链接与装载---链接原理详解
目录
前言
静态连接
第一步:地址和空间分配
第二步:符号解析和重定位
动态链接
为什么要动态链接
动态链接原理
动态链接器信息
动态链接步骤
启动动态链接器
装载共享对象
重定位和初始化
前言
为了更好地理解计算机程序的编译和链接的过程, 我们先简单回顾下计算机程序开发的历史一定会非常有益。
计算机的程序开发并非从一开始就有着这么复杂的自动化编译、 链接过程。 原始的链接概念远在高级程序语言发明之前就已经存在了, 在最开始的时候, 程序员(当时程序员的概念应该跟现在相差很大了) 先把一个程序在纸上写好, 当然当时没有很高级的语言, 用的都是机器语言, 甚至连汇编语言都没有。 当程序须要被运行时, 程序员人工将他写的程序写入到存储设备上, 最原始的存储设备之一就是纸带, 即在纸带上打相应的孔。这个过程我们可以通过下图来看到,
 图1
图1
假设有一种计算机, 它的每条指令是1个字节, 也就是8位。 我们假设有一种跳转指令, 它的高4位是0001, 表示这是一条跳转指令; 低4位存放的是跳转目的地的绝对地址。 我们可以从上图中看到, 这个程序的第一条指令就是一条跳转指令, 它的目的地址是第5条指令(注意, 第5条指令的绝对地址是4) 。 至于0和1怎么映射到纸带上, 这个应该很容易理解, 比如我们可以规定纸带上每行有8个孔位, 每个孔位代表一位, 穿孔表示0, 未穿孔表示1。现在问题来了, 程序并不是一写好就永远不变化, 它可能会经常被修改。 比如我们在第1条指令之后、 第5条指令之前插入了一条或多条指令, 那么第5条指令及后面的指令的位置将会相应地往后移动, 原先第一条指令的低4位的数字将需要相应地调整。 在这个过程中, 程序员需要人工重新计算每个子程序或跳转的目标地址。 当程序修改的时候, 这些位置都要重新计算, 十分繁琐又耗时,并且很容易出错。 这种重新计算各个目标的地址过程被叫做重定位(Relocation) 。
如果我们有多条纸带的程序, 这些程序之间可能会有类似的跨纸带之间的跳转, 这种程序经常修改导致跳转目标地址变化,在程序拥有多个模块的时候更为严重。 人工绑定进行指令的修正以确保所有的跳转目标地址都正确, 在程序规模越来越大以后变得越来越复杂和繁琐。没办法, 这种黑暗的程序员生活是没有办法容忍的。 先驱者发明了汇编语言,这相比机器语言来说是个很大的进步。 汇编语言使用接近人类的各种符号和标记来帮助记忆, 比如指令采用两个或三个字母的缩写, 记住“jmp”比记住0001XXXX是跳转(jump) 指令容易得多了; 汇编语言还可以使用符号来标记位置, 比如一个符号“divide”表示一个除法子程序的起始地址, 比记住从某个位置开始的第几条指令是除法子程序方便得多。 最重要的是, 这种符号的方法使得人们从具体的指令地址中逐步解放出来。 比如前面纸带程序中, 我们把刚开始第5条指令开始的子程序命名为“foo”, 那么第一条指令的汇编就是:
jmp foo当然人们可以使用这种符号命名子程序或跳转目标以后, 不管这个“foo”之前插入或减少了多少条指令导致“foo”目标地址发生了什么变化, 汇编器在每次汇编程序的时候会重新计算“foo”这个符号的地址, 然后把所有引用到“foo”的指令修正到这个正确的地址。 整个过程不需要人工参与, 对于一个有成百上千个类似的符号的程序, 程序员终于摆脱了这种低级的繁琐的调整地址的工作, 用一句政治口号来说叫做“极大地解放了生产力”。 符号(Symbol) 这个概念随着汇编语言的普及迅速被使用, 它用来表示一个地址, 这个地址可能是一段子程序(后来发展成函数) 的起始地址, 也可以是一个变量的起始地址。有了汇编语言以后, 生产力大大提高了, 随之而来的是软件的规模也开始日渐庞大, 这时程序的代码量也已经开始快速地膨胀, 导致人们要开始考虑将不同功能的代码以一定的方式组织起来, 使得更加容易阅读和理解, 以便于日后修改和重复使用。 自然而然, 人们开始将代码按照功能或性质划分, 分别形成不同的功能模块, 不同的模块之间按照层次结构或其他结构来组织。 这个在现代的软件源代码组织中很常见, 比如在C语言中, 最小的单位是变量和函数, 若干个变量和函数组成一个模块, 存放在一个“.c”的源代码文件里, 然后这些源代码文件按照目录结构来组织。 在比较高级的语言中, 如Java中, 每个类是一个基本的模块, 若干个类模块组成一个包(Package) , 若干个包组合成一个程序。
在现代软件开发过程中, 软件的规模往往都很大, 动辄数百万行代码, 如果都放在一个模块肯定无法想象。 所以现代的大型软件往往拥有成千上万个模块,这些模块之间相互依赖又相对独立。 这种按照层次化及模块化存储和组织源代码有很多好处, 比如代码更容易阅读、 理解、 重用, 每个模块可以单独开发、编译、 测试, 改变部分代码不需要编译整个程序等。在一个程序被分割成多个模块以后, 这些模块之间最后如何组合形成一个单一的程序是须解决的问题。 模块之间如何组合的问题可以归结为模块之间如何通信的问题, 最常见的属于静态语言的C/C++模块之间通信有两种方式, 一种是模块间的函数调用, 另外一种是模块间的变量访问。 函数访问须知道目标函数的地址, 变量访问也须知道目标变量的地址, 所以这两种方式都可以归结为一种方式, 那就是模块间符号的引用。 模块间依靠符号来通信类似于拼图版, 定义符号的模块多出一块区域, 引用该符号的模块刚好少了那一块区域, 两者一拼接刚好完美组合。 这个模块的拼接过程就是链接(Linking)。
