【分布式系统篇】链路追踪之Jaeger安装&使用入门
目录
- 1. 前世
- 2. Jaeger与Zipkin
-
- 2.1 关于Jaeger
- 3. 安装
- 4. 使用
-
- 4.1 启动一个应用
- 4.2 发送请求
- 4.2 Jaeger查看服务架构
- 4.3 查看一个trace
- 4.4 Contextualized logging(情景化日志)
- 4.5 Span Tags & Logs
- 4.6 链路拆解分析
- 4.6 筛选&排序
- 4.7 比较多个Trace
- 结束
1. 前世
在介绍Jaeger之前,有一些背景我们应该知道。
Jaeger的实现遵循的是OpenTracing规范,什么是OpenTracing规范?
OpenTracing制定了一套平台无关、厂商无关的Trace协议,使得开发人员能够方便的添加或更换分布式追踪系统的实现,早在近十年前就已经制定;与它相关的还有谷歌的OpenCensus,还有两者合并后的OpenTelemetry;由于本文主要讲Jaeger,更多你应该了解的前世请参考这篇阿里云写的文章–OpenTelemetry-可观察性的新时代。
2. Jaeger与Zipkin
Jaeger 是Uber公司研发,后来贡献给CNCF的一个分布式链路追踪软件;
另外对标Jaeger的还有一个软件是Zipkin,由谷歌Dapper论文启发,Twitter开发,现在有专门团队维护,需要注意的是,Zipkin比Jaeger开发的早,前者在2012启动,Jaeger第一个正式版本发布于2017年,不过两者目前在Github上的star数量相差不多;
一些对比如下(数据统计截止于本文发布时间):
| Zipkin | Jaeger | |
|---|---|---|
| Stars | 13.3K | 11.4K |
| 发布时间 | 2012 | 2017 |
| 开发语言 | Java | Go |
| issues opened | 161 | 332 |
| versions-released | 202 | 34 |
| last-release-time | 2020-4-16 | 2020-6-19 |
| contributors | 139 | 156 |
| official-supported-lang | C#, Go, Java, JS, Ruby, Scala, PHP | C#, C++, Go, Java, Node.js, Python |
| official-docs | Zipkin-docs | Jaeger-docs |
| backend-storage | Cassandra、ElasticSearch | Cassandra3.4+, ElasticSearch5.x/6.x/7.x |
上面列出的是官方支持的开发语言,两者都还有许多非官方支持的语言,在官网可以找到。
Jaeger属于后起之秀,架构方面也是参考了Zipkin的设计,没有太大差别,而目前两者的差距也是逐渐缩小。
另外,两者都支持仅内存方式存储数据,方便搭建测试环境。
2.1 关于Jaeger
官方给出的特性介绍:
- 分布式上下文传递
- 分布式事务监控
- 根本原因分析
- 服务依赖分析
- 性能、延迟优化
可扩展性
Jaeger的后端为无单点故障设计,可随时根据需要进行扩展;uber每天使用它处理几十亿级别的span。
span,表示一个逻辑工作单元,包含有操作名称、起始时间以及操作耗时。span之间可以存在嵌套和并排关系,span之间也有顺序。
原生支持OpenTracing
- 通过span引用以有向无环图表示trace
- 支持强类型的span tag和结构化日志
- 通过baggage支持分布式的上下文传递
Jaeger的后端,webUI,以及相关的框架适配库的设计实现都是支持OpenTracing标准的;
另外,开头提到的OpenTelemetry也是兼容OpenTracing的,所以博主推荐直接使用OpenTelemetry的API,点击这里查看OpenTelemetry对各家语言和框架的SDK和适配库(英文称Instrumentation)。
云原生部署
- 官方已将Jaeger后端打包为docker镜像发布;
- 二进制文件支持CLI选项、ENV、配置文件方式三种方式加载配置;
- K8s部署, 参考Kubernetes operator, Kubernetes templates and a Helm chart.
