7.5+cuDnnV5.0+ccaffe_windows_ssd+OpenCv+VS2013
时间地点:
陕西师范大学 文津楼 2017.8.10
作 者:
九 月
***************************************************************************************************************************/
#include
#include // NOLINT(readability/streams)
#include

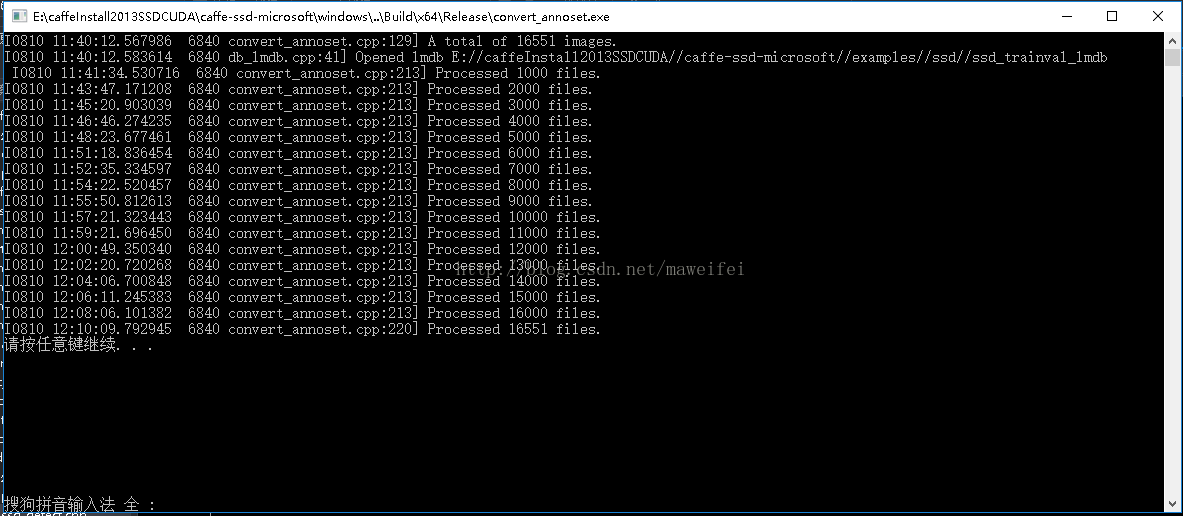
用了30分钟,终于生成了训练阶段所需要的LMDB数据库文件,如下所示: