01_Flink基础介绍
Flink基础介绍
1. Flink介绍
1.1. Flink引入
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了4 代,当然也有很多人不会认同。我们先姑且这么认为和讨论。
第1代——Hadoop MapReduce
-
批处理
-
Mapper、Reducer
Hadoop的MapReduce将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个Job的串联,以完成一个完整的算法,例如迭代计算。
第2代——DAG框架(Tez) + MapReduce
-
批处理
-
1个Tez = MR(1) + MR(2) + … + MR(n)
-
相比MR效率有所提升

第3代——Spark
- 批处理、流处理、SQL高层API支持
- 自带DAG
- 内存迭代计算、性能较之前大幅提升
第4代——Flink
- 批处理、流处理、SQL高层API支持
- 自带DAG
- 流式计算性能更高、可靠性更高
1.2. 什么是Flink
Flink概述:
- 分布式的
计算引擎 - 支持
批处理,即处理静态的数据集、历史的数据集 - 支持
流处理,即实时地处理一些实时数据流 - 支持
基于事件的应用【比如说滴滴通过Flink CEP实现实时监测司机的行为流来判断司机的行为是否正当】
官网地址: https://flink.apache.org/
官网介绍:
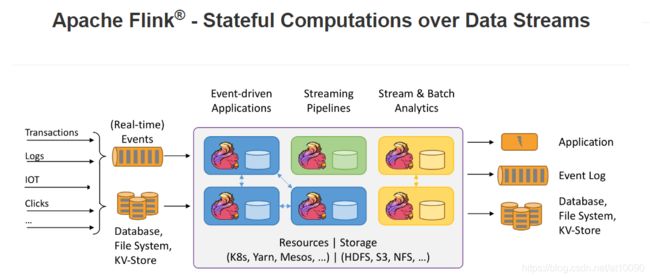
Stateful Computations over Data Streams,即数据流上的有状态的计算。
-
Data Streams ,Flink认为
有界数据集是无界数据流的一种特例,所以说有界数据集也是一种数据流,事件流也是一种数据流。Everything is streams,即Flink可以用来处理任何的数据,可以支持批处理、流处理、AI、MachineLearning等等。 -
Stateful Computations,即
有状态计算。有状态计算是最近几年来越来越被用户需求的一个功能。比如说一个网站一天内访问UV数,那么这个UV数便为状态。Flink提供了内置的对状态的一致性的处理,即如果任务发生了Failover,其状态不会丢失、不会被多算少算,同时提供了非常高的性能。
无界流:意思很明显,只有开始没有结束。必须连续的处理无界流数据,也即是在事件注入之后立即要对其进行处理。不能等待数据到达了再去全部处理,因为数据是无界的并且永远不会结束数据注入。处理无界流数据往往要求事件注入的时候有一定的顺序性,例如可以以事件产生的顺序注入,这样会使得处理结果完整。
有界流:也即是有明确的开始和结束的定义。有界流可以等待数据全部注入完成了再开始处理。注入的顺序不是必须的了,因为对于一个静态的数据集,我们是可以对其进行排序的。有界流的处理也可以称为批处理。
其它特点:
- 性能优秀(尤其在流计算领域)
- 高可扩展性
- 支持容错
纯内存式的计算引擎,做了内存管理方面的大量优化- 支持
eventime的处理 - 支持超大状态的Job(在阿里巴巴中作业的state大小超过TB的是非常常见的)
- 支持
exactly-once的处理。
1.3. 性能比较
首先,我们可以通过下面的性能测试初步了解两个框架的性能区别,它们都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Flink计算性能上略好。
测试环境:
1.CPU:7000个;
2.内存:单机128GB;
3.版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
4.数据:800MB,8GB,8TB;
5.算法:K-means:以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
6.迭代:K=10,3组数据
测试结果:
纵坐标是秒,横坐标是次数
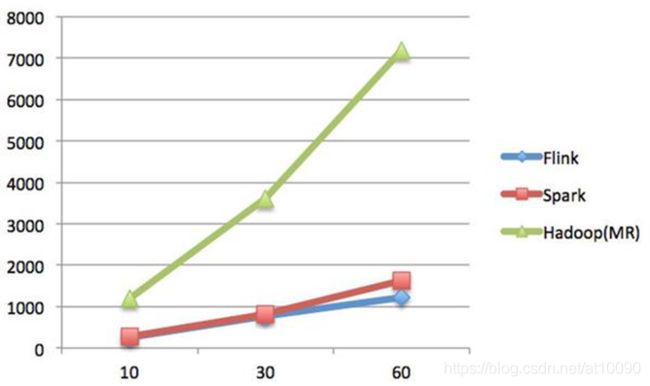
结论:
Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数越多越明显
性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能
1.4. 发展历史