可观测性
Jaeger后端组件均支持暴露指标到Prometheus(其他监控后端也支持);
Log是通过第三日志库zap写到stdout
向后兼容Zipkin client
如果你已经使用Zipkin作为trace平台,并且希望迁移到Jaeger,不用太担心;
无需重写client代码,Jaeger后端支持Zipkin格式的span,只需要将数据的转发目的地指向Jaeger后端就行。
其创造者发布了一本书Mastering Distributed Tracing,其中涵盖了Jaeger的设计和操作的方方面面,以及常见的分布式链路追踪。
关于两者的选择,也是见仁见智吧;我个人的看法,如果你或你的团队主要使用Go语言开发,我仍然建议使用Jaeger,这样在使用过程中遇到库方面的问题后,你能够方便的查询client源码或Jaeger源码来定位问题,甚至也许你可以自己解决问题,或者也能够在Github上高效的反馈bug或提问;
另外,可以方便我们阅读源码学习其中的设计之道。
3. 安装
为方便演示,使用官方推荐的Docker快速启动方式:
docker run -d --name=jaeger -p6831:6831/udp -p16686:16686 jaegertracing/all-in-one:latest
浏览器Web UI: http://localhost:16686/
注意:这个docker镜像封装的jaeger是把数据放在内存中的,仅用于测试,正式使用需指定后端存储。
4. 使用
现在需要一点数据让我们把页面操作起来。
4.1 启动一个应用
这个应用是Jaeger仓库中的一个示例
这里我通过源码启动:
git clone [email protected]:jaegertracing/jaeger.git jaeger
cd jaeger/examples/hotrod
go run ./main.go all
同样提供了docker镜像启动方式,参考示例链接。
访问hotrod的webUI:http://127.0.0.1:8080
大坑:博主在第一次访问这个页面的时候,速度极慢,点击按钮无反应,花费一两个小时才找到问题所在,简单来说,你本地必须要能够科学上网才可以正确访问这个页面,因为页面加载时会加载一个外网地址的js文件,这个你通过F12可以看到。(这里我真的吐了,开了单子给他们,我想不明白一个本地的示例为啥要去公网加载一个js文件,不能放到本地?)
2020-08-20更新:repo主已经合并博主提交的修复此坑的PR,但请注意,这个页面还会加载一个线上的js和css文件,不过这两不需要科学上网就可以访问。
吐槽完了还得继续,下面是正确加载后的页面,左上角有个id,每次刷新都会生成一个新的;
四个按钮分别代表四个客户,点击一个按钮就会给他下单一辆车并送过去,就是一个下单请求,响应数据是车牌号以及预计到达时间。

4.2 发送请求
点击一个按钮,发送下单请求,效果见下图

分别是车牌号,预计到达时间,请求序列号,请求耗时。
4.2 Jaeger查看服务架构
切换到Jaeger webUI,点击上面的System Architecture --> DAG (directed acyclic graph,有向无环图)
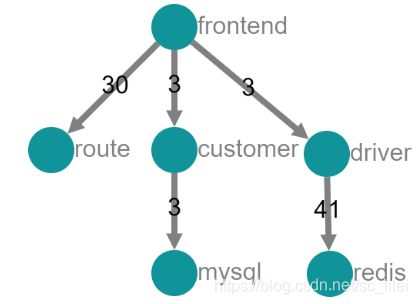
这就是我们启动的hotrod的微服务架构图,可以看到有几个服务,依赖关系如何。
首先,这里有四个服务(真实的),两个存储(组件模拟的),其中的数字就是请求调用次数,图中展示了redis调用的次数最多,有点纳闷,回到Jaeger 主页面看看。
