用Python实现校园通知更新提醒
前言
这个项目实已经在一个月前已经完成了,一直都想写一篇博客来总结这个过程中遇到的一些问题。但最近一个月来都比较忙,所以一直拖到了现在。
首先说说起因吧,我没事的时候,总喜欢依次点开学校主页、教务处、图书馆以及学院的网站,看看有没有什么新通知,虽然大多与我无关。恰逢最近正在学Python,经常听到别人说用Python写爬虫很简单,但自己尚未接触过爬虫。于是抱着试一试的心态看了几篇关于Python爬虫的博客,发现实现起来的确很简单。于是,便一边看着官方的文档说明,一边看着别人的博客,终于完成了自己的第一次爬虫。
简介
使用urllib.request库获取到目标url(各个网站的’更多通知’页)的源代码,然后利用Python的re库进行正则匹配,提取到通知相关信息后,与文件中存取的上一次爬取到的信息进行对比。
若检测到有新的通知,则利用twilio库向指定手机号码发送SMS,利用smtplib库向指定邮箱发送提醒信息。
此外,还具有发送日志以及异常日志的功能。
目前仅支持本校的通知提醒,后续会逐步提高项目的通用性。
源码:
Github地址:School_Notice
准备工作
- 安装twilio库:
pip install twilio - 注册twilio账号:Twilio
- 验证手机号:用来接收短信提醒的号码必须在twilio上进行验证
遇到的问题
邮件发送
- 若用名为msg的变量来保存邮件文本,则
msg['From']以及msg['To']必须为实际的发件人地址,否则可能会出现异常:SMTPDataError(code, resp).如必须写作:msg['From'] = '[email protected]'.我是使用的QQ邮箱来发邮件,至于其他邮箱需不需要这样写还不清楚。 - 原本想用一个for循环来实现多人发送,后来发现smtplib库的sendmail方法支持多人发送,但参数应为一个list,故可用
str.split(',')将字符串转为list。 - 我使用的是Windows下的Python,若计算机名为中文,则有可能会导致出现异常,可通过右击此电脑->属性,修改计算机名。
- 程序代码中使用的邮箱密码不是QQ密码,应在邮箱设置->账户->SMTP服务处,获取授权码。
其他问题
- 有时候会接收不到Twilio发送的短信,给10086打电话也没问出个所以然,可能是因为短信中有敏感词(如:学校名),修改短信内容后就可以了
- 对上述几个网站的源码使用
re.findall后返回的列表中的每个元组中的元素的顺序均为时间、标题、链接,但对学生处网站的源码正则匹配后的元素顺序并不是按照上述顺序的。所以应单独进行调整,但直接修改一个元组中的元素,会出现异常:error:tuple' object does not support item assignment。解决方法是:
if(subject_EN == 'snnu_xsc'):
new_data = []
for item in data:
temp = (item[1], item[2], item[0])
new_data.append(temp)
data = new_data- Python3中的print函数是自动换行的,若不需要自动换行,则可写作:
print(str,end='') - 不同网站的编码格式可能不同,应按照各自的编码方式进行解码。若均采用
utf-8的方式,则可能会出现各种编码问题,如:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xc9 in position 167
解决方法是:
if find1 == -1 & find2 == -1:
Coding = 'utf-8'
else:
# 教务处网页源码编码格式为为gbk
# 学生处网页源码编码格式为gb2312
Coding = 'gbk'
data = response.read().decode(Coding)Python程序打包为exe(Pyinstaller)
安装及使用
- 使用
pip install pywin32安装pywin32 - 使用
pip install PyInstaller安装Pyinstaller - 使用
pyinstaller -F main.py即可将Python程序打包为exe程序
注意事项
- 打包之前应将用到的第三方库(此项目仅用到Twilio)复制到与要打包的py文件同一目录下。
- 可使用
pyinstaller -F -i logo.ico main.py,为生成的exe程序添加图标 - 使用的ico文件像素不能过小,否则有可能出现:打包后的程序图标只有在资源管理器中设置为以小图标查看的情况下才显示的是自己的图标,其他情况仍未默认图标
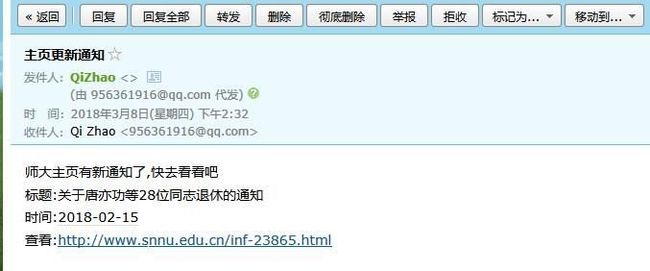
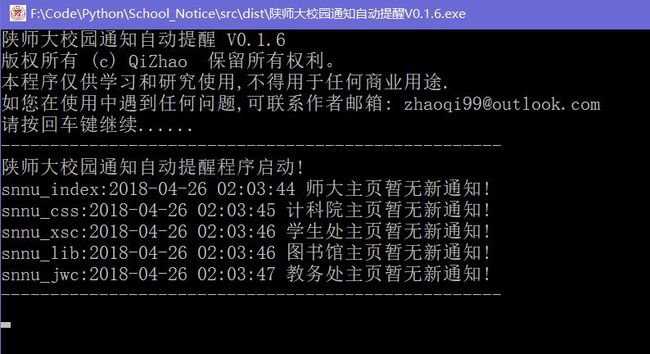
使用截图

参考博客
- 应用python对校园通知的更新进行推送
- 使用python发短信给自己的手机
- Python打包方法——Pyinstaller