- 1 MySQL背景介绍
- 1.1 关于MySQL
- 1.2 MySQL8.0新特性
- 2 CentOS 7.6 安装MySQL
- 2.1 环境准备
- 2.2 配置MySQL远程连接
- 3 MySQL基础知识储备
- 3.1 常用命令
- 登录
- 数据库相关命令
- 数据库表相关命令
- 增删改查命令
- 插入
- 更新
- 删除
- 查询
- 3.2 常用数据类型
- 数值类型
- 日期时间类型
- 字符串类型
- 3.3 运算符
- 算术运算符
- 比较运算符
- 逻辑运算符
- 位运算符
- 运算符优先级
- 3.1 常用命令
- 4 开发规范
- 4.1 设计规范
- 范式
- 范式的问题
- 反范式
- 对比
- 4.2 命名规范
- 4.3 字段规范
- 4.1 设计规范
- 5 B+树索引
- 5.1 什么是索引?
- 5.2 索引目的
- 5.3 B树
- 5.3 B+树
- 5.4 原理分析
- 索引存储位置
- 局部性原理和磁盘预读
- B树如何利用磁盘预读功能
- 为什么B+树比B树更适合作为索引结构
- B+树的叶子结点可以存哪些东西
- 6,SQL优化
- 6.1 优化范围
- 6.2 SQL优化
- 6.3 慢查询语句
- 6.4 常用优化方法
- 7 事务和锁
- 7.1 事务
- 7.1.1 事务存在的原因
- 7.1.2 事务的特性——ACID
- 7.1.3 关于脏读,不可重复读,幻读
- 7.1.4 关于事务隔离级别
- 7.2 锁机制
- 7.2.1 并发控制 控制的是什么?
- 7.2.2 共享锁和排他锁
- 意向共享锁和意向排他锁
- 7.3 死锁
- 7.4 乐观锁与悲观锁
- 乐观锁(适合多读场景)
- 悲观锁(适合多写场景)
- 7.4 乐观锁与悲观锁
- 7.1 事务
1 MySQL背景介绍
1.1 关于MySQL
官方文档:https://dev.mysql.com/doc/refman/8.0/en/
MySQL是Oracle公司开发、发布和支持的最流行的开源SQL数据库管理系统。
【主要特点】
- 开源
- 使用BTree索引
- 支持多线程,对多核CPU性能可以达到更好的发挥
- 用C和C++编写
1.2 MySQL8.0新特性
-
数据字典
详情参考:https://cloud.tencent.com/developer/article/1123363
数据字典存放MySQL元信息:表结构、数据库名或表名、字段的数据类型、视图、索引、表字段信息、存储过程、触发器等。
新版本改进:
- 将所有原先存放于数据字典文件中的信息,全部存放到数据库系统表中(文件-->表)【提升查询数据速度】
- 对INFORMATION_SCHEM,mysql,sys系统库中的存储引擎做了改进,原先使用MyISAM存储引擎的数据字典表都改为使用InnoDB存储引擎存放。
-
更换新的身份认证插件caching_sha2_password【默认使用】,但由于与客户端兼容性不太好,大多数使用者回退到了mysql_native_password版本
-
Innodb增强:
-
自增列【消除了以往重启实例自增列不连续的问题】
-
可禁用死锁检测
一个新的动态变量,
innodb_deadlock_detect,可用于禁用死锁检测。在高并发性系统上,当多个线程等待同一锁时,死锁检测会导致减速。有时,禁用死锁检测并依赖于innodb_lock_wait_timeout在发生死锁时设置事务回滚。
-
2 CentOS 7.6 安装MySQL
2.1 环境准备
首先centos7 已经不支持mysql(大概是因为收费),所以内部集成了mariadb,而安装mysql的话会和mariadb的文件冲突,所以需要先卸载掉mariadb
- 卸载mariadb
rpm -qa | grep mariadb
rpm -e --nodeps mariadb-libs-5.5.60-1.el7_5.x86_64centos7 内部集成了mariadb,而安装mysql的话会和mariadb的文件冲突,所以需要先卸载掉mariadb。
【如果之前安装了mysql需要先卸载】
yum remove mysql*删除安装目录
whereis mysql
rm -rf /usr/share/mysql-
安装MySQL
-
获取yum源(MySQL官网)

-
安装yum源
rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm -
查看各版本启动状况
yum repolist all | grep mysql默认开启最新版8.0
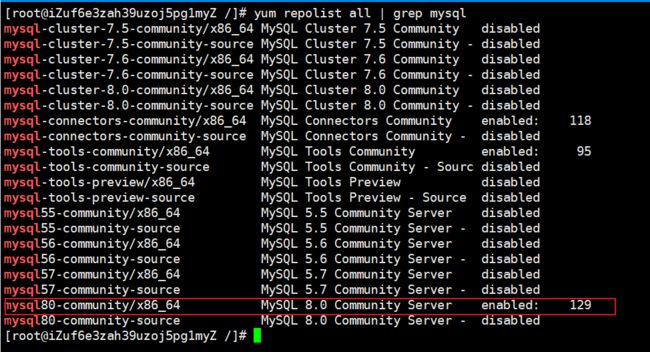
-
[调整命令】禁用8.0,开启5.7
yum-config-manager --disable mysql80-community yum-config-manager --enable mysql57-community命令在yum-utils 包里,安装既可以解决无法找到yum-config-manager命令:
yum -y install yum-utils -
安装mysqll
yum -y install mysql-community-server
-
2.2 配置MySQL远程连接
-
查看mysql版本
mysql -V -
启动mysql&&设置开机自启
systemctl start mysqld systemctl enable mysqld -
查看默认生成密码
grep 'temporary password' /var/log/mysqld.log -
登录修改密码
mysql -uroot -p -
修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'NoPassword564925080!'; mysql5.7之后默认安装了密码安全检查插件(validate_password),默认密码检查策略要求密码必须包含:大小写字母、数字和特殊符号,并且长度不能少于8位。否则会提示ERROR 1819 (HY000): Your password does not satisfy the current policy requirements错误. -
授权远程登录用户