链接的主要内容就是把各个模块之间相互引用的部分都处理好, 使得各个模块之间能够正确地衔接。 链接器所要做的工作其实跟前面所描述的“程序员人工调整地址”本质上没什么两样, 只不过现代的高级语言的诸多特性和功能, 使得编译器、 链接器更为复杂, 功能更为强大, 但从原理上来讲, 它的工作无非就是把一些指令对其他符号地址的引用加以修正。 链接过程主要包括了地址和空间分配(Addressand Storage Allocation) 、 符号决议(Symbol Resolution) 和重定位(Relocation) 等这些步骤。
符号决议有时候也被叫做符号绑定(Symbol Binding) 、 名称绑定(NameBinding) 、 名称决议(Name Resolution) , 甚至还有叫做地址绑定(AddressBinding) 、 指令绑定(Instruction Binding) 的, 大体上它们的意思都一样, 但从细节角度来区分, 它们之间还是存在一定区别的, 比如“决议”更倾向于静态链接, 而“绑定”更倾向于动态链接, 即它们所使用的范围不一样, 在这里我们统称为符号解析。
静态连接
最基本的静态链接过程如下图所示。 每个模块的源代码文件(如.c) 文件经过编译器编译成目标文件(Object File, 一般扩展名为.o或.obj) , 目标文件和库(Library) 一起链接生成可执行文件。
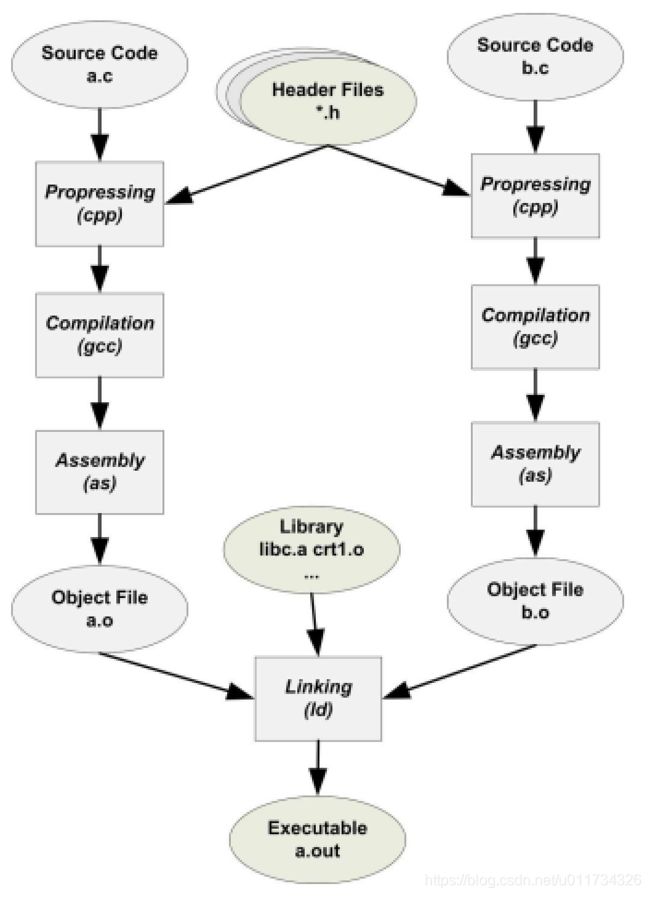 图2
图2
静态连接可以细分为两大步骤:地址和空间分配(Addressand Storage Allocation) 、 符号解析和重定位(Relocation)。我们准备两个简单的示例程序来说明:
//a.c
extern int shared;
extern void swap(int *a, int *b);
int main()
{
int a = 1000;
swap(&a, &shared);
return 0;
}
///
//b.c
int shared = 1;
void swap(int *a, int *b)
{
*a ^= *b ^= *a ^= *b;
}
经过编译以后我们就得到了“a.o”和“b.o”这两个目标文件。 从代码中可以看到, “b.c”总共定义了两个全局符号, 一个是变量“shared”, 另外一个是函数“swap”; “a.c”里面定义了一个全局符号就是“main”。 模块“a.c”里面引用到了“b.c”里面的“swap”和“shared”。 我们接下来要做的就是把“a.o”和“b.o”这两个目标文件链接在一起并最终形成一个可执行文件“ab”。
# objdump -h a.o
a.o: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000055 00000000 00000000 00000034 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 00000000 00000000 00000089 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 00000000 00000000 00000089 2**0
ALLOC
3 .comment 00000036 00000000 00000000 00000089 2**0
CONTENTS, READONLY
4 .note.GNU-stack 00000000 00000000 00000000 000000bf 2**0
CONTENTS, READONLY
5 .eh_frame 00000044 00000000 00000000 000000c0 2**2
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
# objdump -h b.o
b.o: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000039 00000000 00000000 00000034 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .data 00000004 00000000 00000000 00000070 2**2
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 00000000 00000000 00000074 2**0
