机器学习中的评价方法总结(正确率,精确率,召回率,F1值,ROC曲线,AUC面积,Loss)
机器学习中的评价指标详解
- 机器学习中的评价指标
- 混淆矩阵
- 正确率(准确率、Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- P-R曲线
- F1-值(F1-Score)
- ROC曲线
- *示例代码*
- Reference
机器学习中的评价指标
对于一个模型的好坏,常常采用一系列指标来评价。往往评价指标分数越高,则反映模型更准确,具有更好的泛化性等。
评价指标可以对于分类任务中的某一类使用,看模型是否在该类有较好的表现。
也可以对整个分类任务,用于反映模型的整体效果
混淆矩阵
介绍评价指标就不得不说一下混淆矩阵了。混淆矩阵是在分类问题中反映模型判断正误的表格。以二分类为例,多分类类似。
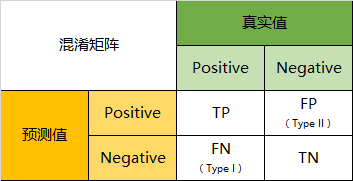
| 真实值\预测值 | Positive | Negative |
|---|---|---|
| True | TP | FN |
| False | FP | TN |
以上两种写法都可以
其中各项指标含义如下:
TP:真正类,是指真实标签为1,预测标签的值也为1。
FN:假负类,真实标签为1,预测标签值为0。
FP:假正类,真实标签为0,预测标签值为1。
TN:真负类,真实标签为0,预测标签为0。
以上就是在计算各项指标前需要统计的数据。
正确率(准确率、Accuracy)
正确率是指:反映一个模型能预测正确的概率。反映模型的正确程度,其公式如下:
A c c u r a c y _ r a t e = T P + T N T P + F P + F N + T N Accuracy\_rate=\frac{TP+TN}{TP+FP+FN+TN} Accuracy_rate=TP+FP+FN+TNTP+TN
分子为:真正类与真负类的个数和。
分母为:所有情况的总和。
可以绘制的图像为总体的正确率图像,横轴为迭代步数,纵轴为正确率。同时可以绘制Loss图像。
缺点
当数据十分不均衡的情况下(正负例比例为:10000:1)。将所有结果预测为某一类,即可得到很高的正确率,但模型有误。
精确率(Precision)
精确率:用于反映模型预测实例中的精确程度,即预测为正的样本中有多少是真正的正样本。
体现模型对负样本的区分能力。
其公式如下:
P r e c i s i o n _ r a t e = T P T P + F P Precision\_rate=\frac{TP}{TP+FP} Precision_rate=TP+FPTP
分子为TP是样本为正预测为正的样本个数。
分母为TP+FN,表示预测结果中预测为正的个数总和。
可以绘制正确率图像,横轴为迭代步数,纵轴为正确率图像。
召回率(Recall)
召回率:用于反映模型的敏感程度,即正确的样本中有多少被预测为正确的样本。
体现模型对正样本的识别能力。
其公式如下:
R e c a l l _ r a t e = T P T P + F N Recall\_rate=\frac{TP}{TP+FN} Recall_rate=TP+FNTP
分子为TP是样本为正预测为正的样本个数。
分母为TP+FN,表示样本为正预测为正与样本为正预测为负的个数总和。
可以绘制召回率图像,横轴为迭代步数,纵轴为召回率图像。
P-R曲线
P-R曲线即为:精确率-召回率曲线,横坐标为Recall,纵坐标为Precision
绘制P-R曲线时,对判定阈值从正无穷取到负无穷,这时模型的precision与recall值会根据判定阈值的不同而改变,所以会呈现上述图像。
解释
如果Recall为0则没有召回样本,则准确率也为0,如果Recall召回一个样本,该样本为正确样本,则会在图像的左上角绘制一个点。若全部召回,即阈值极低,则召回个数中有许多都是非正类样本,所以precision也相应的降低。
缺点
当负样本个数发生剧烈的变动时,图像会产生抖动。即左上角的位置会向下移动。
P-R曲线围起来的面积称为平均精度(AP,Average-Precision)
F1-值(F1-Score)
F1分数为精确率和召回率的调和平均数,用于衡量模型健壮性的指标,最大值为1,最小值为0.
