数据倾斜的思路分析+map端join实现+倒排索引实现
1什么是数据倾斜
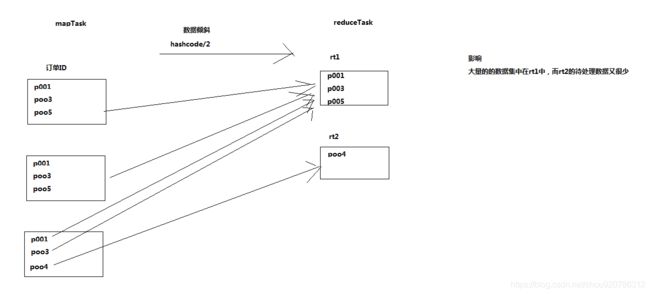
解决解决方法
1让数据数据不要去reduceTask,在mapTask就进行处理(利用distributeCache)
map端join实现
public class MapSideJoin {
public static class MapSideJoinMapper extends Mapper {
// 用一个hashmap来加载保存产品信息表
Map pdInfoMap = new HashMap();
Text k = new Text();
/**
* 通过阅读父类Mapper的源码,发现 setup方法是在maptask处理数据之前调用一次 可以用来做一些初始化工作
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream("H:/srcdata/pdts.txt")));
String line;
while (StringUtils.isNotEmpty(line = br.readLine())) {
String[] fields = line.split(",");
pdInfoMap.put(fields[0], fields[1]);
}
br.close();
}
// 由于已经持有完整的产品信息表,所以在map方法中就能实现join逻辑了
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String orderLine = value.toString();
String[] fields = orderLine.split(",");
String pdName = pdInfoMap.get(fields[1]);
k.set(orderLine + "---" + pdName);
context.write(k, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MapSideJoin.class);
job.setMapperClass(MapSideJoinMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("H:/test"));
FileOutputFormat.setOutputPath(job, new Path("H:/out"));
// 指定需要缓存一个文件到所有的maptask运行节点工作目录
/* job.addArchiveToClassPath(archive); */// 缓存jar包到task运行节点的classpath中
/* job.addFileToClassPath(file); */// 缓存普通文件到task运行节点的classpath中
/* job.addCacheArchive(uri); */// 缓存压缩包文件到task运行节点的工作目录
/* job.addCacheFile(uri) */// 缓存普通文件到task运行节点的工作目录
// 将产品表文件缓存到task工作节点的工作目录中去。方便读取文件
job.addCacheFile(new URI("file:/H:/srcdata/pdts.txt"));
//map端join的逻辑不需要reduce阶段,设置reducetask数量为0
job.setNumReduceTasks(0);
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
测试报告
[main] INFO org.apache.hadoop.mapreduce.Job - The url to track the job: http://localhost:8080/
[main] INFO org.apache.hadoop.mapreduce.Job - Running job: job_local1983477500_0001
[Thread-6] INFO org.apache.hadoop.mapred.LocalJobRunner - OutputCommitter set in config null
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:323)
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:323)
[Thread-6] INFO org.apache.hadoop.mapred.LocalJobRunner - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
[Thread-6] DEBUG org.apache.hadoop.mapred.LocalJobRunner - Starting mapper thread pool executor.
[Thread-6] DEBUG org.apache.hadoop.mapred.LocalJobRunner - Max local threads: 1
[Thread-6] DEBUG org.apache.hadoop.mapred.LocalJobRunner - Map tasks to process: 1
[Thread-6] INFO org.apache.hadoop.mapred.LocalJobRunner - Waiting for map tasks
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.LocalJobRunner - Starting task: attempt_local1983477500_0001_m_000000_0
[LocalJobRunner Map Task Executor #0] DEBUG org.apache.hadoop.mapred.SortedRanges - currentIndex 0 0:0
[LocalJobRunner Map Task Executor #0] DEBUG org.apache.hadoop.mapred.LocalJobRunner - mapreduce.cluster.local.dir for child : /tmp/hadoop-Administrator/mapred/local/localRunner//Administrator/jobcache/job_local1983477500_0001/attempt_local1983477500_0001_m_000000_0
[LocalJobRunner Map Task Executor #0] DEBUG org.apache.hadoop.mapred.Task - using new api for output committer
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.yarn.util.ProcfsBasedProcessTree - ProcfsBasedProcessTree currently is supported only on Linux.
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.Task - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@74c000c
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.MapTask - Processing split: file:/H:/test/order.txt:0+52
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.LocalJobRunner -
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.Task - Task:attempt_local1983477500_0001_m_000000_0 is done. And is in the process of committing
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.LocalJobRunner -
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.Task - Task attempt_local1983477500_0001_m_000000_0 is allowed to commit now
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter - Saved output of task 'attempt_local1983477500_0001_m_000000_0' to file:/H:/out/_temporary/0/task_local1983477500_0001_m_000000
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.LocalJobRunner - map
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.Task - Task 'attempt_local1983477500_0001_m_000000_0' done.
[LocalJobRunner Map Task Executor #0] INFO org.apache.hadoop.mapred.LocalJobRunner - Finishing task: attempt_local1983477500_0001_m_000000_0
[Thread-6] INFO org.apache.hadoop.mapred.LocalJobRunner - map task executor complete.
