利用决策树模型分析电信客户流失预测项目
首先这是一个比较经典的项目了,自己先拿到数据源是一个csv格式的时候,想清楚出发点是什么,项目背景是怎样的,以哪个为切入点。
1. Tableau做猜想预测
分成两大块,从人口特征和消费服务特征来做分析
利用Tableau做项目预测猜想,因为这个项目是一个简单的二分类,分类标准是Churn是否会流失,所以Churn是标签类别

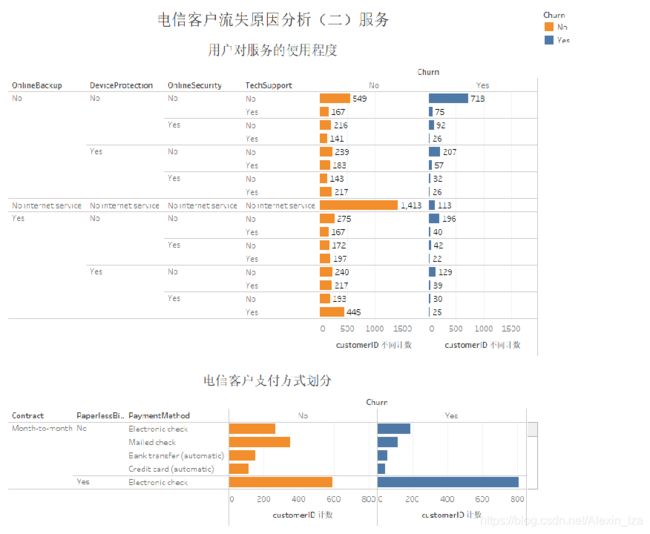 得出结论:
得出结论:
1、没有子女、没有伴侣的老年用户流失率比较高
2、老年用户中流失用户的月度平均消费均比未流失用户要高17%的总价
3、从流失的人群中发现平均使用的时间占比少、月度花费比较高
4、流失的客户中大多数都是使用Fiber optic的网络服务、DSL的电话服务,进一步推断Fiber optic的网络服务的故障率比较高,加强客户售后意识,定期查询网络故障并及时修复。
5、流失的客户里面大部分都不使用OnlineBackup、DeviceProtection、OnlineSecurtiy、TechSupport服务
6、流失的人群里面大多数都是用月度支付的无纸化电子支票的支付方式,进一步推断由于支付方式比较繁琐,导致客户支付不便利。
对于上述观点,我采用了以下的数学模型来做分析依据:
其中由于决策树更加直观可以看到客户流失与哪些相关因素有关,下面是对上述分析的佐证。
2、代码实现
数据集分类:
数据划分处理:将数据分为3类
1、二分类数据:Yes/No转换为1/0,Yes=1/No、No services=0
 2、离散型标签分类:将标签重新开设一列,作为0/1分类的标准
2、离散型标签分类:将标签重新开设一列,作为0/1分类的标准
3、数值型分类,其数据内容具备顺序以及加减运算的数值意义。目前属于这类特征的变量有:已使用年限,月消费。我打算采用连续特征离散化的处理方式。原因是离散化后的特征对异常数据有更强的鲁棒性,降低过拟合的风险,模型会更稳定,预测的效果也会更好。
数据离散化也称为分箱操作,其方法分为有监督分箱(卡方分箱、最小熵法分箱)和无监督分箱(等频分箱、等距分箱)。本次为采用无监督分箱中的等频分箱进行操作。下图以Tenure为例

#将CSV数据集导入
from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#整理数据
TargetData=pd.read_csv('telecom_churn.csv')
#数据集大小
print(TargetData.shape)
#数据集是否有缺失值
print(TargetData.isnull().sum())
#检查数据类型
print(TargetData.dtypes)
#检查数据是否包含空字符
print(TargetData[TargetData['TotalCharges'].isin([' '])])
#修复错误输入的数据集:
TargetData.replace(to_replace=r'^\s*$',value=np.nan,regex=True,inplace=True)
TargetData.dropna(axis=0, how='any', inplace=True)
TargetData['TotalCharges']=pd.to_numeric(TargetData['TotalCharges'])
TargetData.describe(include='all')
#将PaymentMethod ,OnlineSecurity,OnlineBackup,DeviceProtection ,TechSupport 转化为0-1编码
from sklearn.preprocessing import LabelEncoder
encoder=LabelEncoder()
colLabel=['gender','Partner', 'Dependents', 'PhoneService','PaperlessBilling','Churn']
for i in colLabel:
TargetData[i]=encoder.fit_transform(TargetData[i])
#设定规则将3个不同类的设置为0-1数据
Dependents_mapDict={
'Yes':1,'No':0,'No internet service':0}
for j in ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies']:
TargetData[j]=TargetData[j].map(Dependents_mapDict)
TargetData.head()
OneHotLabel=['MultipleLines', 'InternetService', 'Contract','PaymentMethod']