2008年,Flink 的前身已经是柏林理工大学一个研究性项目,原名 StratoSphere。
2014年,Flink被Apache孵化器所接受然后迅速地成为了 ASF(Apache Software Foundation)的顶级项目之一。
最新版本已经到了1.8.0
本次课程基于flink-1.6.1开发
spark是2009年诞生在
加州大学伯克利分校的AMP实验室,2013年开源成为Apache孵化项目
1.5. Flink在阿里的现状
基于Apache Flink在阿里巴巴搭建的平台于2016年正式上线,并从阿里巴巴的搜索和推荐这两大场景开始实现。
目前阿里巴巴所有的业务,包括阿里巴巴所有子公司都采用了基于Flink搭建的实时计算平台。
同时Flink计算平台运行在开源的Hadoop集群之上。
采用Hadoop的YARN做为资源管理调度,以 HDFS作为数据存储。
因此,Flink可以和开源大数据软件Hadoop无缝对接。

目前,这套基于Flink搭建的实时计算平台不仅服务于阿里巴巴集团内部,而且通过阿里云的云产品API向整个开发者生态提供基于Flink的云产品支持。
Flink在阿里巴巴的大规模应用,表现如何?
- 规模:一个系统是否成熟,规模是重要指标,Flink最初上线阿里巴巴只有数百台服务器,目前规模已达上万台,此等规模在全球范围内也是屈指可数;
- 状态数据:基于Flink,内部积累起来的状态数据已经是PB级别规模;
- Events:如今每天在Flink的计算平台上,处理的数据已经超过万亿条;
- TPS:在峰值期间可以承担每秒超过4.72亿次的访问,最典型的应用场景是
阿里巴巴双11大屏;


Flink分支Blink
- 阿里自15年起开始调研开源流计算引擎,最终决定基于Flink打造新一代计算引擎
- 阿里贡献了数百个commiter,并对Flink进行高度定制,并取名为
Blink - 阿里是
Flink SQL的最大贡献者,一半以上的功能都是阿里的工程师开发的
logo介绍

在德语中,flink 一词表示快速和灵巧 , 松鼠具有快速和灵巧的特点
柏林的松鼠是红棕色,Flink的松鼠 logo尾巴的颜色与 Apache 软件基金会的 logo 颜色相呼应
2. Flink集群安装
Flink支持多种安装模式
- local(本地)——单机模式,一般不使用
- standalone——独立模式,Flink自带集群,开发测试环境使用
- yarn——计算资源统一由Hadoop YARN管理,生产测试环境使用
2.1. 伪分布环境部署
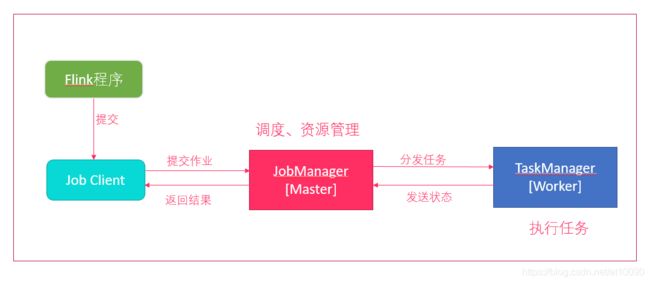
- Flink程序需要提交给
Job Client - Job Client将作业提交给
Job Manager - Job Manager负责协调资源分配和作业执行。 资源分配完成后,任务将提交给相应的
Task Manager - Task Manager启动一个线程以开始执行。Task Manager会向Job Manager报告状态更改。例如开始执行,正在进行或已完成。
- 作业执行完成后,结果将发送回客户端(Job Client)
环境准备:
- 下载安装包 https://archive.apache.org/dist/flink/flink-1.6.1/flink-1.6.1-bin-hadoop27-scala_2.11.tgz
- 服务器: node01 (192.168.100.100)
安装步骤:
-
上传压缩包
-
解压
tar -zxvf flink-1.6.1-bin-hadoop27-scala_2.11.tgz -C /export/servers/ -
启动
cd /export/servers/flink-1.6.1 ./bin/start-cluster.sh使用JPS可以查看到下面两个进程
-
TaskManagerRunner
-
StandaloneSessionClusterEntrypoint
-
-
访问web界面
http://node01:8081
slot在flink里面可以认为是资源组,Flink是通过将任务分成子任务并且将这些子任务分配到slot来并行执行程序。 -
运行测试任务
bin/flink run /export/servers/flink-1.6.1/examples/batch/WordCount.jar --input /export/servers/zookeeper-3.4.9/zookeeper.out --output /export/servers/flink_data控制台输出:
Starting execution of program
Program execution finished
Job with JobID bb53dc79d510202e8abd95094791a32b has finished.
Job Runtime: 9539 ms
观察WebUI