ALLOC
3 .comment 00000036 00000000 00000000 00000074 2**0
CONTENTS, READONLY
4 .note.GNU-stack 00000000 00000000 00000000 000000aa 2**0
CONTENTS, READONLY
5 .eh_frame 00000038 00000000 00000000 000000ac 2**2
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
# objdump -h ab
ab: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
0 .interp 00000013 08048154 08048154 00000154 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
1 .note.ABI-tag 00000020 08048168 08048168 00000168 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .note.gnu.build-id 00000024 08048188 08048188 00000188 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
3 .gnu.hash 00000020 080481ac 080481ac 000001ac 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .dynsym 00000050 080481cc 080481cc 000001cc 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
5 .dynstr 00000060 0804821c 0804821c 0000021c 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
6 .gnu.version 0000000a 0804827c 0804827c 0000027c 2**1
CONTENTS, ALLOC, LOAD, READONLY, DATA
7 .gnu.version_r 00000030 08048288 08048288 00000288 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
8 .rel.dyn 00000008 080482b8 080482b8 000002b8 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
9 .rel.plt 00000010 080482c0 080482c0 000002c0 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
10 .init 00000023 080482d0 080482d0 000002d0 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
11 .plt 00000030 08048300 08048300 00000300 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
12 .plt.got 00000008 08048330 08048330 00000330 2**3
CONTENTS, ALLOC, LOAD, READONLY, CODE
13 .text 000001f2 08048340 08048340 00000340 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
14 .fini 00000014 08048534 08048534 00000534 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
15 .rodata 00000008 08048548 08048548 00000548 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
16 .eh_frame_hdr 00000034 08048550 08048550 00000550 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
17 .eh_frame 000000ec 08048584 08048584 00000584 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