#对客户的合同期进行One-Hot编码
for i in OneHotLabel:
ContractDF=pd.DataFrame()
ContractDF=pd.get_dummies(TargetData[i],prefix='Contract')
ContractDF.head()
#添加虚拟变量至原数据集并删除原有数据列
TargetData=pd.concat([TargetData,ContractDF],axis=1)
TargetData.drop([i],axis=1,inplace=True)
TargetData
TargetData.to_excel('ChurnLabel_A.xls')
# 模型构建
## 尝试采用决策树这种经典的二分类模型作为咱们的机器学习模型。决策树的优点在于模型容易理解以及能够可视化,更能了解哪些特征对输出结果影响较大。但是缺点也十分明显,就是容易过拟合,泛化性能差。
# def plot_feature_importance(model):
n_features = data_frame.shape[1]
plt.barh(range(n_features-1),model.feature_importances_,align='center')
plt.yticks(range(n_features-1),data_frame.columns[1:])
plt.xlabel('Features importance')
plt.ylabel('feature')
plot_feature_importance(tree)
plt.show()
#数据集大小
print(TargetData.shape)
#数据集是否有缺失值
print(TargetData.isnull().sum())
#检查数据类型
print(TargetData.dtypes)
#检查数据是否包含空字符
print(TargetData[TargetData['TotalCharges'].isin([' '])])
#修复错误输入的数据集
TargetData.replace(to_replace=r'^\s*$',value=np.nan,regex=True,inplace=True)
TargetData.dropna(axis=0, how='any', inplace=True)
TargetData['TotalCharges']=pd.to_numeric(TargetData['TotalCharges'])
TargetData.describe(include='all')
利用pandas库导入数据python的时候发现有异常,再回到数据源,发现TotalCharges其中有5空字符,因为缺失的数据无法根据其他数据源可以补全数据,直接在导入python后删除
import pandas as pd
import numpy as np
Te_data = pd.read_csv('telecom_churn.csv')
Te_data.replace(to_replace=r'^\s*$',value=np.nan,regex=True,inplace=True)
Te_data.dropna(axis=0, how='any', inplace=True)
Te_data['TotalCharges'] = pd.to_numeric(Te_data['TotalCharges'])
SeniorCitizen=list(Te_data['SeniorCitizen'])
Churn=list(Te_data['Churn'])
#将Churn转化为0-1变量
for i in range(Te_data.shape[0]):
if Churn[i]=='Yes':
Churn[i] = 1
else :
Churn[i] = 0
Contract=Te_data['Contract']
Contract_dummies=pd.get_dummies(Contract)
InternetService=Te_data['InternetService']
InternetService_dummies=pd.get_dummies(InternetService)
#将PaymentMethod ,OnlineSecurity,OnlineBackup,DeviceProtection ,TechSupport 转化为0-1编码
PaymentMethod=list(Te_data['PaymentMethod'])
OnlineSecurity=list(Te_data['OnlineSecurity'])
OnlineBackup=list(Te_data['OnlineBackup'])
DeviceProtection=list(Te_data['DeviceProtection'])
