携程研发方向秋招专业笔试
答案在问题后
1、对有18个元素的有序表R[1…18]进行二分查找,则查找A[3]的比较序列为:
A、1,2,3
B、9,5,2,3
C、9,5,3
D、9,4,2,3
2、一棵二叉树的先序遍历序列为A,B,C,D,E,F,中序遍历序列为C,B,A,E,D,F,则后序遍历序列为:
A、C,B,E,F,D,A
B、F,E,D,C,B,A
C、C,B,E,D,F,A
D、不确定
3、考虑以下JAVA排序代码,对于array为{15,0,6,9,3}时,运行sort方法,则最终排序结果为:
public void sort(Comparable[] a) {
int N = a.length;
int h = 1;
while (h < N / 3) {
h = 3 * h + 1;// 1, 4, 13, 40, …
}
while (h >= 1) {
for (int i = h; i < N; i++) {
for (int j = i; j >= h && compareElement(a[j], a[j - h]); j -= h) {
exch(a, j, j - h);
}
}
h = h / 3;
}
}
public boolean compareElement(Comparable v, Comparable w) {
return v.compareTo(w) < 0;
}
public static void exch(Comparable[] a, int i, int j) {
Comparable t = a[i];
a[i] = a[j];
a[j] = t;
}
A、15,0,6,9,3
B、0,15,6,9,3
C、15,0,6,3,9
D、0,3,6,9,15
4、以下哪项说法正确的是?
A、垃圾回收线程的优先级很高,以保证不再 使用的内存将被及时回收
B、垃圾收集允许程序开发者明确指定释放 哪一个对象
C、垃圾回收机制保证了Java程序不会出现内存溢出
D、其他选项都不对
5、给出下列JAVA程序执行结果:
public class Test {
public static Test t1=new Test();
{
System.out.println(“blockA”);
}
static {
System.out.println(“blockB”);
}
public static void main(String[] args){
Test t2=new Test();
}
}
A、blockA,blockB,blockA
B、blockB,blockA,blockA
C、blockA,blockB
D、blockB,blockA
6、给出下列JAVA程序执行结果:
public static void main(String args[]) {
Thread t = new Thread() {
public void run() {
pong();
}
};
t.run();
System.out.print(“ping”);
}
static void pong() {
System.out.print(“pong”);
}
A、pingpong
B、pongping
C、pingpong和pongping都有可能
D、都不输出
7、以下有关 Abstract Factory(抽象工厂)模式正确的是:
A、Abstract Factory 的实例化方法就是具体工厂方法
B、Abstract Factory 类和具体工厂方法可以分离,每个具体工厂负责一个抽象工厂方法接口的实现
C、由于 Abstract Factory 类和具体工厂方法可以分离,因此在实现时会产生更多的类
D、当问题存在相同的对象用于解决不同的情形时,应该使用抽象工厂模式
8、软件开发的螺旋模型综合了瀑布模型和演化模型的优点,还增加了什么?
A、版本管理
B、风险分析
C、可行性分析
D、系统集成
9、下列选项中,不能构成折半查找中关键字比较序列的是?
A、500,200,450,180
B、500,450,200,180
C、180,500,200,450
D、180,200,500,450
10、设计一个数据结构,实现LRU Cache的功能(Least Recently Used – 最近最少使用缓存)。它支持如下2个操作: get 和 put。
int get(int key) – 如果key已存在,则返回key对应的值value(始终大于0);如果key不存在,则返回-1。
void put(int key, int value) – 如果key不存在,将value插入;如果key已存在,则使用value替换原先已经存在的值。如果容量达到了限制,LRU Cache需要在插入新元素之前,将最近最少使用的元素删除。
请特别注意“使用”的定义:新插入或获取key视为被使用一次;而将已经存在的值替换更新,不算被使用。
限制:请在O(1)的时间复杂度内完成上述2个操作。
个人想法,仅供参考
1、答案解析:
正确答案: D
题目的意思是:
在[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18]中寻找3,利用二分法的查找的过程;
第一次尝试,[1,18]区间,(1+18)/ 2 = 9, 发现9大于3,所以肯定在左边;
第二次尝试,[1,8]区间,因为上一步发现9大了,所以确定上限是8,(1+8)/ 2 = 4,4大于3;
第三次尝试,[1,3]区间,道理如上,(1+3)/ 2 = 2,2小与2;
第四次尝试,[3,3],3==3,找到了;
结束。
2、答案解析:
正确答案: A
先知道什么是先序、中序、后序遍历
先序遍历:根、左、右
中序遍历:左、根、右
后序遍历:左、右、根
这里先序是A,B,C,D,E,F,所以根是A;中序遍历序列为C,B,A,E,D,F,所以C,B在根节点A的左侧,D,E,F在右侧;
然后我们先来确定A左侧的结构:
A左侧只有B和C。根据先序,可以知道B是根;根据中序可以知道C是B的左孩子。
然后是A右侧的结构:
A右侧是D,E,F。根据先序,可以知道D是根;
那么E是D的左孩子还是右孩子呢?根据中序可知E一定是D的左孩子;
根据中序,F在D的右侧,所以它只能是D的右孩子,不可能是E的左/右孩子
树形结构如图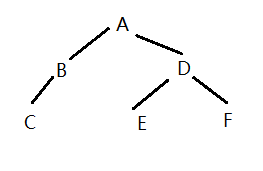
3、答案解析
答案是:D
这题本质上就是希尔排序。
具体希尔排序方法,参考:https://blog.csdn.net/gaoruowen1/article/details/81015244
4、答案解析
正确答案: D