4.3 查看一个trace

通过前面的架构图可以指定,frontend是最上层服务,通过它应该可以查询到所有的调用记录。
上面的查询结果就是点击了查询按钮之后的效果,在第一个记录中,可以看到3个Errors,后面是一次请求经理的几个服务或阶段。
点进去看详细
这里提到一个词 Span,这里先介绍什么是Trace,一个 trace 代表了一个事务或者流程在(分布式)系统中的执行过程;
一个 span 代表在分布式系统中完成的单个工作单元,也包含其他 span 的 “引用”,这允许将多个 spans 组合成一个完整的 Trace。
比如说,调用一次查询用户信息的请求 /get_user?uid=1,这里分几步:
- 第一步,请求到达路由服务,路由服务根据路径调用handler
- 第二步,handler内部调用service服务
- 第三步,service根据路由调用其handler
- 第四步,service-handler内调用数据库
这里就有四个耗时阶段,每个阶段都要耗时,将每个阶段称作是一个span,但其实你会发现上一个阶段会包含下面的所有阶段,这里解释了前面提到的span引用问题;而每个span都有一些元信息:
- span-id
- 操作名
- 开始时间和结束时间,以及耗时
- tag,用户自定义标签便于查询过滤和理解数据
- log,记录 Span 内特定时间或事件的日志信息,以及应用程序本身的其他调试或信息输出
- span context,跨越进程边界,传递到子级 Span 的状态。常在追踪示意图中创建上下文时使用
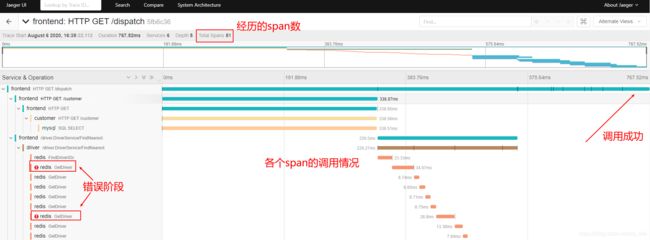
这里通过上面的图解释一下调用过程:
frontend服务接收到外部HTTP GET请求,路由是/dispatchfrontend服务调用customer服务的/customer接口customer服务内执行mysql查询,结果返回再返回frontend服务- 然后
frontend服务向driver服务发起RPC调用,接口是Driver::findNearest driver服务内再调用多次redis,并且可以看到发生错误- 然后
frontend服务又向route服务发起了多次HTTP GET调用,路由是/route - 最后
frontend服务返回结果。
点开每个span都可以看到一些细节,包含tag和log;比如发送错误的redis调用,在log部分可以看到更多细节,这都是我们在代码中打的

4.4 Contextualized logging(情景化日志)
简单说就是,每个span下的log部分都是针对这一次调用产生的记录,这对我们的帮助简直不要太大;以往我们都是直接去tail -f x.log,如果一秒有多个并发请求,我们很难从那么多日志记录中找出问题。
4.5 Span Tags & Logs
这个前面也说了,tag自己定义,kv格式,jaeger中可以用来筛选trace,而log则是记录与这个span这次请求密切相关的事件,一般会带有时间戳,比如redis timeout。(你如果真的喜欢,仍然可以把这次超时事件记录为tag,如event=timeout)
注意:OpenTracing的规范仓库中的semantic data conventions(语义数据约定)描述了一些能够应对多数情况的tag名和log字段,因此我们还是应该参考一下这个约定,少搞特殊。
4.6 链路拆解分析
现在以frontend服务为主角,把以它为root的span都折叠,得到下图