TechSupport=list(Te_data['TechSupport'])
for i in range(Te_data.shape[0]):
if PaymentMethod[i]=='Electronic check':
PaymentMethod[i] = 1
else :
PaymentMethod[i] = 0
if OnlineSecurity[i]=='Yes':
OnlineSecurity[i] = 1
else :
OnlineSecurity[i] = 0
if OnlineBackup[i]=='Yes':
OnlineBackup[i] = 1
else :
OnlineBackup[i] = 0
if DeviceProtection[i]=='Yes':
DeviceProtection[i] = 1
else :
DeviceProtection[i] = 0
if TechSupport[i]=='Yes':
TechSupport[i] = 1
else :
TechSupport[i] = 0
tenure=list(Te_data['tenure'])
tenure_cats=pd.qcut(tenure,6)
tenure_dummies=pd.get_dummies(tenure_cats)
MonthlyCharges=list(Te_data['MonthlyCharges'])
MonthlyCharges_cats=pd.qcut(MonthlyCharges,5)
MonthlyCharges_dummies=pd.get_dummies(MonthlyCharges_cats)
#模型输出y
Churn_y=np.array(Churn).reshape(-1,1)
dataY=pd.DataFrame(Churn_y)
dataY.to_csv('Save_y.csv')
#模型输入x
SeniorCitizen_x=np.array(SeniorCitizen).reshape(-1,1)
Contract_x=Contract_dummies.values
InternetService_x=InternetService_dummies.values
PaymentMethod_x=np.array(PaymentMethod).reshape(-1,1)
OnlineSecurity_x=np.array(OnlineSecurity).reshape(-1,1)
OnlineBackup_x=np.array(OnlineBackup).reshape(-1,1)
DeviceProtection_x=np.array(DeviceProtection).reshape(-1,1)
TechSupport_x=np.array(TechSupport).reshape(-1,1)
tenure_x=tenure_dummies.values
MonthlyCharges_x=MonthlyCharges_dummies.values
X=np.concatenate([SeniorCitizen_x,Contract_x,InternetService_x,PaymentMethod_x,OnlineSecurity_x,OnlineBackup_x,DeviceProtection_x,TechSupport_x,tenure_x,MonthlyCharges_x],axis=1)
#模型输出,整理数据集
dataX=pd.DataFrame(data=X,columns=['SeniorCitizen','Contract_Month-to-Month','Contract_oneYear','Contract_twoYear','InternetService_no','InternetService_opti','InternetService_DSL','PaymentMethod','OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','tenure_0.999, 4.0','tenure_4.0, 14.0','tenure_14.0, 29.0','tenure_29.0, 47.0','tenure_47.0, 64.0','tenure_64.0, 72.0','MonthlyCharges_18.249, 25.05','MonthlyCharges_25.05, 58.92','MonthlyCharges_58.92, 79.15','MonthlyCharges_79.15, 94.3','MonthlyCharges_94.3, 118.75'])
dataX.to_csv('Save_X.csv')
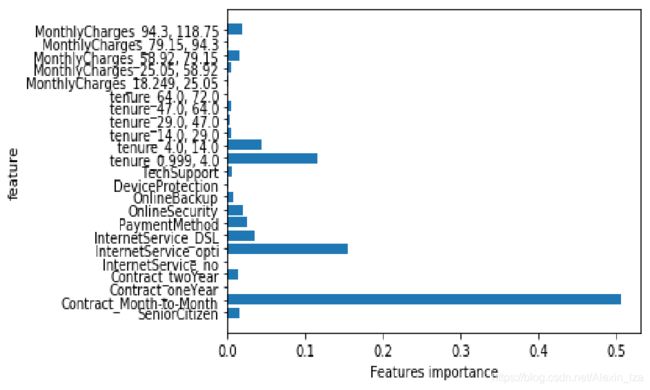