18 .init_array 00000004 08049f08 08049f08 00000f08 2**2
CONTENTS, ALLOC, LOAD, DATA
19 .fini_array 00000004 08049f0c 08049f0c 00000f0c 2**2
CONTENTS, ALLOC, LOAD, DATA
20 .jcr 00000004 08049f10 08049f10 00000f10 2**2
CONTENTS, ALLOC, LOAD, DATA
21 .dynamic 000000e8 08049f14 08049f14 00000f14 2**2
CONTENTS, ALLOC, LOAD, DATA
22 .got 00000004 08049ffc 08049ffc 00000ffc 2**2
CONTENTS, ALLOC, LOAD, DATA
23 .got.plt 00000014 0804a000 0804a000 00001000 2**2
CONTENTS, ALLOC, LOAD, DATA
24 .data 0000000c 0804a014 0804a014 00001014 2**2
CONTENTS, ALLOC, LOAD, DATA
25 .bss 00000004 0804a020 0804a020 00001020 2**0
ALLOC
26 .comment 00000035 00000000 00000000 00001020 2**0
CONTENTS, READONLY
第一步:地址和空间分配
本阶段的目标是将输入目标文件中的相应段合并输出到可执行文件中,并分配虚拟地址。扫描所有的输入目标文件,获得它们的各个段的长度,位置和属性,并且将输入目标文件中的符号表中所有的符号定义和引用收集起来,统一放在一个全局符号表中。在这一步中,链接器能够获得所有输入目标文件的段长度,并计算出输出文件中各个段的长度与位置,建立映射关系。
在图2中, 输入目标文件中有a.o和b.o,输出文件为ELF格式的a.out(了解ELF格式可参考:理解ELF格式)。 可执行文件中的代码段,数据段等都是由输入目标文件中的代码段,数据段合并而来的, 这就涉及到合并方式的问题。目前采用的合并方式是相似段合并,比如将所有输入文件的“.text”合并到输出文件的“.text”段, 接着是“.data”段、 “.bss”段等,如下图示。
 图3
图3
合并之后, 各个段都被分配到了相应的虚拟地址(注意,虚拟地址并不是从0x0开始分配,和装载地址0x8048000相关),各个段的虚拟地址也都确定了, 事实上,各个符号的地址也都确定了(因为符号在所在段中的偏移是固定的),假设段起始地址为addr, 符号相对段起始的偏移是x,则符号的虚拟地址为addr+x;
链接器在完成地址和空间分配之后,所有符号的虚拟地址也就确定了。
第二步:符号解析和重定位
承接第一步,在确定了符号的虚拟地址之后, 接下来就需要根据重定位信息,重新调整代码中的符号地址,这一步也是链接过程的核心。
那么, 链接器是怎么知道哪些地址需要调整呢?怎么调整?事实上,在ELF文件中,有一个叫重定位表(Relocation Table)的结构专门用来保存这些信息, 重定位表往往是一个或多个段。对于需要重定位的ELF文件来说,必须包含重定位表,用来描述如何修改相应的段里的内容。
对于每个需要被重定位的ELF段都有一个对应的重定位表,一个重定位表在ELF文件中是以段的形式存在。比如代码段“.text”如有要被重定位的地方, 那么会有一个相对应叫“.rel.text”的段保存了代码段的重定位表; 如果代码段“.data”有要被重定位的地方, 就会有一个相对应叫“.rel.data”的段保存了数据段的重定位表。
我们使用objdump命令查看a.o和b.o的重定位表:
# objdump -r a.o
a.o: file format elf32-i386
RELOCATION RECORDS FOR [.text]:
OFFSET TYPE VALUE
00000027 R_386_32 shared
00000030 R_386_PC32 swap
00000049 R_386_PC32 __stack_chk_fail
RELOCATION RECORDS FOR [.eh_frame]:
OFFSET TYPE VALUE
00000020 R_386_PC32 .text
---------------------------------------------------
# objdump -r b.o
b.o: file format elf32-i386
RELOCATION RECORDS FOR [.eh_frame]:
OFFSET TYPE VALUE
00000020 R_386_PC32 .text
