Mysql知识点复习小节
文章目录
-
-
- 1.sql分类:
- 2.三种常用数据类型:
- 3.三大范式:
- 4.相关子查询:
-
- 例子1:
- 例子2:
- 5.Mysql存储引擎:
- 5.事务:保证 多个操作 原子性
- 6.事务的隔离级别:
- 7.索引:
-
1.sql分类:
- DDL(Data Define Language):对数据库或者数据表的操作
- DML(Management):最常见的对数据进行增删改
- DQL(Query):最常见的对数据进行查select
- DCL(Control):用户授权grant
- TCL(Transcaction Control Language):事务操作
2.三种常用数据类型:
-
数值: int(整数) decimal(小数运算)
-
日期和时间:date time datetime timestamp(系统时间戳)
-
文本:char varchar
3.三大范式:
- 1NF:将Excel合并单元格的变为数据库可以存储的,行列分明的。数据库可存储即满足第一范式。
- 2NF:有主键,但存在传递依赖。
- 3NF: 每列都与主键有直接关系,不存在传递依赖。
4.相关子查询:
这种子查询执行括号内查询时,需要用到外查询的表,所以叫作相关子查询:
所以不能先进行括号内,再进行括号外,
而是交替进行!
小技巧:将=理解为将两张表左右拼接,同一个字段的重合 会更加形象,容易理解!
例子1:
orders表:

customers表:

(1) 单独来看:
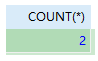
SELECT COUNT(*) FROM orders WHERE cust_id =‘1000000001’;
这条最基本的查询结果为:
(2) 相关子查询(两张表):
SELECT cust_id,cust_name,cust_state,(SELECT COUNT(*) FROM orders
WHERE orders.cust_id=customers.cust_id) AS orders
FROM customers
ORDER BY cust_name;
结果为:

详细分析一下过程:
①先看内查询:
SELECT COUNT(*) FROM orders
WHERE orders.cust_id=customers.cust_id
内查询用到了外面的表customers,所以这是一个相关子查询,
相关子查询就需要再内查询的时候用到外表,
所以第一步就是查询外表customers.cust_id,
customers.cust_id有五个项,分别为1000000001,2,3,4,5,
所以内查询就变成五次类似 (1) 的查询,即:
SELECT COUNT() FROM orders WHERE cust_id =‘1000000001’;
SELECT COUNT() FROM orders WHERE cust_id =‘1000000002’;
SELECT COUNT() FROM orders WHERE cust_id =‘1000000003’;
SELECT COUNT() FROM orders WHERE cust_id =‘1000000004’;
SELECT COUNT(*) FROM orders WHERE cust_id =‘1000000005’;
先来看第一次:
=号,我们将cust_id与’1000000001’拼接在一起,
成功拼接后得到两行,
count(*)的结果为2,
同理:第二次0行,第三次1行,第四次1行,第五次1行.
所以,最终count(*)的结果为2,0,1,1,1
(2)plus
有人会对这句产生疑惑:
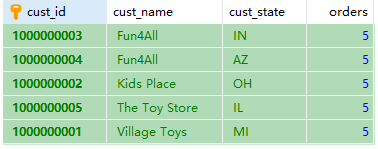
SELECT cust_id,cust_name,cust_state,(SELECT COUNT(*) FROM orders WHERE cust_id=cust_id) AS orders FROM customers ORDER BY cust_name;
以下是执行结果:
这个SQL比较简单,这里没有用到相关子查询,
所以先进行括号内的,就计算一次,得到结果为5,
count(*)的值为5,count(*)就变为数字5,
select直接打印输出。
ps:这里的=号,我们就只把它看成相等,
比如如果条件为 where sid = tid,那么就是分别比较每条数据,相等输出
那么where sid=sid,就直接输出全部了。
例子2:
这是一个对自己的相关子查询(单张表):
商品明细表:

目标:抽出大于平均数量的商品的明细
SELECT * FROM sales_detail U WHERE NUMBER > (SELECT AVG(NUMBER)
FROM sales_detail
WHERE good_id = U.good_id)
这里,因为起了别名,我们同样看作两张表进行相关子查询
结果:

5.Mysql存储引擎:
MyISAM
节省数据库空间,当数据读远大于修改时,可以使用该存储引擎
InnoDB
支持事务,如果数据修改较多时,可以使用该存储引擎
MEMORY
存储在内存中,速度快,如果存储非永久性数据时,可以使用该存储引擎
5.事务:保证 多个操作 原子性
ACID:
原子性(Atomicity),事务是最小单元,不可再分;
一致性(Consistency),事务要求所有的DML语句操作的时候,必须保证同时成功或同时失败;要么全部成功,要么全部失败
隔离性(Isolation),一个事务不会影响其他事务的执行;两个事务之间不会影响
持久性(Durability),在事务完成之后,该事务对数据库所作的更改将持久地保存在数据库中,并不会被回滚;一旦修改了,就不能回滚了
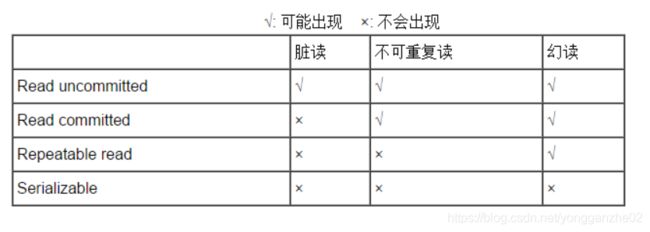
6.事务的隔离级别:
read uncommitted 读未提交
事务A和事务B,事务A未提交的数据,事务B可以读取,这里读取到的数据叫做“脏数据”,该级别最低,一般只是理论上存在,数据库的默认隔离级别都高于该级别。
read committed 读已提交
事务A和事务B,事务A提交的数据,事务B才可读取到,换句话说:对方事务提交之后的数据,当前事务才可读取到,可以避免读取“脏数据”,但是改级别会有“不可重复读”的问题,事务B读取一条数据,当事务A修改这条数据并提交后,事务B再读取这条数据时,数据发生了变化,即事务B每次读取的数据有可能不一致,这种情况叫做“不可重复读”。
repeatable read 重复读
MySQL默认的隔离级别是重复读,该级别可以达到“重复读”的效果,但是会有“幻读”的问题,即事务A读取数据,此时事务B修改了这条数据,但是事务A读取的还是之前的旧数据的内容,这样就出现了幻读。
serializable 串行化
事务A和事务B,事务A在操作数据库表中数据的时候,事务B只能排队等待,这样保证了同一个时间点上只有一个事务操作数据库,该级别可以解决“幻读”的问题。但是这种级别一般很少使用,因为吞吐量太低,用户体验不好。
7.索引:
索引相当于一本字典目录,能够提高数据库的查询效率,表中每一个字段都可添加索引。主键会自动添加索引,在查询时,如果能通过主键查询的尽量使用主键查询,效率高。
ps:
创建表代码参考:https://www.cnblogs.com/wangdong123/p/8080454.html.
mysql游标:https://ask.hellobi.com/blog/renrenren/35819.
三大范式:https://www.cnblogs.com/fanbi/p/10517658.html.