2.2. Standalone模式集群安装部署
Standalone集群架构
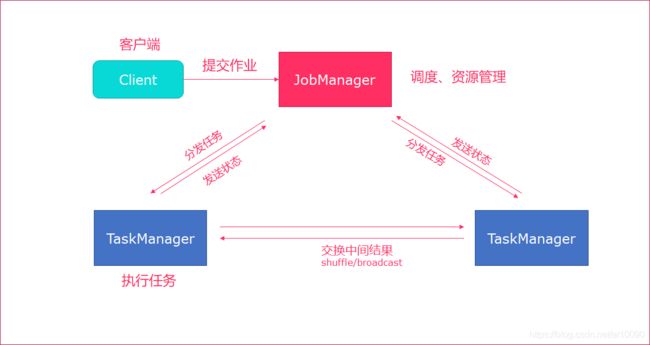
- client客户端提交任务给JobManager
- JobManager负责Flink集群计算资源管理,并分发任务给TaskManager执行
- TaskManager定期向JobManager汇报状态
环境准备:
- 服务器: node01(Master + Slave)
- 服务器: node02(Slave)
- 服务器: node03(Slave)
安装步骤:
-
上传flink压缩包到指定目录
-
解压缩flink到
/export/servers目录tar -xvzf flink-1.6.1-bin-hadoop27-scala_2.11.tgz -C /export/servers/ -
使用vi修改
conf/flink-conf.yaml# jobManager 的IP地址 jobmanager.rpc.address: node01 # JobManager 的端口号 jobmanager.rpc.port: 6123 # JobManager JVM heap 内存大小 jobmanager.heap.size: 1024 # TaskManager JVM heap 内存大小 taskmanager.heap.size: 1024 # 每个 TaskManager 提供的任务 slots 数量大小 taskmanager.numberOfTaskSlots: 2 #是否进行预分配内存,默认不进行预分配,这样在我们不使用flink集群时候不会占用集群资源 taskmanager.memory.preallocate: false # 程序默认并行计算的个数 parallelism.default: 1 #JobManager的Web界面的端口(默认:8081) jobmanager.web.port: 8081 #配置每个taskmanager生成的临时文件目录(选配) taskmanager.tmp.dirs: /export/servers/flink-1.6.1/tmpslot和parallelism总结
taskmanager.numberOfTaskSlots:2
每一个taskmanager中的分配2个TaskSlot,3个taskmanager一共有6个TaskSlot
parallelism.default:1
运行程序默认的并行度为1,6个TaskSlot只用了1个,有5个空闲slot是静态的概念,是指taskmanager具有的并发执行能力parallelism是动态的概念,是指程序运行时实际使用的并发能力
-
使用vi修改slaves文件
node01 node02 node03 -
使用vi修改
/etc/profile系统环境变量配置文件,添加HADOOP_CONF_DIR目录export HADOOP_CONF_DIR=/export/servers/hadoop-2.7.5/etc/hadoop -
分发/etc/profile到其他两个节点
scp -r /etc/profile node02:/etc scp -r /etc/profile node03:/etc -
每个节点重新加载环境变量
source /etc/profile -
使用scp命令分发flink到其他节点
scp -r /export/servers/flink-1.6.1/ node02:/export/servers/ scp -r /export/servers/flink-1.6.1/ node03:/export/servers/ -
启动Flink集群
./bin/start-cluster.sh启动/停止flink集群
-
启动:./bin/start-cluster.sh
-
停止:./bin/stop-cluster.sh
启动/停止jobmanager
如果集群中的jobmanager进程挂了,执行下面命令启动-
bin/jobmanager.sh start
-
bin/jobmanager.sh stop
启动/停止taskmanager
添加新的taskmanager节点或者重启taskmanager节点- bin/taskmanager.sh start
- bin/taskmanager.sh stop
-
-
启动HDFS集群
cd /export/servers/hadoop-2.7.5/sbin start-all.sh -
在HDFS中创建/test/input目录
hdfs dfs -mkdir -p /test/input -
上传wordcount.txt文件到HDFS /test/input目录
hdfs dfs -put /export/servers/flink-1.6.1/README.txt /test/input -
并运行测试任务
bin/flink run /export/servers/flink-1.6.1/examples/batch/WordCount.jar --input hdfs://node01:8020/test/input/README.txt --output hdfs://node01:8020/test/output2/result.txt -
浏览Flink Web UI界面
http://node01:8081
2.3. Standalone高可用HA模式
从上述架构图中,可发现JobManager存在单点故障,一旦JobManager出现意外,整个集群无法工作。所以,为了确保集群的高可用,需要搭建Flink的HA。
HA架构图