可以看出,a.o中有两个段需要重定位, b.o中只有一个段.eh_frame需要重定位,目标文件中用到的所有外部符号都需要重定位,每个要被重定位的地方叫一个重定位入口(Relocation Entry) , 我们可以看到“a.o”里面有4个重定位入口。 重定位入口的偏移(Offset) 表示该入口在要被重定位的段中的位置。
我们再来看看重定位表的数据结构:
typedef struct {
Elf32_Addr r_offset;
Elf32_Word r_info;
} Elf32_Rel;
看到这里,重定位的原理基本就清晰了, 目标文件中所有需要重定位的位置都记录在重定位表中, 根据重定位表,我们很容易确定需要重定位的符号所在的段的位置, 我们只需要根据符号表和指令修正方式,更新段中的地址即可。 我们可以更加深层次地理解为什么缺少符号的定义会导致链接错误。 其实重定位过程也伴随着符号的解析过程, 每个目标文件都可能定义一些符号, 也可能引用到定义在其他目标文件的符号。 重定位的过程中, 每个重定位的入口都是对一个符号的引用, 那么当链接器须要对某个符号的引用进行重定位时, 它就要确定这个符号的目标地址。 这时候链接器就会去查找由所有输入目标文件的符号表组成的全局符号表, 找到相应的符号后进行重定位。
动态链接
为什么要动态链接
静态链接使得不同的程序开发者和部门能够相对独立地开发和测试自己的程序模块, 从某种意义上来讲大大促进了程序开发的效率, 原先限制程序的规模也随之扩大。 但是慢慢地静态链接的诸多缺点也逐步暴露出来, 比如浪费内存和磁盘空间、 模块更新困难等问题, 使得人们不得不寻找一种更好的方式来组织程序的模块。要解决空间浪费和更新困难这两个问题最简单的办法就是把程序的模块相互分割开来, 形成独立的文件, 而不再将它们静态地链接在一起。
动态链接还有一个特点就是程序在运行时可以动态地选择加载各种程序模块,这个优点就是后来被人们用来制作程序的插件(Plug-in)。
动态链接原理
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分, 在程序运行时才将它们链接在一起形成一个完整的程序, 而不是像静态链接一样把所有的程序模块都链接成一个个单独的可执行文件。 动态链接涉及运行时的链接及多个文件的装载, 必需要有操作系统的支持, 因为动态链接的情况下, 进程的虚拟地址空间的分布会比静态链接情况下更为复杂, 还有一些存储管理、 内存共享、 进程线程等机制在动态链接下也会有一些微妙的变化。 目前主流的操作系统几乎都支持动态链接这种方式, 在Linux系统中, ELF动态链接文件被称为动态共享对象(DSO, Dynamic SharedObjects) , 简称共享对象, 它们一般都是以“.so”为扩展名的一些文件; 而在Windows系统中, 动态链接文件被称为动态链接库(Dynamical Linking Library) , 它们通常就是我们平时很常见的以“.dll”为扩展名的文件。从本质上讲, 普通可执行程序和动态链接库中都包含指令和数据, 这一点没有区别。 在使用动态链接库的情况下, 程序本身被分为了程序主要模块(Program1) 和动态链接库(Lib.so) , 但实际上它们都可以看作是整个程序的一个模块, 所以当我们提到程序模块时可以指程序主模块也可以指动态链接库。 当程序被装载的时候, 系统的动态链接器会将程序所需要的所有动态链接库(最基本的就是libc.so) 装载到进程的地址空间, 并且将程序中所有未决议的符号绑定到相应的动态链接库中, 并进行重定位工作。程序与libc.so之间真正的链接工作是由动态链接器完成的, 而不是由我们前面看到过的静态链接器ld完成的。 也就是说, 动态链接是把链接这个过程从本来的程序装载前被推迟到了装载的时候。
在动态链接情况下, 操作系统还不能在装载完可执行文件之后就把控制权交给可执行文件, 因为我们知道可执行文件依赖于很多共享对象。 这时候, 可执行文件里对于很多外部符号的引用还处于无效地址的状态, 即还没有跟相应的共享对象中的实际位置链接起来。 所以在映射完可执行文件之后, 操作系统会先启动一个动态链接器(Dynamic Linker) 。在Linux下, 动态链接器ld.so实际上是一个共享对象, 操作系统同样通过映射的方式将它加载到进程的地址空间中。 操作系统在加载完动态链接器之后, 就将控制权交给动态链接器的入口地址(与可执行文件一样, 共享对象也有入口地址) 。 当动态链接器得到控制权之后, 它开始执行一系列自身的初始化操作,然后根据当前的环境参数, 开始对可执行文件进行动态链接工作。 当所有动态链接工作完成以后, 动态链接器会将控制权转交到可执行文件的入口地址, 程序开始正式执行。
使用ldd命令可以看出,动态链接器是静态链接生成的
$ ldd /lib/ld-linux.so.2
statically linked
动态链接器信息
我们知道,在映射完可执行文件之后, 操作系统会先启动一个动态链接器(Dynamic Linker) 。那么这个动态链接器位于什么位置呢?