公式如下:
2 F 1 _ S c o r e = 1 P r e c i s i o n _ r a t e + 1 R e c a l l _ r a t e \frac{2}{F1\_Score}=\frac{1}{Precision\_rate}+\frac{1}{Recall\_rate} F1_Score2=Precision_rate1+Recall_rate1
F 1 _ S c o r e = 2 × P r e c i s i o n _ r a t e ∙ R e c a l l _ r a t e P r e c i s i o n _ r a t e + R e c a l l _ r a t e F1\_Score=2\times\frac{Precision\_rate\bullet Recall\_rate}{Precision\_rate+Recall\_rate} F1_Score=2×Precision_rate+Recall_ratePrecision_rate∙Recall_rate
ROC曲线
ROC曲线 :接受者操作特征(receiver operating characteristic),ROC曲线上的每个点反映着对统一信号刺激的感受。
横轴:负正类率(False Positive Rate,FPR)特异度,负类中预测的正类个数占所有负类的比重。
纵轴:真正类率(True Positive Rate, TPR)灵敏度,正类中预测为正类的个数占所有正类的比重。
公式如下:
F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
与P-R曲线类似,同样是将阈值从无穷大取到0的过程中,记录所有“时刻”的FPR和TPR的数据,将这些数据描绘成点即可画出ROC曲线。
阈值最大时对应的坐标轴(0,0)点;阈值最小时对应的坐标轴(1,1)点。所以ROC曲线的整体走势为从左下角到右上角的一条凸曲线,如果曲线非凸,则将模型判定“翻转”会取得更好的模型效果。
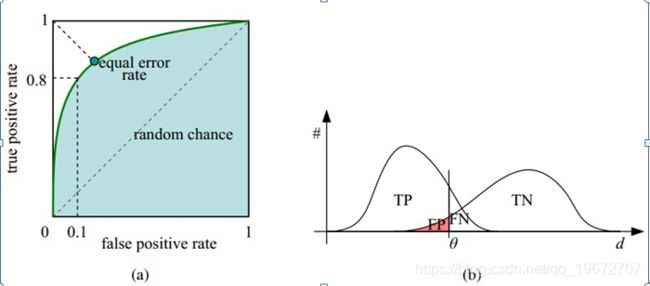
FPR:越大,则表示预测正类中负类越多。
TPR:越大,则表示预测正类中正类越多。
越靠近(0,1)点表示模型效果越好。
AUC面积是ROC曲线下的面积,数值可直观评价分类器的好坏,值越大越好。
意义:AUC表示一个概率值,是模型将正样本放在负样本概率值大的概率。AUC值越大,当前分类算法越有可能将正样本排在负样本前面,从而更好的分类。
示例代码
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from scipy import interp
# 加载自带数据
iris = datasets.load_iris() # 鸢尾植物
print(iris) # 字典形式存储,有data和target等多种数据
X = iris.data
print(X.shape)
# X的shape为(150,4)
print(X)
# 二维列表
y = iris.target
print(y.shape)
# y的shape为(150,)
print(y)
# 一维列表
# Binarize the output
# a = ["a"]*50 + ["b"]*50 +["c"]*50 + ["d"]*50
# print(a)
# y = label_binarize(a, classes=["a", "c", "d","b"])
y = label_binarize(y, classes=[0, 1, 2]) #one-hot化数据,y为原始的标签数据,
# classes为一个列表,存储了原始标签的种类,标签的位置就是one-hot之后为1的位置,classes的长度为one-hot表的长度,长度必须正确,否则会报错
print(y)
print(y.shape)
n_classes = y.shape[1] # class的数目,即分类数目
# Add noisy features to make the problem harder
# 添加噪声,因为数据较为干净,看ROC的效果就要将其进行对应的加燥处理
random_state = np.random.RandomState(1) # 创建随机数生成器,随机种子为1
print(random_state)
# random_statev2 = np.random.RandomState(0) # 创建随机数生成器,随机种子为0
# 随机种子用于产生相同的伪随机数
n_samples, n_features = X.shape # n_samples为data的数量,n_features为data的特征维度
print(n_features)
noisy_data = random_state.randn(n_samples, 200 * n_features) # 产生一个二维随机矩阵shape为(150,800),
# randn代表这个数组中的数字服从标准正态分布
print(noisy_data.shape)
print(noisy_data)
X = np.c_[X, noisy_data] #numpy的concat操作,按行进行拼接,两个矩阵的第一行进行拼接,然后逐行拼接
print(X)
print(X.shape)
# shuffle and split training and test sets
# 打乱和切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.5,
random_state=0)
# 按照50%的分配比例切分测试集
# 随机种子为0,每次打乱的顺序都一样
# Learn to predict each class against the other
classifier = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True,
random_state=random_state))
# svm二分类器处理多分类任务,核函数使用“linear”,probability :是否采用概率估计?.默认为False
# random_state :数据洗牌时的种子值,int值或者为对象
y_score = classifier.fit(X_train, y_train).decision_function(X_test)# 训练模型,并做预测,得到预测结果
fpr = dict() # 假阳性率
tpr = dict() # 真阳性率
roc_auc = dict() # auc面积
for i in range(n_classes):
# 取出每一类的标签列表
test_res, pred_res = y_test[:, i], y_score[:, i]
# print(test_res) # 真实数据
# print(test_res.shape) # 一维列表
# print(pred_res) # 预测数据
# print(pred_res.shape)
fpr[i], tpr[i], _ = roc_curve(test_res, pred_res,)
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
绘图部分
plt.figure()
lw = 2
plt.plot(fpr[2], tpr[2], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()

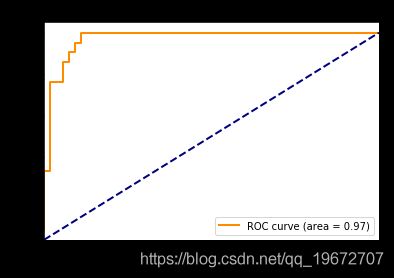
plt.figure()
lw = 2
sig = "micro"
plt.plot(fpr[sig], tpr[sig], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[sig])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
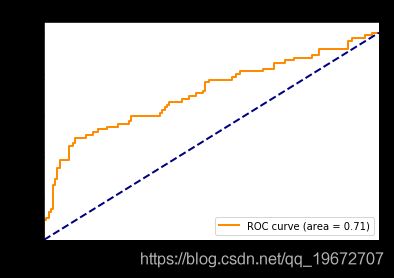
plt.figure()
lw = 2
sig = 0
plt.plot(fpr[sig], tpr[sig], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[sig])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
Reference
[1] https://www.cnblogs.com/dlml/p/4403482.html
[2] https://www.cnblogs.com/sddai/p/5696870.html
[3] https://blog.csdn.net/abcjennifer/article/details/7359370
[4] https://blog.csdn.net/pzy20062141/article/details/48711355
[5] https://blog.csdn.net/u013385925/article/details/80385873
[6] https://blog.csdn.net/hh1294212648/article/details/77649127
[7] https://blog.csdn.net/Titan0427/article/details/79356290
[8] https://blog.csdn.net/qq_14997473/article/details/82684300
[9]《百面机器学习》P29-P32
[10]《统计学习方法》P18-P20