环境准备:
- 服务器: node01(Master + Slave)
- 服务器: node02(Master + Slave)
- 服务器: node03(Slave)
安装步骤
-
在flink-conf.yaml中添加zookeeper配置
#开启HA,使用文件系统作为快照存储 state.backend: filesystem #启用检查点,可以将快照保存到HDFS state.backend.fs.checkpointdir: hdfs://node01:8020/flink-checkpoints #使用zookeeper搭建高可用 high-availability: zookeeper # 存储JobManager的元数据到HDFS high-availability.storageDir: hdfs://node01:8020/flink/ha/ high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181 -
将配置过的HA的
flink-conf.yaml分发到另外两个节点scp -r /export/servers/flink-1.6.1/conf/flink-conf.yaml node02:/export/servers/flink-1.6.1/conf/ scp -r /export/servers/flink-1.6.1/conf/flink-conf.yaml node03:/export/servers/flink-1.6.1/conf/ -
到节点2中修改flink-conf.yaml中的配置,将JobManager设置为自己节点的名称
jobmanager.rpc.address: node02 -
在node01的
masters配置文件中添加多个节点node01:8081 node02:8081 -
分发masters配置文件到另外两个节点
scp /export/servers/flink-1.6.1/conf/masters node02:/export/servers/flink-1.6.1/conf/ scp /export/servers/flink-1.6.1/conf/masters node03:/export/servers/flink-1.6.1/conf/ -
启动
zookeeper集群 -
启动
HDFS集群 -
启动
flink集群 -
分别查看两个节点的Flink Web UI
-
kill掉一个节点,查看另外的一个节点的Web UI
注意事项
切记搭建HA,需要将第二个节点的
jobmanager.rpc.address修改为node02
2.4. Yarn集群环境
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的 Workload。因此 Flink 也支持在Yarn上面运行;flink on yarn的前提是:hdfs、yarn均启动
集群规划
JobManager: node01
WorkManager: node01 node02 node03
步骤
-
修改Hadoop的yarn-site.xml,添加该配置表示内存超过分配值,是否将任务杀掉。默认为true。
运行Flink程序,很容易超过分配的内存。
<property> <name>yarn.nodemanager.vmem-check-enabledname> <value>falsevalue> property> -
分发yarn-site.xml到其它服务器节点
scp yarn-site.xml node02:$PWD scp yarn-site.xml node03:$PWD -
启动HDFS、YARN集群
start-all.sh
2.5. yarn-session
Flink运行在YARN上,可以使用yarn-session来快速提交作业到YARN集群。我们先来看下Flink On Yarn模式,Flink是如何和Yarn进行交互的。

-
上传jar包和配置文件到HDFS集群上
-
申请资源和请求AppMaster容器
-
Yarn分配资源AppMaster容器,并启动JobManager
JobManager和ApplicationMaster运行在同一个container上。 一旦他们被成功启动,AppMaster就知道JobManager的地址(AM它自己所在的机器)。 它就会为TaskManager生成一个新的Flink配置文件(他们就可以连接到JobManager)。 这个配置文件也被上传到HDFS上。 此外,AppMaster容器也提供了Flink的web服务接口。 YARN所分配的所有端口都是临时端口,这允许用户并行执行多个Flink -
申请worker资源,启动TaskManager

