OpenCV人类行为识别(3D卷积神经网络)

上图视频测试链接:https://www.bilibili.com/video/BV13E411c7Mv/
1. 3D卷积神经网络
相比于2D 卷积神经网络,3D卷积神经网络更能很好的利用视频中的时序信息。因此,其主要应用视频、行为识别等领域居多。3D卷积神经网络是将时间维度看成了第三维。
人类行为识别的实际应用:
- 安防监控。(检测识别异常行为:如打架,偷东西等)
- 监视和培训新人工作来确保任务执行正确。(例如,鸡蛋灌饼制作程序:和面,擀面团,打鸡蛋,摊饼等动作)
- 判断检测食品服务人员是否按规定洗手。
- 自动对视频数据分类。
人类的行为识别,在实际生活环境中,在不同的场景会存在着背景杂乱、遮挡和视角变化等等情况,对于人来说,是很容易就可以辨识出来,但对于计算机,就不是一件简单的事了,比如目标尺度变化和视觉改变等。
2. 人类行为识别模型
GitHub地址:https://github.com/kenshohara/3D-ResNets-PyTorch
论文:《Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet?》
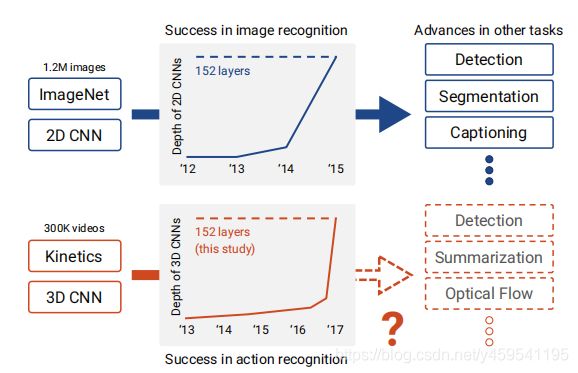
对于识别的行为超过400种,根据实际的视频,最好的准确度在90%左右,OpenCV官方示例的样本类别:
https://github.com/opencv/opencv/blob/master/samples/data/dnn/action_recongnition_kinetics.txt
abseiling
air drumming
answering questions
applauding
applying cream
archery
arm wrestling
arranging flowers
assembling computer
auctioning
baby waking up
baking cookies
balloon blowing
bandaging
barbequing
bartending
beatboxing
bee keeping
belly dancing
bench pressing
bending back
bending metal
biking through snow
blasting sand
blowing glass
blowing leaves
blowing nose
blowing out candles
bobsledding
bookbinding
bouncing on trampoline
bowling
braiding hair
breading or breadcrumbing
breakdancing
brush painting
brushing hair
brushing teeth
building cabinet
building shed
bungee jumping
busking
canoeing or kayaking
capoeira
carrying baby
...
示例的代码:
https://github.com/opencv/opencv/blob/master/samples/dnn/action_recognition.py
import os
import numpy as np
import cv2 as cv
import argparse
from common import findFile
parser = argparse.ArgumentParser(description='Use this script to run action recognition using 3D ResNet34',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--input', '-i', help='Path to input video file. Skip this argument to capture frames from a camera.')
parser.add_argument('--model', required=True, help='Path to model.')
parser.add_argument('--classes', default=findFile('action_recongnition_kinetics.txt'), help='Path to classes list.')
