py:90行代码教你爬取豆瓣电影top250并存储到Excel中
![]()
一.前言
python作为一个解释型语言,在数据分析,数据爬取方面有自己的先天优势,近几年也正被越来越多的人所使用,本篇文章以一个简单的数据爬取的例子来帮助大家入门python,相信你会感兴趣.同时对于喜欢看电影的小伙伴也是一个福利.
首先看一下成果,这是我们要爬取的页面:
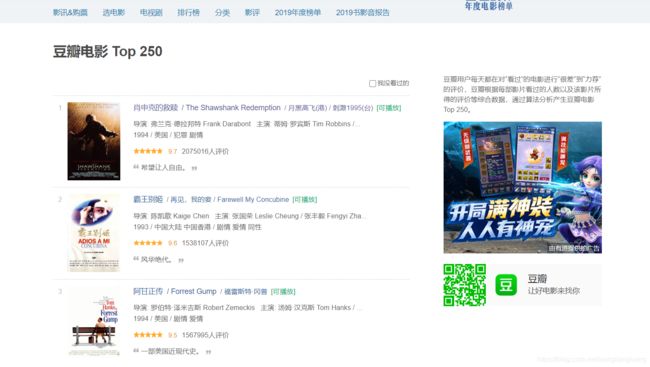
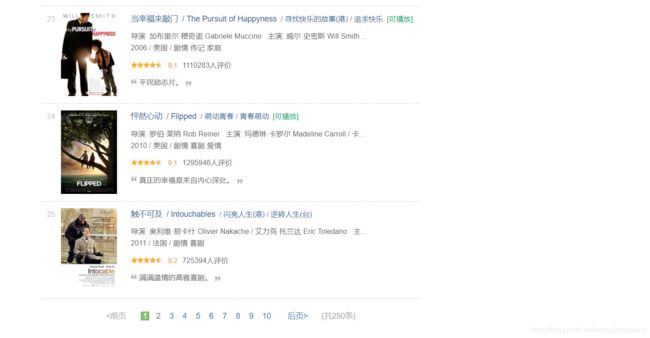
这样的页面总共有十页,每一页是25个,我们爬取每个电影的名称,链接,评分等等信息存储在excel中,爬取效果如下:
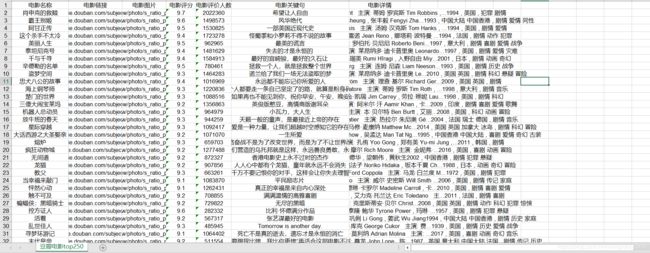
二.总体思路
1.通过url请求,得到对应的html页面;
2.通过BeautifulSoup取出与电影信息相关的html代码,然后通过正则表达式取 出具体的数据
3.将数据存储至excel表格中.
第一步,获取html代码
我们需要模仿浏览器向服务器发送一个url请求,这样就能得到服务器的响应,也就是当前页面的html代码,通过以下代码就可以.
# 请求头中的User-Agent是直接copy浏览器中的,显示了浏览器的型号,从而让服务器认为我们是一个浏览器
header = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"}
html=""
request=urllib.request.Request("https://movie.douban.com/top250?start=",headers=header) #构造请求数据
response = urllib.request.urlopen(request) #发起url请求
html=response.read().decode('utf-8') #用utf-8进行解码
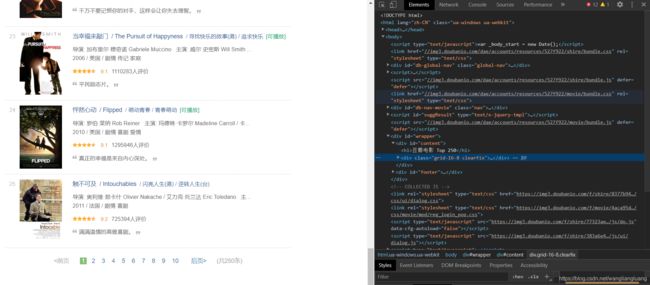
这样我们就得到了服务器响应的html代码,如下:

因为整个html页面代码很多,这里只是截取了其中一部分,得到的html代码应是与直接在浏览器页面右键单击–>检查,得到的源代码一样的,如下:
补充:其实模仿浏览器发送url请求本身并不复杂,浏览器向服务器发送请求,本质上就是向服务器发送了这些数据而已.那我们利用代码也当然可以做到.