yarn-session提供两种模式: 会话模式和分离模式
2.6. 会话模式
- 使用Flink中的yarn-session(yarn客户端),会启动两个必要服务
JobManager和TaskManager - 客户端通过yarn-session提交作业
- yarn-session会一直启动,不停地接收客户端提交的作用
- 有大量的小作业,适合使用这种方式
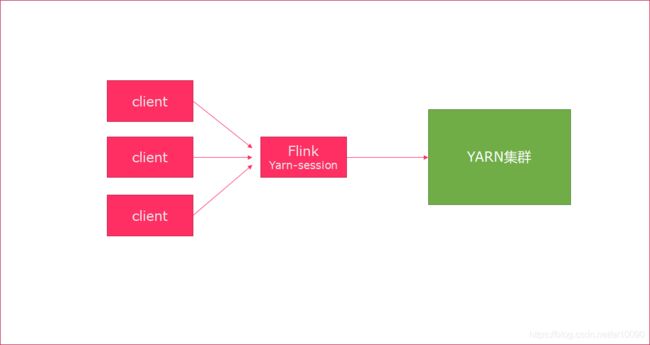
使用步骤:
-
在flink目录启动yarn-session
bin/yarn-session.sh -n 2 -tm 800 -s 1 -d # -n 表示申请2个容器, # -s 表示每个容器启动多少个slot # -tm 表示每个TaskManager申请800M内存 # -d 表示以后台程序方式运行 yarn-session.sh脚本可以携带的参数: Required -n,--container <arg> 分配多少个yarn容器 (=taskmanager的数量) Optional -D <arg> 动态属性 -d,--detached 独立运行 (以分离模式运行作业) -id,--applicationId <arg> YARN集群上的任务id,附着到一个后台运行的yarn session中 -j,--jar <arg> Path to Flink jar file -jm,--jobManagerMemory <arg> JobManager的内存 [in MB] -m,--jobmanager <host:port> 指定需要连接的jobmanager(主节点)地址 使用这个参数可以指定一个不同于配置文件中的jobmanager -n,--container <arg> 分配多少个yarn容器 (=taskmanager的数量) -nm,--name <arg> 在YARN上为一个自定义的应用设置一个名字 -q,--query 显示yarn中可用的资源 (内存, cpu核数) -qu,--queue <arg> 指定YARN队列 -s,--slots <arg> 每个TaskManager使用的slots数量 -st,--streaming 在流模式下启动Flink -tm,--taskManagerMemory <arg> 每个TaskManager的内存 [in MB] -z,--zookeeperNamespace <arg> 针对HA模式在zookeeper上创建NameSpace -
使用flink提交任务
bin/flink run examples/batch/WordCount.jar -
如果程序运行完了,可以使用
yarn application -kill application_id杀掉任务yarn application -kill application_1554377097889_0002
2.7. 分离模式
- 直接提交任务给YARN
- 大作业,适合使用这种方式

-
使用flink直接提交任务
bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar # -m jobmanager的地址 # -yn 表示TaskManager的个数 -
查看WEB UI
3. Flink架构介绍
3.1. Flink基石
Flink之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、Window。
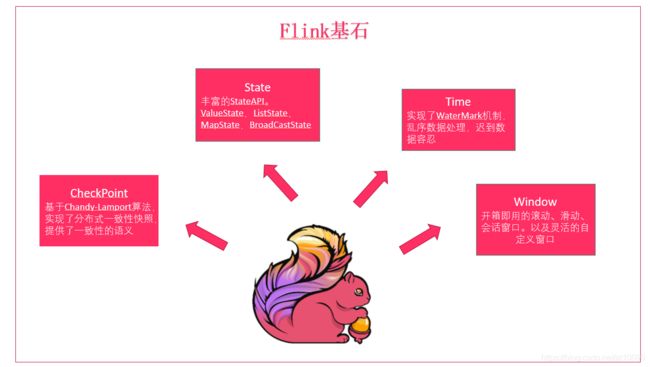
首先是Checkpoint机制,这是Flink最重要的一个特性。Flink基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义。Chandy-Lamport算法实际上在1985年的时候已经被提出来,但并没有被很广泛的应用,而Flink则把这个算法发扬光大了。Spark最近在实现Continue streaming,Continue streaming的目的是为了降低它处理的延时,其也需要提供这种一致性的语义,最终采用Chandy-Lamport这个算法,说明Chandy-Lamport算法在业界得到了一定的肯定。
提供了一致性的语义之后,Flink为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State API,包括里面的有ValueState、ListState、MapState,近期添加了BroadcastState,使用State API能够自动享受到这种一致性的语义。
除此之外,Flink还实现了Watermark的机制,能够支持基于事件的时间的处理,或者说基于系统时间的处理,能够容忍数据的迟到、容忍乱序的数据。
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
3.2. 组件栈
Flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。Flink分层的组件栈如下图所示:

从下至上:
- 部署层:Flink 支持本地运行、能在独立集群或者在被 YARN 管理的集群上运行, 也能部署在云上。
- 运行时:Runtime层提供了支持Flink计算的全部核心实现,为上层API层提供基础服务。
- API:DataStream、DataSet、Table、SQL API。
- 扩展库:Flink 还包括用于复杂事件处理,机器学习,图形处理和 Apache Storm 兼容性的专用代码库。
3.3. Flink数据流编程模型抽象级别
Flink 提供了不同的抽象级别以开发流式或批处理应用。

-
最底层提供了有状态流。它将通过 过程函数(Process Function)嵌入到 DataStream API 中。它允许用户可以自由地处理来自一个或多个流数据的事件,并使用一致、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现复杂的计算。
-
DataStream / DataSet API 是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换 / 计算。
-
Table API 是以 表 为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。你可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
-
Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
3.4. Flink程序结构
Flink程序的基本构建块是流和转换(请注意,Flink的DataSet API中使用的DataSet也是内部流 )。从概念上讲,流是(可能永无止境的)数据记录流,而转换是将一个或多个流作为一个或多个流的操作。输入,并产生一个或多个输出流。