2.1模型设计
#数据导入
import pandas as pd
import numpy as np
data_frame=pd.read_csv("Save_X.csv")
X=np.array(data_frame.values[:,1:])
data_frame2=pd.read_csv("Save_y.csv")
y=np.array(data_frame2.values[:,1:])
#模型训练
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
x_train, x_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
tree = DecisionTreeClassifier(max_depth=6,random_state=0)
tree.fit(x_train,y_train)
clf=tree.fit(x_train,y_train)
print("training set score:{:.3f}".format(tree.score(x_train, y_train)))
print("test set score:{:.3f}".format(tree.score(x_test, y_test)))
print("Feature importances : \n{}".format(tree.feature_importances_))
#特征重要性可视化
import matplotlib.pyplot as plt
def plot_feature_importance(model):
n_features = data_frame.shape[1]
plt.barh(range(n_features-1),model.feature_importances_,align='center')
plt.yticks(range(n_features-1),data_frame.columns[1:])
plt.xlabel('Features importance')
plt.ylabel('feature')
plot_feature_importance(tree)
plt.show()
#决策树可视化
from sklearn.tree import export_graphviz
import pydot
import graphviz
from sklearn.externals.six import StringIO
dot_data=StringIO()
export_graphviz(clf,out_file=dot_data,class_names=['Churn_no','Churn_yes'],feature_names=data_frame.columns[1:],filled=True, rounded=True,special_characters=True)
#with open("te_tree.dot") as f:
# dot_graph=f.read()
graph=pydot.graph_from_dot_data(dot_data.getvalue())
graph[0].write_pdf("tree.pdf")
决策树最终效果:
 决策树解释:
决策树解释:
gini基尼系数:数值越小,分类均分越平均
samples:样本数
class:分类:是否流失——yes表示流失
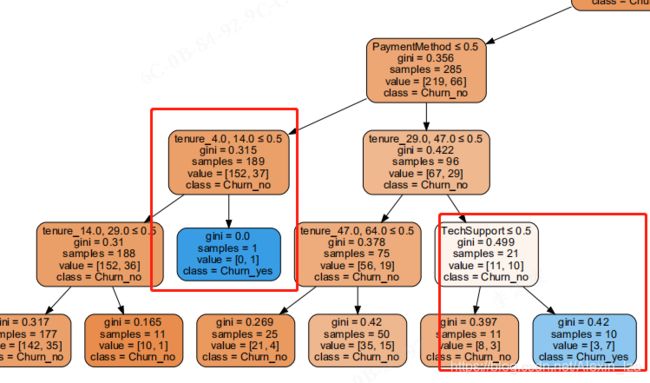
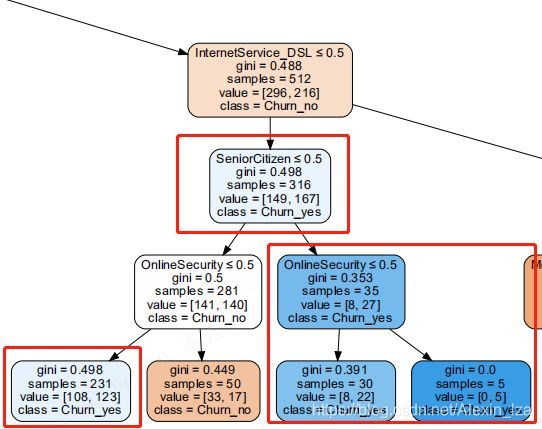
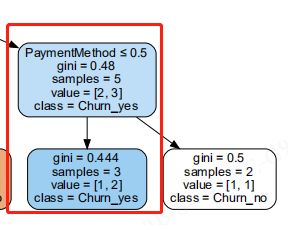
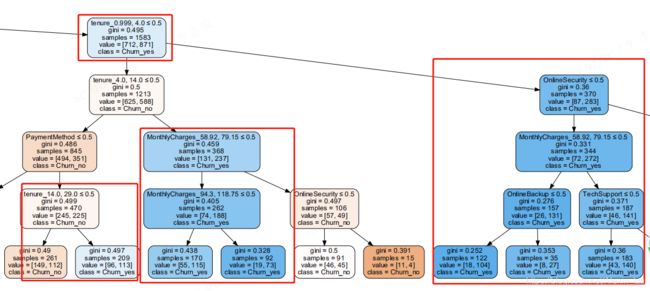
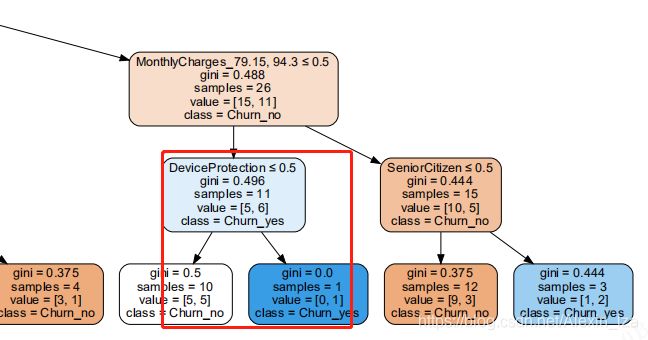
最终被划分为客户流失的因素标签是tenure、TechSupport、SeniorCitizen、OnlineSecurity、PaymentMethod、MonthlyCharges、TechSupport、OnlineBackup、DeviceProtection
与上面用Tebleau分析的项目是一致的。
3、预防措施及建议
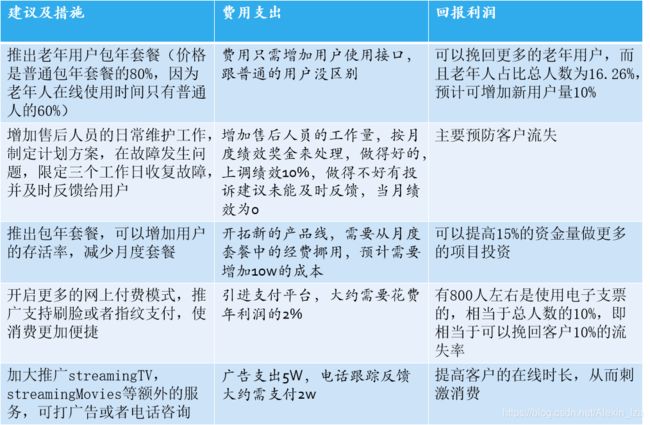
遇到问题:附有相关博客链接
1、graphviz无法启动,转换dot格式无法转换为pdf:https://blog.csdn.net/jingsiyu6588/article/details/88966820
2、思路及代码参考的博客:https://blog.csdn.net/gdben_user/article/details/105653763