爬取微信公众号历史记录
微信公众平台并没有对外提供 Web 端入口,只能通过手机客户端接收、查看公众号文章,Mac电脑通过Charles可以抓取手机端Https请求,具体参考下面的文章:
十分钟学会Charles抓包(iOS的http/https请求)
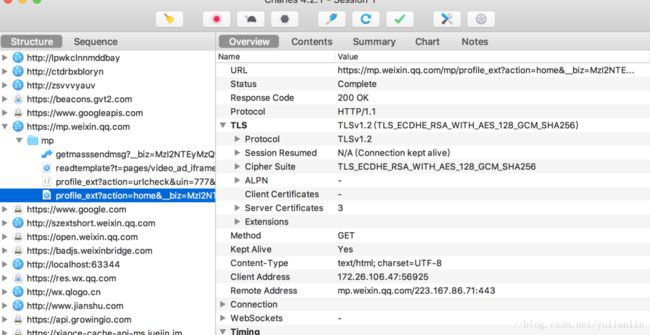
通过上面的图可以看到请求的参数和获取的结果,进一步分析,可以发现历史记录都在js中的msgList中返回了。

爬虫的基本原理就是模拟浏览器发送 HTTP 请求,然后从服务器得到响应结果,现在我们就用 Python 实现如果发送一个 HTTP 请求。这里我们使用 requests 库来发送请求。
代码:
import requests
def crawl():
# url中的参数需要根据自己的情况做调整
url = "https://mp.weixin.qq.com/mp/profile_ext?" \
"action=home&" \
"__biz=MzI2NTEyMzQwMQ==&" \
"scene=124&" \
"devicetype=iOS11.2.5&" \
"version=16060520&" \
"lang=zh_CN&nettype=WIFI&a8scene=3&" \
"fontScale=100&" \
"pass_ticket=i5Zob72l9%2BTNg97YKb4%2BPYQ6ZcLc6yHUhsp%2FBFDJW9jEpeDC39M1acbCZlfF6zK3" \
"wx_header=1"
headers = """
Host: mp.weixin.qq.com
Cookie: devicetype=iOS11.2.5; lang=zh_CN; pass_ticket=i5Zob72l9+TNg97YKb4+PYQ6ZcLc6yHUhsp/BFDJW9jEpeDC39M1acbCZlfF6zK3; version=16060520; wap_sid2=CLXC37AEElxoMFRPTkh4VUhldWJXU0YxR0M4dC1BdU9WOWdIanJiWXlsNWh3d2NlZHFjb2lhSGNwMlZXZ2k5QWRWbFhsMVhVcHFfbEtGNzdOdndrVkYxRC1JOEU2cklEQUFBfjCHpu7UBTgNQJVO; wxuin=1175970101; pgv_pvi=4165842944; pgv_pvid=4653316680; sd_cookie_crttime=1517444025808; sd_userid=80891517444025808
X-WECHAT-KEY: 8454e2d616c046dd2e80a25042d71ff65b59939c7bfa4631585773ab20ee3f9314bfd6f4dbfa146acf62ca8c4557550f1dd0dbb77d6052d9e4218daf825bf68827af322070a0242fdf56792dbb68dc2f
X-WECHAT-UIN: MTE3NTk3MDEwMQ%3D%3D
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
User-Agent: Mozilla/5.0 (iPhone; CPU iPhone OS 11_2_5 like Mac OS X) AppleWebKit/604.5.6 (KHTML, like Gecko) Mobile/15D60 MicroMessenger/6.6.5 NetType/WIFI Language/zh_CN
Accept-Language: zh-cn
Accept-Encoding: br, gzip, deflate
Connection: keep-alive
"""
headers = headers_to_dict(headers)
response = requests.get(url, headers=headers, verify=False)
# print(response.text) #打印返回全部的内容
if '验证 ' in response.text: #如果提示失败了,请检查请求头,看下Cookie是否失效
raise Exception("获取微信公众号文章失败,可能是因为你的请求参数有误,请重新获取")
data = extract_data(response.text)
for item in data:
print(item)
def extract_data(html_content):
"""
从html页面中提取历史文章数据
:param html_content 页面源代码
:return: 历史文章列表
"""
import re
import html
import json
rex = "msgList = '({.*?})'"
pattern = re.compile(pattern=rex, flags=re.S)
match = pattern.search(html_content)
if match:
data = match.group(1)
data = html.unescape(data)
data = json.loads(data)
articles = data.get("list")
for item in articles:
print(item)
return articles
def headers_to_dict(headers):
"""
将字符串
'''
Host: mp.weixin.qq.com
Connection: keep-alive
Cache-Control: max-age=
'''
转换成字典类型
:param headers: str
:return: dict
"""
headers = headers.split("\n")
d_headers = dict()
for h in headers:
h = h.strip()
if h:
k, v = h.split(":", 1)
d_headers[k] = v.strip()
return d_headers
if __name__ == '__main__':
crawl()