Flink 应用程序结构就是如上图所示:
Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、RabbitMQ 等,当然你也可以定义自己的 source。
Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select等,操作很多,可以将数据转换计算成你想要的数据。
Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
3.5. Flink并行数据流
Flink程序在执行的时候,会被映射成一个Streaming Dataflow,一个Streaming Dataflow是由一组Stream和Transformation Operator组成的。在启动时从一个或多个Source Operator开始,结束于一个或多个Sink Operator。
Flink程序本质上是并行的和分布式的,在执行过程中,一个流(stream)包含一个或多个流分区,而每一个operator包含一个或多个operator子任务。操作子任务间彼此独立,在不同的线程中执行,甚至是在不同的机器或不同的容器上。operator子任务的数量是这一特定operator的并行度。相同程序中的不同operator有不同级别的并行度。
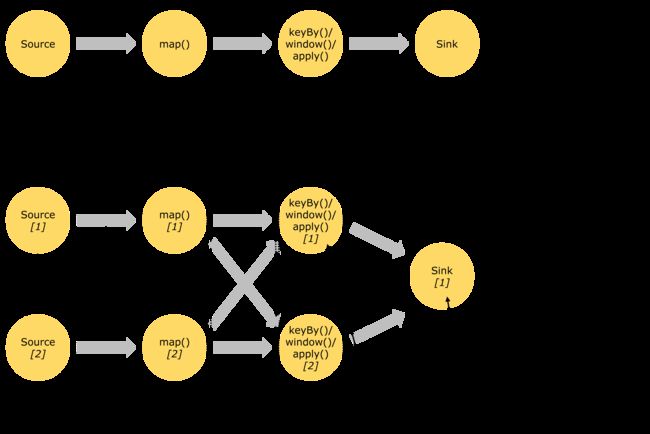
一个Stream可以被分成多个Stream的分区,也就是Stream Partition。一个Operator也可以被分为多个Operator Subtask。如上图中,Source被分成Source1和Source2,它们分别为Source的Operator Subtask。每一个Operator Subtask都是在不同的线程当中独立执行的。一个Operator的并行度,就等于Operator Subtask的个数。上图Source的并行度为2。而一个Stream的并行度就等于它生成的Operator的并行度。
数据在两个operator之间传递的时候有两种模式:
One to One模式:两个operator用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的Source1到Map1,它就保留的Source的分区特性,以及分区元素处理的有序性。
Redistributing (重新分配)模式:这种模式会改变数据的分区数;每个一个operator subtask会根据选择transformation把数据发送到不同的目标subtasks,比如keyBy()会通过hashcode重新分区,broadcast()和rebalance()方法会随机重新分区;
3.6. Task和Operator chain
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。

3.7. 任务调度与执行

- 当Flink执行executor会自动根据程序代码生成DAG数据流图
- ActorSystem创建Actor将数据流图发送给JobManager中的Actor
- JobManager会不断接收TaskManager的心跳消息,从而可以获取到有效的TaskManager
- JobManager通过调度器在TaskManager中调度执行Task(在Flink中,最小的调度单元就是task,对应就是一个线程)
- 在程序运行过程中,task与task之间是可以进行数据传输的
-
Job Client
- 主要职责是
提交任务, 提交后可以结束进程, 也可以等待结果返回 - Job Client
不是Flink 程序执行的内部部分,但它是任务执行的起点。 - Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户
- 主要职责是
-
JobManager- 主要职责是调度工作并协调任务做
检查点 - 集群中至少要有一个
master,master 负责调度 task,协调checkpoints 和容错, - 高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是
standby; - Job Manager 包含
Actor System、Scheduler、CheckPoint三个重要的组件 JobManager从客户端接收到任务以后, 首先生成优化过的执行计划, 再调度到TaskManager中执行
- 主要职责是调度工作并协调任务做
-
TaskManager-
主要职责是从
JobManager处接收任务, 并部署和启动任务, 接收上游的数据并处理 -
Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点。
-
TaskManager在创建之初就设置好了Slot, 每个Slot可以执行一个任务
-
3.8. 任务槽(task-slot)和槽共享(Slot Sharing)

每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。
为了控制一个worker能接收多少个task。worker通过task slot来进行控制(一个worker至少有一个task slot)。
每个task slot表示TaskManager拥有资源的一个固定大小的子集。
flink将进程的内存进行了划分到多个slot中。
图中有2个TaskManager,每个TaskManager有3个slot的,每个slot占有1/3的内存。
内存被划分到不同的slot之后可以获得如下好处:
-
TaskManager最多能同时并发执行的任务是可以控制的,那就是3个,因为不能超过slot的数量。
-
slot有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响。
槽共享(Slot Sharing)
默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。允许插槽共享有两个主要好处:
- 只需计算Job中最高并行度(parallelism)的task slot,只要这个满足,其他的job也都能满足。
- 资源分配更加公平,如果有比较空闲的slot可以将更多的任务分配给它。图中若没有任务槽共享,负载不高的Source/Map等subtask将会占据许多资源,而负载较高的窗口subtask则会缺乏资源。
- 有了任务槽共享,可以将基本并行度(base parallelism)从2提升到6.提高了分槽资源的利用率。同时它还可以保障TaskManager给subtask的分配的slot方案更加公平。