默认的密码加密方式是:caching_sha2_password,而现在很多客户端工具还不支持这种加密认证方式,连接测试的时候就会报错:client does not support authentication protocol requested by server; consider upgrading MySQL client
CREATE USER 'noneplus'@'%' IDENTIFIED BY 'Noneplus564925080!'; GRANT ALL ON *.* TO 'noneplus'@'%'; //修改认证方式为mysql_native_password ALTER USER 'noneplus'@'%' IDENTIFIED WITH mysql_native_password BY 'Noneplus564925080!'; flush privileges; -
开放服务器3306端口
-
远程连接

3 MySQL基础知识储备
3.1 常用命令
登录
mysql -u root -p数据库相关命令
show databases;
create database database_name;
use database_name;
drop database_name;数据库表相关命令
【数据库和数据库表相关命令都属于DDL数据定义语言】
show tables; [先切换到指定数据库]
//创建表
CREATE TABLE `user_info` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '用户id',
`username` varchar(10) DEFAULT NULL COMMENT '用户姓名',
`password` varchar(20) DEFAULT NULL COMMENT '用户密码',
`age` int(5) DEFAULT NULL COMMENT '年龄',
`email` varchar(20) DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=100 DEFAULT CHARSET=utf8 COMMENT='用户信息表'
//查看表定义
show create table user_info \G;
drop table user_info;
//删除表字段
alter table user_info column age;
//修改表
Alter table user_info modify username varchar(15);
//增加表的字段
alter table user_info add column gender int(1);
//字段改名
alter table user_info change age age1 int(3);
//modify,add,change都可以进行排序
Alter table user_info modify username varchar(15) first; //放在最前面
alter table user_info add column gender int(1) after age;//字段至于age之后
//修改表名
alter table user_info rename person_info;增删改查命令
【增删改查属于DML数据操作语言】
插入
INSERT INTO user_info(username,password,age,email) VALUES('hq','123456789',22,'[email protected]')更新
UPDATE user_info SET username='hq',age=23,email='[email protected]' WHERE id=5删除
DELETE FROM user_info WHERE id=6查询
SELECT * FROM user_info WHERE id = 6SELECT * FROM user_info WHERE id = 6 and age<30排序【默认升序】
SELECT * FROM user_info ORDER BY ID DESC LIMIT 10 //查询最后十条数据SELECT * FROM user_info ORDER BY ID DESC LIMIT 10,20 //查询最后20条数据的前10条统计数据总条数
SELECT COUNT(1) FROM user_info;统计最大值,最小值,求和
SELECT MAX(age),MIN(age) ,SUM(age) FROM user_info;表连接查询
select ename,deptname from emp,dept where emp.deptno=dept.deptno;3.2 常用数据类型
数值类型
| 整数类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| tinyint | 1 | 有符号-128 无符号0 | 有符号127 无符号255 |
| smallint | 2 | 有符号-32768 无符号0 | 有符号32767 无符号65535 |
| mediumint | 3 | 有符号-800w 无符号0 | 有符号800w 无符号167w |
| int,integer | 4 | 有符号-21亿 无符号0 | 有符号21亿 无符号42亿 |
| bigint | 8 | 有符号-92w兆 无符号0 | 有符号92w兆 无符号184w兆 |
int(5)指定显式宽度【不显式指定默认int(11)】,当数值宽度小于五位的时候,默认填满。zerofill指用0填充。
unsigned表示是否带符号
| 浮点数类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| float | 4 | ||
| double | 8 |
| 定点数类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| decimal(M,D) | M+2 | 有符号-128 无符号0 | 有符号127 无符号255 |
表示一共显示M位数字,包括整数位和小数位,其中D位代表小数点有几位
decimal不指定精度默认整数位为10,小数位为0.