第二步,筛选具体数据
我们想要的数据就在这些html代码中,那我们要筛选出我们想要的数据,这里首先要利用一个工具类BeautifulSoup,通过浏览器页面选取元素我们可以知道,我们想要的数据在一个class='item’的div中
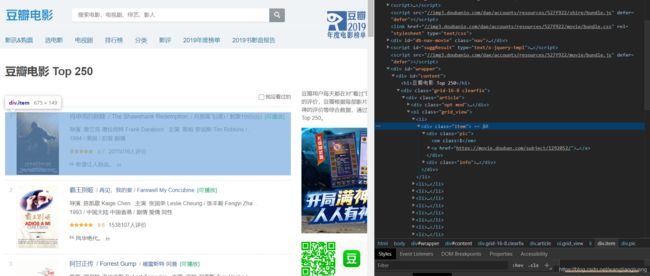
于是借助BeautifulSoup,使用如下代码即可筛选出与每一个电影数据相关的html代码.
bs = BeautifulSoup(html,"html.parser") #构造 BeautifulSoup类对象
items=bs.find_all('div',class_='item'): #该方法会匹配出所有的符合内容,返回一个集合
筛选出的结果如下(其中一个电影的数据):
"item">
"info">
"hd">
"https://movie.douban.com/subject/1292052/" class="">
"title">肖申克的救赎
"title"> ;/ ;The Shawshank Redemption
"other"> ;/ ;月黑高飞(港) / 刺激1995(台)
"playable">[可播放]
"bd">
"">
导演: 弗兰克·德拉邦特 Frank Darabont ; ; ;主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 ;/ ;美国 ;/ ;犯罪 剧情
"star">
"rating5-t">
"rating_num" property="v:average">9.7
"v:best" content="10.0">
2075016人评价
"quote">
"inq">希望让人自由。
再之后我们还需要筛选出具体的我们想要的数据,比如说电影名称,评价等等信息,这里使用正则表达式进行筛选,在python需要借助re工具类来使用正则.
比如现在我们要筛选电影名称,它在这一句代码中.肖申克的救赎,那我们可以这样写,
# ()作为一组,一个整体,匹配出来的就是()里面的内容
name=re.compile(r'(.*)')
#findall方法就是进行匹配,找出所有的符合的内容,该方法会返回一个数组,所以要取第一个
name.findall(item)[0] #item就是使用BeautifulSoup已经筛选出的与电影相关的html代码.也就是上一张代码的内容.
其他评价,电影链接等等信息和筛选电影名称的代码,思想是相似的,这里不再赘述.
第三步,存储数据.
我们需要将筛选出的数据存储到excel中,这里要用到xlwt工具类,将数据写入到excel表格中.其实也就是调用对应的方法即可,那怎样具体指定我们写入到哪一个单元格当中呢?
这里是将整个表格看作一个坐标轴,左上角为原点,坐标为(0,0).那么下图中所框住的表格的坐标就是(1,2).