A:垃圾回收线程的优先级靠后,原因有:GC占资源,不到万不得已不启动GC,而主线程里面的业务逻辑才是核心,只有内存不够时或者CPU空闲时才会GC。
B:垃圾回收归GC管。
C:GC只是保证了大部分情况,但是代码的组合有无限的可能,这是GC无法周全考虑到的,因此需要JVM调优。
5、答案解析:
正确答案: A
创建类的静态变量和实例变量都会触发类加载。类加载时静态代码块只加载一次。在运行 Test t2=new Test(); 时创建实例变量 触发类加载,在加载该类时 public static Test t1=new Test(); 创建类静态变量 触发类加载。首先执行public static Test t1=new Test(); 打印blockA blockB.后执行 Test t2=new Test(); 打印blockA。如果public static Test t1=new Test();放在静态代码块后面则是选B,先打印blockB,在执行public static Test t1=new Test(); 打印blockA。
6、答案解析:
正确答案: B
run()方法不会启动新的线程,这里只有一个主线程,所以顺序执行,假如这里用start()方法,就会启动新的线程,而ping和pong两个线程并不知道哪个先执行就是答案就是B。
7、答案解析:
正确答案: B
抽象工厂是对具体工厂的抽象,具体工厂是对实例的抽象
8、答案解析
正确答案: B
螺旋模型 是一种演化 软件开发过程 模型,它兼顾了 快速原型 的 迭代 的特征以及 瀑布模型 的系统化与严格监控。螺旋模型最大的特点在于引入了其他模型不具备的风险分析,使软件在无法排除重大风险时有机会停止,以减小损失。同时,在每个迭代阶段构建原型是螺旋模型用以减小风险的途径。螺旋模型更适合大型的昂贵的系统级的软件应用。
9、答案解析
正确答案: A
A:第一次查找为0-500;第二次查找200-500;第三次查找不论是200-450还是450-500都不可能包含180所以错误
B:第一次查找为0-500;第二次查找0-450;第三次查找0-200;第四次查找0-180
C:第一次查找为0-180;第二次查找180-500;第三次查找200-500;第四次查找200-450或450-500
D:第一次查找为0-180;第二次查找200-末尾;第三次查找200-500;第四次查找200-450或450-500
10、答案解析
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
public clas***ain{
private class Node {
Node next, prev;
int key, value;
Node (){}
Node(int key, int value) {
this.value = value;
this.key = key;
}
}
private Node head, tail;
private Map
private int count, capacity;
private void addNode(Node node) {
Node old = head.next;
head.next = node;
node.prev = head;
node.next = old;
old.prev = node;
}
private void removeNode(Node node) {
Node previous = node.prev;
previous.next = node.next;
node.next.prev = previous;
}
private void moveToHead(Node node) {
removeNode(node);
addNode(node);
}
private Node popTail() {
Node pre = tail.prev;
removeNode(pre);
return pre;
}
public Main(int capacity) {
this.capacity = capacity;
this.count = 0;
map = new HashMap<>();
head = new Node();
tail = new Node();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
Node node = map.get(key);
if (node == null) return -1;
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
Node node = map.get(key);
if (node == null) {
if (count == capacity) {
map.remove(popTail().key);
--count;
}
Node fresh = new Node(key, value);
map.put(key, fresh);
addNode(fresh);
count++;
} else {
node.value = value;
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int capacity = Integer.valueOf(scanner.nextLine().trim());
Main instance = new Main(capacity);
while (scanner.hasNextLine()) {
String command = scanner.nextLine().trim();
if (capacity >0 && command.charAt(0) == ‘p’) {
int key = Integer.valueOf(command.substring(2, command.lastIndexOf(" “)));
int value = Integer.valueOf(command.substring(command.lastIndexOf(” ")+1));
instance.put(key, value);
}else if(command.charAt(0) == ‘g’) {
if (capacity <= 0) {
System.out.println(-1);
}else {
int key = Integer.valueOf(command.substring(2));
System.out.println(instance.get(key));
}
}
}
}
}