日期时间类型
| 类型 | 字节 | 最小值 | 最大值 |
|---|---|---|---|
| date | 4 | 1000-01-01 | 9999-12-31 |
| datetime | 8 | 1000-01-01 00:00:00 | 9999-12-31 23:59:59 |
| timestamp | 4 | 1970010108001 | 2038年的某个时刻 |
记录系统当前时间可用timestamp,支持不同地方的时区差异
TIMESTAMP 存储的时间范围 1970-01-01 00:00:01 ~ 2038-01-19-03:14:07
字符串类型
| 类型 | 描述 |
|---|---|
| char | 0-255字节 |
| varchar | 0-65535字节 |
| tinyblob | 0-255字节 |
| blob | 0-65535字节 |
| mediumblob | 0-16772150字节 |
| longblob | 0-4294967295字节 |
| tinytext | 0-255字节 |
| text | 0-65535字节 |
| mediumtext | 0-16772150字节 |
| longtext | 0-4294967295字节 |
| varbinary(M) | 0-M字节 |
| binary(M) | 0-M字节 |
3.3 运算符
算术运算符
| 算术运算符 | 说明 |
|---|---|
| + | 加法运算 |
| - | 减法运算 |
| * | 乘法运算 |
| / | 除法运算,返回商 |
| % | 求余运算,返回余数 |
比较运算符
| 比较运算符 | 说明 |
|---|---|
| = | 等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| <=> | 安全的等于,不会返回 UNKNOWN |
| <> 或!= | 不等于 |
| IS NULL 或 ISNULL | 判断一个值是否为 NULL |
| IS NOT NULL | 判断一个值是否不为 NULL |
| LEAST | 当有两个或多个参数时,返回最小值 |
| GREATEST | 当有两个或多个参数时,返回最大值 |
| BETWEEN AND | 判断一个值是否落在两个值之间 |
| IN | 判断一个值是IN列表中的任意一个值 |
| NOT IN | 判断一个值不是IN列表中的任意一个值 |
| LIKE | 通配符匹配 |
| REGEXP | 正则表达式匹配 |
逻辑运算符
| 逻辑运算符 | 说明 |
|---|---|
| NOT 或者 ! | 逻辑非 |
| AND 或者 && | 逻辑与 |
| OR 或者 || | 逻辑或 |
| XOR | 逻辑异或【相同为0,不同为1】 |
位运算符
| 位运算符 | 说明 |
|---|---|
| | | 按位或 |
| & | 按位与 |
| ^ | 按位异或 |
| << | 按位左移 |
| >> | 按位右移 |
| ~ | 按位取反,反转所有比特 |
运算符优先级
| 优先级由低到高排列 | 运算符 |
|---|---|
| 1 | =(赋值运算)、:= |
| 2 | II、OR |
| 3 | XOR |
| 4 | &&、AND |
| 5 | NOT |
| 6 | BETWEEN、CASE、WHEN、THEN、ELSE |
| 7 | =(比较运算)、<=>、>=、>、<=、<、<>、!=、 IS、LIKE、REGEXP、IN |
| 8 | | |
| 9 | & |
| 10 | <<、>> |
| 11 | -(减号)、+ |
| 12 | *、/、% |
| 13 | ^ |
| 14 | -(负号)、〜(位反转) |
| 15 | ! |
4 开发规范
4.1 设计规范
范式
-
第一范式:无重复的列
-
第二范式:属性完全依赖于主键
-
第三范式:属性不能传递依赖其他非主属性
范式的作用是避免数据冗余(数据重复)。