现在举例,我们想要在(0,0)单元格写入hello数据,代码可以这样写;
#构建一个workbook文件对象,也就是excel文件对象
workbook= xlwt.Workbook(encoding='utf-8')
#创建工作表对象,也就是worksheet,
sheet = workbook.add_sheet('sheet1')
#写入数据,第一个是横坐标,第二个是纵坐标,第三个是写入的内容
sheet.write(0,0,'hello')
#保存数据,不保存的话是在内存中,参数就是文件名称
workbook.save('test.xls')
三.全部代码
在实际操作中,我们需要循环处理,分别筛选出每一页的数据存储到一个总的数组中,然后将数据保存,全部代码如下:
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式
import urllib.request,urllib.error #定制url,获取网页数据
import xlwt #进行excel操作
import sqlite3 #进行数据库操作
def main():
# 获取数据
baseurl="https://movie.douban.com/top250?start="
data=getDate(baseurl)
# 保存数据
savePath=".\\豆瓣电影top250.xls" # .\就表示当前路径
saveDate(savePath,data)
#得到指定一个url的网页的内容
def askUrl(url):
# 请求头中的User-Agent是直接copy浏览器中的,显示了浏览器的型号,从而让服务器认为我们是一个浏览器
header = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"}
html=""
try:
request=urllib.request.Request(url,headers=header) #构造请求数据
response = urllib.request.urlopen(request) #发起url请求
html=response.read().decode('utf-8')
except urllib.error.URLError as e:
if hasattr(e,"code"): #如果有code属性,打印出来
print(e.code)
if hasattr(e,"reason"): #如果有reason,打印出来
print(e.reason)
return html
#电影名称
name=re.compile(r'(.*)') # ()作为一组,一个整体,匹配出来的就是()里面的内容
#电影链接
link=re.compile(r'')
#电影图片
img=re.compile(r'![.*src=]() ')
#电影评分
mark=re.compile(r'')
#评分人数
markNum=re.compile(r'(\d*)人评价')
#电影关键词
keyWords=re.compile(r'(.*)')
#电影详情
details=re.compile(r'
')
#电影评分
mark=re.compile(r'')
#评分人数
markNum=re.compile(r'(\d*)人评价')
#电影关键词
keyWords=re.compile(r'(.*)')
#电影详情
details=re.compile(r'(.*?)
',re.S)
#re.S是使.包括换行符,这里必须包括?,就是0次到1次,不然会把其他包含进去.也就是当第一次遇到时就结束,否则就会匹配到最后一次遇到<\p>时结束.
def getDate(baseurl):
totaldata=[]
for i in range(0,10):
#获取数据
html=askUrl(baseurl+str(i*25)) #循环调用分页请求,每一页25个数据
# 解析数据,大概思路就是通过bs找到大概的html代码,然后通过re解析具体数据
bs = BeautifulSoup(html,"html.parser")
for item in bs.find_all('div',class_='item'):
data=[]
item=str(item)
data.append(name.findall(item)[0]) #添加电影名称
data.append(link.findall(item)[0]) #添加电影链接
data.append(img.findall(item)[0]) #添加电影图片
data.append(mark.findall(item)[0]) #添加电影评分
data.append(markNum.findall(item)[0]) #添加电影评价人数
keyWord=keyWords.findall(item) #电影关键句有可能为空,要做处理
if len(keyWord) != 0:
keyWord=keyWord[0].replace('。','')
data.append(keyWord)
else:
data.append(' ')
detail=details.findall(item) #电影详情需要去除空格,等等多余符号
detail=re.sub(r'
,(\s+)? 表示匹配任意空格,包括制表符,换行符等
detail=re.sub(r'/',',',detail)
data.append(detail.strip())
totaldata.append(data)
return totaldata
#保存数据
def saveDate(savePath,data):
workbook= xlwt.Workbook(encoding='utf-8', style_compression=1)
sheet = workbook.add_sheet('豆瓣电影top250',cell_overwrite_ok=True) #cell_overwrite_ok表示每个单元格的是否可以被覆盖掉
cal=('电影名称','电影链接','电影图片','电影评分','电影评价人数','电影关键句','电影详情')
for i in range(0,7):
sheet.write(0,i,cal[i])
for index,i in enumerate(data):
print("保存第{}行".format(index+1))
for j in range(0,7):
sheet.write(index+1,j,i[j])
workbook.save(savePath)
if __name__ == '__main__': # 程序的入口
main()
print("爬取完毕")
如果代码中有什么不理解的地方或者说觉得可以改进的地方,都可以评论哦,都会一一回应的.