[Thread-6] DEBUG org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter - Merging data from DeprecatedRawLocalFileStatus{path=file:/H:/out/_temporary/0/task_local1983477500_0001_m_000000; isDirectory=true; modification_time=1549886350789; access_time=0; owner=; group=; permission=rwxrwxrwx; isSymlink=false} to file:/H:/out
[Thread-6] DEBUG org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter - Merging data from DeprecatedRawLocalFileStatus{path=file:/H:/out/_temporary/0/task_local1983477500_0001_m_000000/part-m-00000; isDirectory=false; length=76; replication=1; blocksize=33554432; modification_time=1549886350809; access_time=0; owner=; group=; permission=rw-rw-rw-; isSymlink=false} to file:/H:/out/part-m-00000
[Thread-6] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.fs.FileContext.getAbstractFileSystem(FileContext.java:331)
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:323)
[main] INFO org.apache.hadoop.mapreduce.Job - Job job_local1983477500_0001 running in uber mode : false
[main] INFO org.apache.hadoop.mapreduce.Job - map 100% reduce 0%
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getTaskCompletionEvents(Job.java:677)
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:323)
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:323)
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getTaskCompletionEvents(Job.java:677)
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:323)
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.updateStatus(Job.java:323)
[main] INFO org.apache.hadoop.mapreduce.Job - Job job_local1983477500_0001 completed successfully
[main] DEBUG org.apache.hadoop.security.UserGroupInformation - PrivilegedAction as:Administrator (auth:SIMPLE) from:org.apache.hadoop.mapreduce.Job.getCounters(Job.java:765)
[main] INFO org.apache.hadoop.mapreduce.Job - Counters: 18
File System Counters
FILE: Number of bytes read=218
FILE: Number of bytes written=265678
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=3
Map output records=3
Input split bytes=88
Spilled Records=0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=127401984
File Input Format Counters
Bytes Read=52
File Output Format Counters
Bytes Written=88
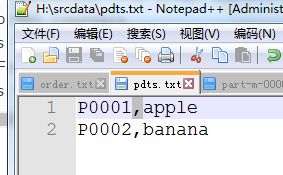
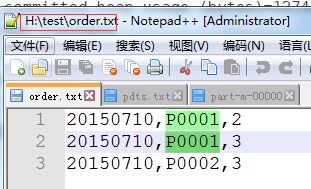
测试数据
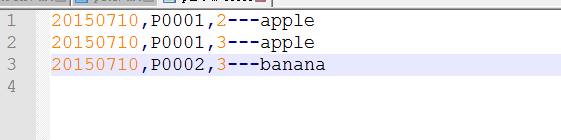
测试结果
倒排索引实现
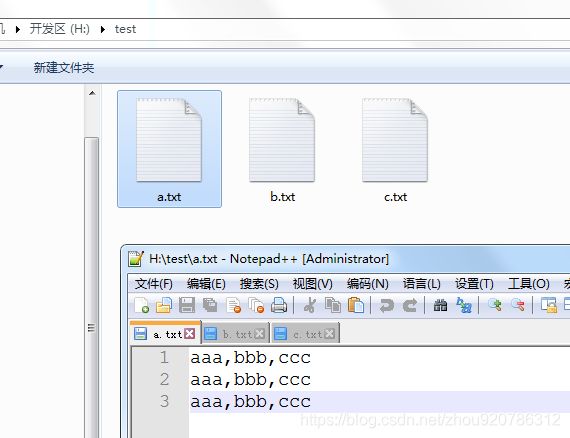
测试数据
代码1
package cn.feizhou.inverindex;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InverIndexStepOne {
static class InverIndexStepOneMapper extends Mapper {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(",");
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String fileName = inputSplit.getPath().getName();
for (String word : words) {
k.set(word + "--" + fileName);
context.write(k, v);
}
}
}
static class InverIndexStepOneReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(InverIndexStepOne.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("H:/test"));
FileOutputFormat.setOutputPath(job, new Path("H:/out2"));
job.setMapperClass(InverIndexStepOneMapper.class);
job.setReducerClass(InverIndexStepOneReducer.class);
job.waitForCompletion(true);
}
}
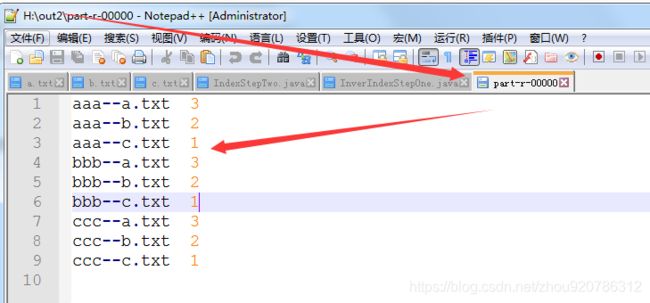
结果:
代码二(利用第一次的结果作为第二次的输入)
package cn.feizhou.inverindex;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class IndexStepTwo {
public static class IndexStepTwoMapper extends Mapper{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
//aaa--a.txt 3
String[] files = line.split("--");
context.write(new Text(files[0]), new Text(files[1]));
}
}
public static class IndexStepTwoReducer extends Reducer{
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
StringBuffer sb = new StringBuffer();
for (Text text : values) {
sb.append(text.toString().replace(" ", "-->") + ",");
}
context.write(key, new Text(sb.toString()));
}
}
public static void main(String[] args) throws Exception {
Configuration config = new Configuration();
Job job = Job.getInstance(config);
job.setMapperClass(IndexStepTwoMapper.class);
job.setReducerClass(IndexStepTwoReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("H:/out2/part-r-00000"));
FileOutputFormat.setOutputPath(job, new Path("H:/out3/"));
System.exit(job.waitForCompletion(true) ? 1:0);
}
}
结果