范式的问题
按照范式设计出来的表在数据冗余的问题虽然得到解决,但是会生成许多表,导致了表数量的复杂性,其二,查询数据的时候,多表查询的时间远远高于单表查询的时间。
反范式
范式的目的是减小数据冗余,而反范式指的是在一定程度上允许数据冗余,目的是加快数据操作。
对比
范式与反范式是一场时间和空间的较量,满足范式节省空间,满足反范式加快操作速度。
在满足范式设计数据库的前提条件下,再根据具体的业务需求完成反范式的设计。
4.2 命名规范
小写+下划线,不能使用保留关键字【!!!】
【MySQL对象名默认规定大小写敏感,且在生产环境中MySQL通常运行在Linux系统下,Linux系统本身也是大小写敏感的。】
【https://dev.mysql.com/doc/mysqld-version-reference/en/keywords-8-0.html建议在设计数据表之后逐一排查有没有使用关键字。】
4.3 字段规范
原则:
- 尽可能选择存储空间最小的字段【栗子:IP转化为整型存储】、
- 非负型数据优先使用无符号存储
1,char VS varchar
char 定长 浪费空间 查询速度快
varchar 变长 节省空间 查询速度较慢
出于存储空间的考虑,优先选择varchar
2,避免使用text,blob,如果一定要使用,单独出扩展表(通常这类数据会考虑使用NoSQL来存储)
【MySQL内存临时表不支持text,blob这样的大数据类型,只能使用磁盘临时表完成,并且会导致二次查询】
3,同财务相关的最好使用定点数decimal
4,日期类型选择
- DATETIME:记录年月日时分秒,表示的时间范围最大
- 如果记录的日期要让不同时区的人使用,使用TIMESTAMP
5 B+树索引
5.1 什么是索引?
索引是一种数据结构,具体表现在查找算法上。
5.2 索引目的
提高查询效率
【类比字典和借书】
如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql。如果没有索引,那么你可能需要把所有单词看一遍才能找到你想要的。
去图书馆借书也是一样,如果你要借某一本书,一定是先找到对应的分类科目,再找到对应的编号,这是生活中活生生的例子,通用索引,可以加快查询速度,快速定位。
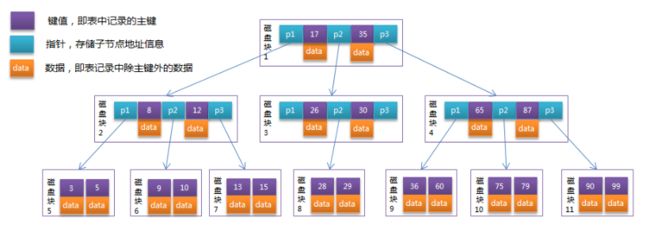
5.3 B树
结构特征:每个节点可包含多个子节点,叶子节点位于同一层(每个节点保存索引和数据)
使用用法:B树为磁盘预读设计,其特征相对于二叉树降低了高度,减少IO次数(树的高度等于IO次数)
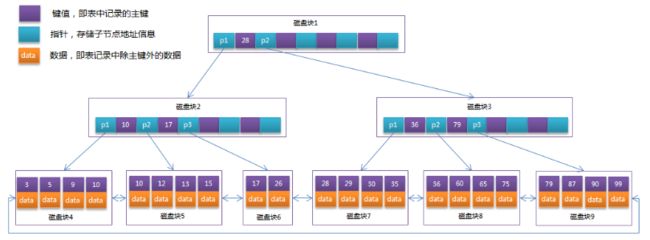
5.3 B+树
结构特征:只在叶子节点存储数据,且叶子节点有序排列,通过链指针相连(只有叶子节点保存数据,其他节点都只保存索引,单次IO能加载更多节点)
使用用法:B树解决了磁盘IO问题,而B+树通过数据结构优化和区间访问加快了元素的查找效率
5.4 原理分析
索引存储位置
索引本身也很大,所以存储在磁盘中,需要加载到内存中执行。
故:索引结构优劣标准:磁盘I/O次数
局部性原理和磁盘预读
局部性原理:当一个数据被用到,其附近的数据很可能会马上用到
磁盘预读:由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入主存。
B树如何利用磁盘预读功能
B树的节点大小和磁盘的IO大小是进行过匹配的,一次IO可以读取一整个节点的大小。这样就能有效减少IO次数。
【如果节点大小和B树大小不对齐,那么同一页节点可能需要两次IO读取】
综上所述,B树解决的核心问题是IO次数的问题
为什么B+树比B树更适合作为索引结构
B树解决了磁盘IO的问题但没有解决元素遍历复杂的问题。
B+树的叶子节点用链指针相连,极大提高区间访问速度。【比如查询50到100的记录,查出50后,顺着指针遍历即可】
B+树的叶子结点可以存哪些东西
可能是整行数据,也可能是主键的值。
前者被称为聚簇索引,后者称为非聚簇索引。
聚簇索引更快!!!