此图可以让我们更清晰的这个trace过程,哪些span是顺序执行的,哪些是并行的。
顺序执行的span:
- /customer
- /driver.DriverService/FindNearest
并行的span:
- route (每次并发3个请求,图中显示的蓝条在时间线上重合)
这有多方便不用我多说了,代码中的并发调用看的一清二楚。
4.6 筛选&排序
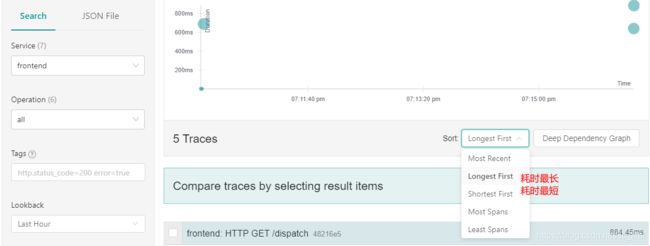
查询时筛选是通过service, tag, min/max duration;
这里说一下排序功能,我们可以对搜索结果排序,有几种方式,见下图
4.7 比较多个Trace
在搜索结果中选中至少两个trace,点击右上角的比较按钮
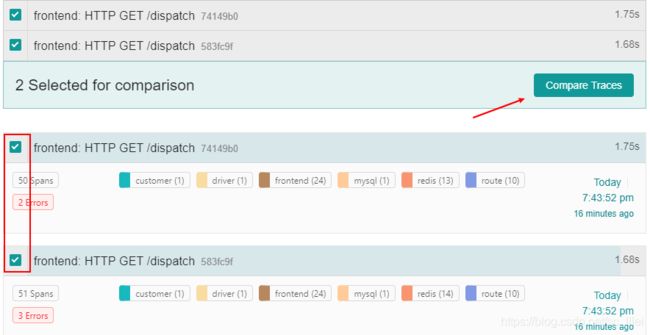
下图是比较的页面
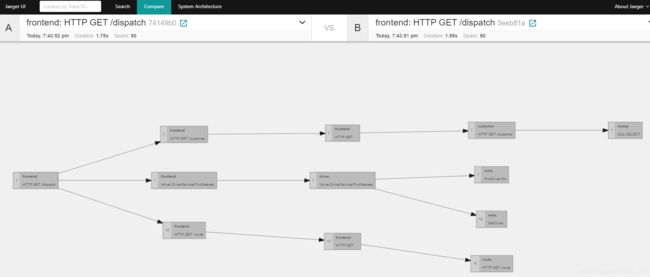
看懂这个图我开始也是一脸懵逼,国内转了一圈没找到,还好在国外medium网站找到了介绍的文章,如有兴趣可查看原文
下面介绍怎么看对比图;
首先,忽略方块颜色,这些箭头连起来的方块图就是一个trace的调用链,一个方块就是一个span。
一般我们只会选择两个相同的请求来比较,上图其实就是两个trace重合之后的图;如果你选择两个不同的请求比较,看到的是下图
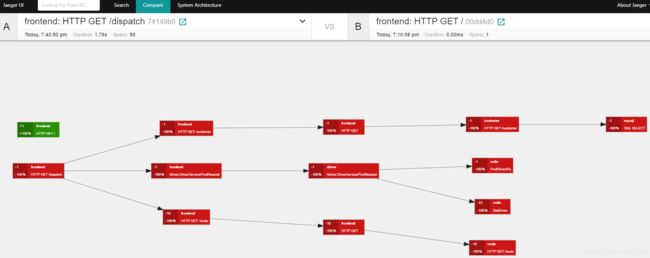
顺便就讲一下这图,很明显,两个不同路由的请求trace无法重合,其实没有比较意义,但可以解释一下这个颜色,我们放大来看;
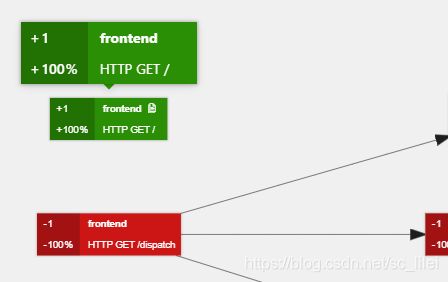
- 深绿色,表示这个span在只存在于trace-B中,A没有这个span
- 深红色,表示这个span在只存在于trace-A中,B没有这个span
不过这不是绝对的,因为我看到了这种比较情况
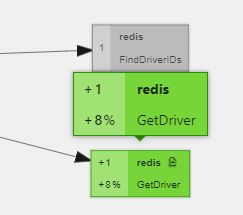
同样是深绿色,但是两个trace种都有这个span,只是B多于A,我想可以通过数值+8%得出结论,B的span数是14,A是13,算起来就是多了大约8%,看来我们更应该关注这个数值,不过我想颜色的深浅仍然可以代表差距的大小。
下面看另一张图:

这里还有两种颜色;
- 浅绿色,表示这个span在trace-B(右边这个)的数量多余trace-A
- 浅红色,表示这个span在trace-A(左边这个)的数量多于trace-B
最后就是看到的更多的灰色,表示两个trace中都有这个span,且数量一致。
那么到底如何根据比较得出结论? 看下面这张图
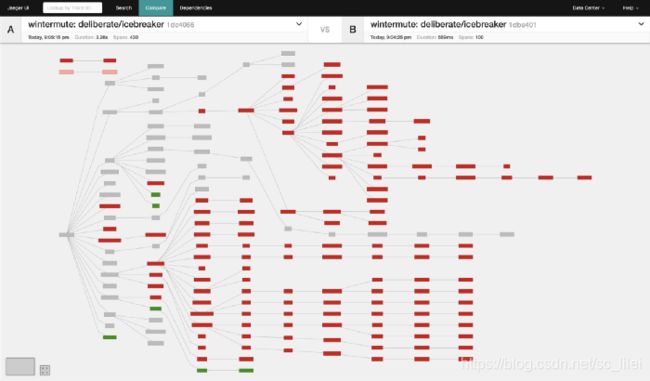
推断:首先A和B在靠近root span的部分有重合,但大量的child span显示深红色表示trace-B缺少这些深红色的span,一般表示在灰色span处发生了调用失败事件,导致一连串的span消失。
这样的比较可以在调查事件时提供非常及时和细致的线索。我们可以快速而自信地缩小搜索范围。
如果发生上图这样的事件,我们不应该直接去看深红色的span细节,而应该查看靠近它们的灰色span的log信息,以快速定位问题。
结束
编写本文花费了不少精力和时间,文中可能出现文字或表述错误,欢迎读者指正。
转载请注明来源!
参考文章:
- Take OpenTracing for a HotROD ride
- Trace comparisons arrive in Jaeger 1.7