实际上, 动态链接器的位置既不是由系统配置指定, 也不是由环境参数决定, 而是由ELF可执行文件决定。 在动态链接的ELF可执行文件中, 有一个专门的段叫做“.interp”段(“interp”是“interpreter”(解释器) 的缩写) 。 如果我们使用objdump工具来查看, 可以看到“.interp”内容:
# objdump -s a.out
a.out: file format elf32-i386
Contents of section .interp:
8048154 2f6c6962 2f6c642d 6c696e75 782e736f /lib/ld-linux.so
8048164 2e3200 .2. “.interp”的内容很简单, 里面保存的就是一个字符串, 这个字符串就是可执行文件所需要的动态链接器的路径, 在Linux下, 可执行文件所需要的动态链接器的路径几乎都是“/lib/ld-linux.so.2”, 在Linux的系统中, /lib/ld-linux.so.2通常是一个软链接, 比如在我的机器上, 它指向/lib/ld-2.23.so, 这个才是真正的动态链接器。
# ls -l /lib/ld-linux.so.2
lrwxrwxrwx 1 root root 25 5月 20 11:12 /lib/ld-linux.so.2 -> i386-linux-gnu/ld-2.23.so
动态链接器在Linux下是Glibc的一部分, 也就是属于系统库级别的, 它的版本号往往跟系统中的Glibc库版本号是一样的, 比如我的系统中安装的是Glibc2.23, 那么相应的动态链接器也就是/lib/ld-2.23.so。 当系统中的Glibc库更新或者安装其他版本的时候, /lib/ld-linux.so.2这个软链接就会指向到新的动态链接器, 而可执行文件本身不需要修改“.interp”中的动态链接器路径来适应系统的升级。
环境变量LD_DEBUG, 这个变量可以打开动态链接器的调试功能, 当我们设置这个变量时, 动态链接器会在运行时打印出各种有用的信息, 对于我们开发和调试共享库有很大的帮助。 比如我们可以将LD_DEBUG设置成“files”,
$LD_DEBUG=files ./HelloWorld.out动态链接器打印出了整个装载过程, 显示程序依赖于哪个共享库并且按照什么步骤装载和初始化, 共享库装载时的地址等。 LD_DEBUG还可以设置成其他值, 比如:
“bindings”显示动态链接的符号绑定过程。
“libs”显示共享库的查找过程。
“versions”显示符号的版本依赖关系。
“reloc”显示重定位过程。“symbols”显示符号表查找过程。
“statistics”显示动态链接过程中的各种统计信息
动态链接步骤
动态链接的步骤基本上分为3步: 先是启动动态链接器本身, 然后装载所有需要的共享对象, 最后是重定位和初始化。
启动动态链接器
动态链接器本身也是一个共享对象, 但它是一个特殊的存在。 对于普通共享对象文件来说, 它的重定位工作由动态链接器来完成; 它也可以依赖于其他共享对象, 其中的被依赖的共享对象由动态链接器负责链接和装载。可是对于动态链接器本身来说, 它的重定位工作由谁来完成? 它是否可以依赖于其他的共享对象?这是一个“鸡生蛋, 蛋生鸡”的问题, 为了解决这种无休止的循环, 动态链接器这个“鸡”必须有些特殊性。 首先是, 动态链接器本身不可以依赖于其他任何共享对象; 其次是动态链接器本身所需要的全局和静态变量的重定位工作由它本身完成。 对于第一个条件我们可以人为地控制, 在编写动态链接器时保证不使用任何系统库、 运行库; 对于第二个条件, 动态链接器必须在启动时有一段非常精巧的代码可以完成这项艰巨的工作而同时又不能用到全局和静态变量。 这种具有一定限制条件的启动代码往往被称为自举(Bootstrap) 。