# To get net download original repository https://github.com/kenshohara/video-classification-3d-cnn-pytorch
# For correct ONNX export modify file: video-classification-3d-cnn-pytorch/models/resnet.py
# change
# - def downsample_basic_block(x, planes, stride):
# - out = F.avg_pool3d(x, kernel_size=1, stride=stride)
# - zero_pads = torch.Tensor(out.size(0), planes - out.size(1),
# - out.size(2), out.size(3),
# - out.size(4)).zero_()
# - if isinstance(out.data, torch.cuda.FloatTensor):
# - zero_pads = zero_pads.cuda()
# -
# - out = Variable(torch.cat([out.data, zero_pads], dim=1))
# - return out
# To
# + def downsample_basic_block(x, planes, stride):
# + out = F.avg_pool3d(x, kernel_size=1, stride=stride)
# + out = F.pad(out, (0, 0, 0, 0, 0, 0, 0, int(planes - out.size(1)), 0, 0), "constant", 0)
# + return out
# To ONNX export use torch.onnx.export(model, inputs, model_name)
def get_class_names(path):
class_names = []
with open(path) as f:
for row in f:
class_names.append(row[:-1])
return class_names
def classify_video(video_path, net_path):
SAMPLE_DURATION = 16
SAMPLE_SIZE = 112
mean = (114.7748, 107.7354, 99.4750)
class_names = get_class_names(args.classes)
net = cv.dnn.readNet(net_path)
net.setPreferableBackend(cv.dnn.DNN_BACKEND_INFERENCE_ENGINE)
net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU)
winName = 'Deep learning image classification in OpenCV'
cv.namedWindow(winName, cv.WINDOW_AUTOSIZE)
cap = cv.VideoCapture(video_path)
while cv.waitKey(1) < 0:
frames = []
for _ in range(SAMPLE_DURATION):
hasFrame, frame = cap.read()
if not hasFrame:
exit(0)
frames.append(frame)
inputs = cv.dnn.blobFromImages(frames, 1, (SAMPLE_SIZE, SAMPLE_SIZE), mean, True, crop=True)
inputs = np.transpose(inputs, (1, 0, 2, 3))
inputs = np.expand_dims(inputs, axis=0)
net.setInput(inputs)
outputs = net.forward()
class_pred = np.argmax(outputs)
label = class_names[class_pred]
for frame in frames:
labelSize, baseLine = cv.getTextSize(label, cv.FONT_HERSHEY_SIMPLEX, 0.5, 1)
cv.rectangle(frame, (0, 10 - labelSize[1]),
(labelSize[0], 10 + baseLine), (255, 255, 255), cv.FILLED)
cv.putText(frame, label, (0, 10), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
cv.imshow(winName, frame)
if cv.waitKey(1) & 0xFF == ord('q'):
break
if __name__ == "__main__":
args, _ = parser.parse_known_args()
classify_video(args.input if args.input else 0, args.model)
3.代码
环境:
- win10
- pycharm
- anaconda3
- python3.7
文件结构:
代码:
from collections import deque
import numpy as np
import argparse
import imutils
import cv2
# 构造参数
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True, help="path to trained human activity recognition model")
ap.add_argument("-c", "--classes", required=True, help="path to class labels file")
ap.add_argument("-i", "--input", type=str, default="", help="optional path to video file")
args = vars(ap.parse_args())
# 类别,样本持续时间(帧数),样本大小(空间尺寸)
CLASSES = open(args["classes"]).read().strip().split("\n")
SAMPLE_DURATION = 16
SAMPLE_SIZE = 112
print("处理中...")
# 创建帧队列
frames = deque(maxlen=SAMPLE_DURATION)
# 读取模型
net = cv2.dnn.readNet(args["model"])
# 待检测视频
vs = cv2.VideoCapture(args["input"] if args["input"] else 0)
writer = None
# 循环处理视频流
while True:
# 读取每帧
(grabbed, frame) = vs.read()
# 判断视频是否结束
if not grabbed:
print("无视频读取...")
break
# 调整大小,放入队列中
frame = imutils.resize(frame, width=640)
frames.append(frame)
# 判断是否填充到最大帧数
if len(frames) < SAMPLE_DURATION:
continue
# 队列填充满后继续处理
blob = cv2.dnn.blobFromImages(frames, 1.0, (SAMPLE_SIZE, SAMPLE_SIZE), (114.7748, 107.7354, 99.4750),
swapRB=True, crop=True)
blob = np.transpose(blob, (1, 0, 2, 3))
blob = np.expand_dims(blob, axis=0)
# 识别预测
net.setInput(blob)
outputs = net.forward()
label = CLASSES[np.argmax(outputs)]
# 绘制框
cv2.rectangle(frame, (0, 0), (300, 40), (255, 0, 0), -1)
cv2.putText(frame, label, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
# cv2.imshow("Activity Recognition", frame)
# 检测是否保存
if writer is None:
# 初始化视频写入器
# fourcc = cv2.VideoWriter_fourcc(*"MJPG")
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
writer = cv2.VideoWriter("E:\\work\\activity-recognition-demo\\videos\\output\\xishou1.mp4", fourcc, 30, (frame.shape[1], frame.shape[0]), True)
writer.write(frame)
# 按 q 键退出
# key = cv2.waitKey(1) & 0xFF
# if key == ord("q"):
# break
print("结束...")
writer.release()
vs.release()
4. 测试
测试1:洗手
OpenCV人类行为检测-洗手
https://www.bilibili.com/video/av96440536/
视频左上角打上了
“washing hands”(洗手)标签。
测试2:瑜伽

上图视频测试地址:https://www.bilibili.com/video/BV13E411c7QK/
检测到视频中是“yoga”(瑜伽),同时又识别到执行的动作是“stretching leg”(伸腿)。
模型和完整代码链接:https://pan.baidu.com/s/1t-DEW3SpbUZFxFeIZ3QReQ
提取码:ynnx
下载后,代码中的路径记得替换为自己的路径~