3.9. Flink统一的流处理与批处理
在大数据处理领域,批处理任务与流处理任务一般被认为是两种不同的任务
一个大数据框架一般会被设计为只能处理其中一种任务
- Storm只支持流处理任务
- MapReduce、Spark只支持批处理任务
- Spark Streaming是Apache Spark之上支持流处理任务的子系统,看似是一个特例,其实并不是——Spark Streaming采用了一种
micro-batch的架构,即把输入的数据流切分成细粒度的batch,并为每一个batch数据提交一个批处理的Spark任务,所以Spark Streaming本质上还是基于Spark批处理系统对流式数据进行处理,和Storm等完全流式的数据处理方式完全不同。 - Flink通过灵活的执行引擎,能够
同时支持批处理任务与流处理任务
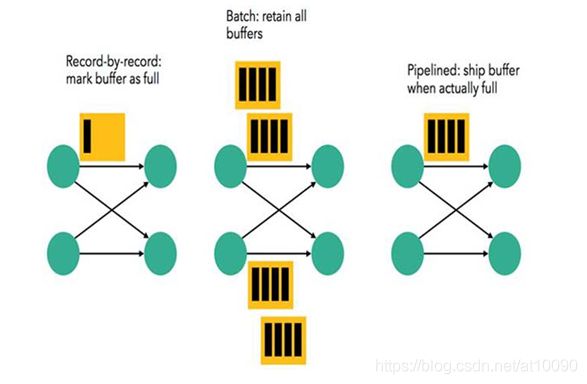
在执行引擎这一层,流处理系统与批处理系统最大不同在于节点间的数据传输方式:
-
对于一个流处理系统,其节点间数据传输的标准模型是:
- 当一条数据被处理完成后,序列化到缓存中,然后立刻通过网络传输到下一个节点,由下一个节点继续处理
-
对于一个批处理系统,其节点间数据传输的标准模型是:
- 当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当
缓存写满,就持久化到本地硬盘上,当所有数据都被处理完成后,才开始将处理后的数据通过网络传输到下一个节点
- 当一条数据被处理完成后,序列化到缓存中,并不会立刻通过网络传输到下一个节点,当
这两种数据传输模式是两个极端,对应的是流处理系统对低延迟的要求和批处理系统对高吞吐量的要求
Flink的执行引擎采用了一种十分灵活的方式,同时支持了这两种数据传输模型
-
Flink以
固定的缓存块为单位进行网络数据传输,用户可以通过设置缓存块超时值指定缓存块的传输时机。如果缓存块的超时值为0,则Flink的数据传输方式类似上文所提到流处理系统的标准模型,此时系统可以获得最低的处理延迟 -
如果缓存块的超时值为无限大,则Flink的数据传输方式类似上文所提到批处理系统的标准模型,此时系统可以获得最高的吞吐量
-
同时缓存块的超时值也可以设置为0到无限大之间的任意值。缓存块的超时阈值越小,则Flink流处理执行引擎的数据处理延迟越低,但吞吐量也会降低,反之亦然。通过调整缓存块的超时阈值,用户可根据需求灵活地权衡系统延迟和吞吐量
3.10. Flink的应用场景

阿里在Flink的应用主要包含四个模块:实时监控、实时报表、流数据分析和实时仓库。
实时监控:
- 用户行为预警、app crash 预警、服务器攻击预警
- 对用户行为或者相关事件进行实时监测和分析,基于风控规则进行预警
实时报表:
- 双11、双12等活动直播大屏
- 对外数据产品:生意参谋等
- 数据化运营
流数据分析:
- 实时计算相关指标反馈及时调整决策
- 内容投放、无线智能推送、实时个性化推荐等
实时仓库:
- 数据实时清洗、归并、结构化
- 数仓的补充和优化
从很多公司的应用案例发现,其实Flink主要用在如下三大场景:
场景一:Event-driven Applications【事件驱动】
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。
在传统架构中,应用需要读写远程事务型数据库。
相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。