为什么???聚簇索引已经查到整行数据了,而非聚簇索引还可能根据主键值再进行查询一次。
例外:覆盖索引——数据直接从索引中取得。
6,SQL优化
SQL优化背景
开发项目上线初期,由于业务数据量相对较少,一些SQL的执行效率对程序运行效率的影响不太明显,而开发和运维人员也无法判断SQL对程序的运行效率有多大,故很少针对SQL进行专门的优化,而随着时间的积累,业务数据量的增多,SQL的执行效率对程序的运行效率的影响逐渐增大,此时对SQL的优化就很有必要。
- SQL优化发生在业务量达到一定规模的时候
- 目的是优化SQL的执行效率
6.1 优化范围
- 硬件资源
- 操作系统参数,数据库参数配置
- SQL语句,索引优化
6.2 SQL优化
- 数据库设计优化【规范,前期设计】
- SQL语句优化
- 索引优化
- 读写分离,分库分表
6.3 慢查询语句
慢查询:10s无返回结果,定义为慢查询
SHOW STATUS LIKE "slow_queries";SHOW VARIABLES LIKE "long_query_time";//可以显示当前慢查询时间
set long_query_time=1 ;//可以修改慢查询时间6.4 常用优化方法
-
避免全表扫描(考虑在 where 及 order by 涉及的列上建立索引)
-
尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num=0 -
应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描
-
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描
select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20 -
in 和 not in 也要慎用,否则会导致全表扫描
select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3 -
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描
select id from t where num/2=100 应改为: select id from t where num=100*2 -
应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
select id from t where substring(name,1,3)='abc'--name以abc开头的id 应改为: select id from t where name like 'abc%' -
很多时候用 exists 代替 in 是一个好的选择
select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num) -
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率(5)
-
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销
-
尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间
-
任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段
-
尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写
7 事务和锁
7.1 事务
7.1.1 事务存在的原因
事务存在的目的:保证用户对数据操作对数据是安全的。(比如说银行卡余额)
7.1.2 事务的特性——ACID
原子性:一个事务要么全部执行,要么不执行
一致性:事务开始和结束时,数据保持一致
隔离性:事务之间互不影响
持久性:事务操作的结果具有持久性
7.1.3 关于脏读,不可重复读,幻读
-
脏读
事务A读取了事务B中尚未提交的数据。如果事务B回滚,则A读取使用了错误的数据。
【一个事物在读的时候,禁止读取未提交的事务】
-
不可重复读
不可重复读是指在一个事务范围内多次查询却返回了不同的数据值,这是由于存在查询间隔,被另一个事务修改并提交了。
【一个事物在读的时候,禁止任何事务写】
-
幻读
在事务A多次读取过程中,事务B对数据进行了新增操作,导致事务A多次读取的数据不一致。
【一个事物加上表级锁,禁止任何操作的并发】
小结:
脏读是读取了尚未提交的数据,不可重复读是读取了不停更新的数据(修改),幻读是指读取了不停更新的数据(新增)。
7.1.4 关于事务隔离级别
目的:避免脏读,不可重复读,幻读
读未提交:一个事务可以读到另一个事务尚未提交的数据。也就是脏读,避免脏读的方式:
读提交:一个事务要等另一个事务提交后才能读取数据。但会导致一个事务中相同查询出现不同的结果。也就是不可重复读。避免不可重复读的方式:
重复读(RR,MySQL默认级别):就是在开始读取数据时,不允许修改操作。但会导致由于允许insert操作导致的事务结果出现不同。也就是幻读,避免幻读的方式::
序列化:序列化使事务串行顺序执行,但会大大降低并发性能。
7.2 锁机制
7.2.1 并发控制 控制的是什么?