动态链接器入口地址即是自举代码的入口, 当操作系统将进程控制权交给动态链接器时, 动态链接器的自举代码即开始执行。 自举代码首先会找到它自己的GOT。 而GOT的第一个入口保存的即是“.dynamic”段的偏移地址, 由此找到了动态连接器本身的“.dynamic”段。 通过“.dynamic”中的信息, 自举代码便可以获得动态链接器本身的重定位表和符号表等, 从而得到动态链接器本身的重定位入口, 先将它们全部重定位。 从这一步开始, 动态链接器代码中才可以开始使用自己的全局变量和静态变量。实际上在动态链接器的自举代码中, 除了不可以使用全局变量和静态变量之外, 甚至不能调用函数, 即动态链接器本身的函数也不能调用。 这是为什么呢? 其实我们在前面分析地址无关代码时已经提到过, 实际上使用PIC模式编译的共享对象, 对于模块内部的函数调用也是采用跟模块外部函数调用一样的方式, 即使用GOT/PLT的方式, 所以在GOT/PLT没有被重定位之前, 自举代码不可以使用任何全局变量, 也不可以调用函数。
装载共享对象
完成基本自举以后, 动态链接器将可执行文件和链接器本身的符号表都合并到一个符号表当中, 我们可以称它为全局符号表(Global Symbol Table) 。 然后链接器开始寻找可执行文件所依赖的共享对象, 我们前面提到过“.dynamic”段中, 有一种类型的入口是DT_NEEDED, 它所指出的是该可执行文件(或共享对象) 所依赖的共享对象。 由此, 链接器可以列出可执行文件所需要的所有共享对象, 并将这些共享对象的名字放入到一个装载集合中。 然后链接器开始从集合里取一个所需要的共享对象的名字, 找到相应的文件后打开该文件, 读取相应的ELF文件头和“.dynamic”段, 然后将它相应的代码段和数据段映射到进程
空间中。 如果这个ELF共享对象还依赖于其他共享对象, 那么将所依赖的共享对象的名字放到装载集合中。 如此循环直到所有依赖的共享对象都被装载进来为止, 当然链接器可以有不同的装载顺序, 如果我们把依赖关系看作一个图的话, 那么这个装载过程就是一个图的遍历过程, 链接器可能会使用深度优先或者广度优先或者其他的顺序来遍历整个图, 这取决于链接器, 比较常见的算法一般都是广度优先的。当一个新的共享对象被装载进来的时候, 它的符号表会被合并到全局符号表中, 所以当所有的共享对象都被装载进来的时候, 全局符号表里面将包含进程中所有的动态链接所需要的符号。
动态装载共享对象涉及一个符号优先级的问题, 假设有可执行程序main, 它依赖于库a.so和b.so,而a.so和b.so中均存在swap函数的实现, 那么在main中调用swap函数将会是什么结果?
gcc -fPIC -shared b.c -o b.so
gcc -fPIC -shared a.c -o a.so
gcc main.c a.so b.so -Xlinker -rpath ./可以肯定的是, 这种情况是不会报出重复定义和链接错误的,至于main调用的swap是哪个库中的, 取决于链接器的实现。在linux动态链接器中,它定义了一个规则, 那就是当一个符号需要被加入全局符号表时, 如果相同的符号名已经存在, 则后加入的符号被忽略。 从动态链接器的装载顺序可以看到, 它是按照广度优先的顺序进行装载的, 首先是main, 然后是a.so、 b.so,所以, 最终main调用的swap函数是a.so库中的。
重定位和初始化
当上面的步骤完成之后, 链接器开始重新遍历可执行文件和每个共享对象的重定位表, 将它们的GOT/PLT中的每个需要重定位的位置进行修正。 因为此时动态链接器已经拥有了进程的全局符号表, 所以这个修正过程也显得比较容易,跟我们前面提到的地址重定位的原理基本相同。
重定位完成之后, 如果某个共享对象有“.init”段, 那么动态链接器会执行“.init”段中的代码, 用以实现共享对象特有的初始化过程, 比如最常见的, 共享对象中的C++的全局/静态对象的构造就需要通过“.init”来初始化。 相应地, 共享对象中还可能有“.finit”段, 当进程退出时会执行“.finit”段中的代码, 可以用来实现类似C++全局对象析构之类的操作。如果进程的可执行文件也有“.init”段, 那么动态链接器不会执行它, 因为可执行文件中的“.init”段和“.finit”段由程序初始化部分代码负责执行。当完成了重定位和初始化之后, 所有的准备工作就宣告完成了, 所需要的共享对象也都已经装载并且链接完成了, 这时候动态链接器就如释重负, 将进程的控制权转交给程序的入口并且开始执行。