典型的事件驱动类应用:
-
欺诈检测(Fraud detection)
-
异常检测(Anomaly detection)
-
基于规则的告警(Rule-based alerting)
-
业务流程监控(Business process monitoring)
-
Web应用程序(社交网络)
场景二:Data Analytics Applications【数据分析】
数据分析任务需要从原始数据中提取有价值的信息和指标。
如下图所示,Apache Flink 同时支持流式及批量分析应用。
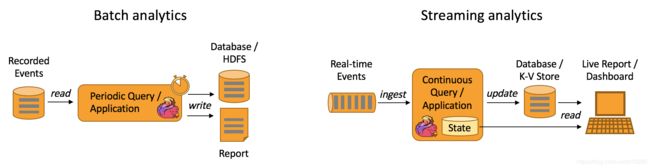
Data Analytics Applications包含Batch analytics(批处理分析)和Streaming analytics(流处理分析)。
Batch analytics可以理解为周期性查询:比如Flink应用凌晨从Recorded Events中读取昨天的数据,然后做周期查询运算,最后将数据写入Database或者HDFS,或者直接将数据生成报表供公司上层领导决策使用。
Streaming analytics可以理解为连续性查询:比如实时展示双十一天猫销售GMV,用户下单数据需要实时写入消息队列,Flink 应用源源不断读取数据做实时计算,然后不断的将数据更新至Database或者K-VStore,最后做大屏实时展示。
典型的数据分析应用实例
- 电信网络质量监控
- 移动应用中的产品更新及实验评估分析
- 消费者技术中的实时数据即席分析
- 大规模图分析
场景三:Data Pipeline Applications【数据管道】
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。
ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。
但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
和周期性 ETL 作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。此外,由于它能够持续消费和发送数据,因此用途更广,支持用例更多。
下图描述了周期性 ETL 作业和持续数据管道的差异。

Periodic ETL:比如每天凌晨周期性的启动一个Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
Data Pipeline:比如启动一个Flink 实时应用,数据源(比如数据库、Kafka)中的数据不断的通过Flink Data Pipeline流入或者追加到数据仓库(数据库或者文件系统),或者Kafka消息队列。
典型的数据管道应用实例
- 电子商务中的实时查询索引构建
- 电子商务中的持续 ETL
思考:
假设你是一个电商公司,经常搞运营活动,但收效甚微,经过细致排查,发现原来是羊毛党在薅平台的羊毛,把补给用户的补贴都薅走了,钱花了不少,效果却没达到。我们应该怎么办呢?
你可以做一个实时的异常检测系统,监控用户的高危行为,及时发现高危行为并采取措施,降低损失。
系统流程:
1.用户的行为经由app上报或web日志记录下来,发送到一个消息队列里去;
2.然后流计算订阅消息队列,过滤出感兴趣的行为,比如:购买、领券、浏览等;
3.流计算把这个行为特征化;
4.流计算通过UDF调用外部一个风险模型,判断这次行为是否有问题(单次行为);
5.流计算里通过CEP功能,跨多条记录分析用户行为(比如用户先做了a,又做了b,又做了3次c),整体识别是否有风险;
6.综合风险模型和CEP的结果,产出预警信息。
- 移动应用中的产品更新及实验评估分析
- 消费者技术中的实时数据即席分析
- 大规模图分析
场景三:Data Pipeline Applications【数据管道】
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。
ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。
但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
和周期性 ETL 作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。此外,由于它能够持续消费和发送数据,因此用途更广,支持用例更多。
下图描述了周期性 ETL 作业和持续数据管道的差异。
[外链图片转存中…(img-Ixmt1enT-1585659814548)]
Periodic ETL:比如每天凌晨周期性的启动一个Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
Data Pipeline:比如启动一个Flink 实时应用,数据源(比如数据库、Kafka)中的数据不断的通过Flink Data Pipeline流入或者追加到数据仓库(数据库或者文件系统),或者Kafka消息队列。
典型的数据管道应用实例
- 电子商务中的实时查询索引构建
- 电子商务中的持续 ETL
思考:
假设你是一个电商公司,经常搞运营活动,但收效甚微,经过细致排查,发现原来是羊毛党在薅平台的羊毛,把补给用户的补贴都薅走了,钱花了不少,效果却没达到。我们应该怎么办呢?
你可以做一个实时的异常检测系统,监控用户的高危行为,及时发现高危行为并采取措施,降低损失。
系统流程:
1.用户的行为经由app上报或web日志记录下来,发送到一个消息队列里去;
2.然后流计算订阅消息队列,过滤出感兴趣的行为,比如:购买、领券、浏览等;
3.流计算把这个行为特征化;
4.流计算通过UDF调用外部一个风险模型,判断这次行为是否有问题(单次行为);
5.流计算里通过CEP功能,跨多条记录分析用户行为(比如用户先做了a,又做了b,又做了3次c),整体识别是否有风险;
6.综合风险模型和CEP的结果,产出预警信息。