并发问题:某个时间点两次或两次以上同一请求的结果不一致。
当程序的使用者超过两个人时,就有几率产生并发问题。当程序的使用者变多,产生并发问题的概率就会随之上升。
总的来说,并发控制就是控制数据的一致性。
7.2.2 共享锁和排他锁
Innodb实现了两种类型的行锁:共享锁,排他锁。
共享锁:所有用户都可读取当前记录,但不可修改当前记录
select * from table lock in share mode排它锁(悲观锁):当前用户可进行增删改查,其他用户无法进行任何操作(MySQL的增删改操作默认加了排他锁,查无任何锁)
【为什么在Innodb中使用索引?】
Innodb行锁并不是锁记录而是锁索引,优先锁主键索引,其次锁非主键索引(比如唯一索引),如果没有索引,就需要通过全表扫描来找到当前记录,就相当于表锁了。(这也是为什么需要进行索引优化的原因)
意向共享锁和意向排他锁
Innodb虽然使用行锁,但并没有废弃表锁。
【行锁和表锁】
MyISAM存储引擎使用的是表锁,而Innodb增加了行锁。并不意味着Innodb彻底抛弃了表锁。
关于行锁,较小的粒度导致其高并发,但也因较小的粒度导致加锁慢,开销大,会出现死锁情况。
关于表锁,较大的粒度在高并发上的表现很弱,但同时粒度较大,加锁块,开销小,不会出现死锁情况。
没有完美的技术,只有合适的解决方案。在高并发场景下使用行锁而忍受一些问题本质上是一种权衡。
【意向锁的背景冲突】
意向锁的出现本质上是解决行锁和表锁矛盾的问题。
事务A获得了表中某一行的共享锁,事务B申请了表的写权限,这时候就会产生矛盾。
【关于意向锁】
首先,意向锁是一种表锁。
意向共享锁:事务获得表中的某一行的共享锁前,需要先获得整张表的意向共享锁。
意向排他锁:事务获得表中的某一行的排他锁前,需要先获得整张表的意向排他锁。
意向锁的加锁过程是自动完成的。
【意向锁的共享问题】
意向锁是表锁,它的互斥性是针对表级别的事务,比如一个事务要获取一张表的写权限。所以意向锁对于表级别的事务是互斥的。但是对于行级别的事务是共享的,也就是说,一个意向锁可以被多个行级别的事务所持有。
7.3 死锁
关于死锁抖音上有一个非常好玩的小视频:
面试官问:解释一下死锁,解释明白了就发offer
应聘者答:先发offer,发了offer再解释
死锁本质上就是持有锁和释放锁的问题,就像这个视频里描述的,面试官在听到死锁的解释后,才会释放offer这个锁,而应聘者是得到offer后才会释放死锁解释这个锁。offer和对死锁的解释就可以类比两个锁。
死锁的状态就是互相等待。
7.4 乐观锁与悲观锁
乐观锁和悲观锁并不是锁的具体实现,而是并发控制的两种策略,或者说是抽象。
乐观锁(适合多读场景)
- 乐观锁本质上是没有锁的。
- 执行流程,先读取数据,然后在更新前检查在读取至更新这段时间数据是否被修改
- 未修改:直接更新数据
- 已修改:重新读取,再次提交更新(或者放弃操作)
为什么乐观锁适合多读场景?
乐观锁是一种更新前的检查机制,相对于悲观锁来说在多读场景下可以减少锁的性能开销,对于多写场景,乐观锁会一直进入已修改,重新读取,再次提交的循环,反而带来更多的资源消耗。
悲观锁(适合多写场景)
- 读取数据的时候上锁(其他用户就无法读取),直到本次数据更新完成才会释放锁。在多写场景下,能保证较高的数据一致性。
【总的来说,乐观锁回滚重试,悲观锁阻塞事务】