正则表达式
正则表达式的定义
正则表达式是由普通字符和特殊字符(也叫元字符或限定符)组成的文字模板. 如下便是简单的匹配连续数字的正则表达式:
/[0-9]+/
/\d+/
“\d” 就是元字符, 而 “+” 则是限定符.
元字符
| 元字符 | 描述 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \d | 匹配数字, 等价于字符组[0-9] |
| \w | 匹配字母, 数字, 下划线或汉字 |
| \s | 匹配任意的空白符(包括制表符,空格,换行等) |
| \b | 匹配单词开始或结束的位置 |
| ^ | 匹配行首 |
| $ | 匹配行尾 |
反义元字符
| 元字符 | 描述 |
|---|---|
| \D | 匹配非数字的任意字符, 等价于[^0-9] |
| \W | 匹配除字母,数字,下划线或汉字之外的任意字符 |
| \S | 匹配非空白的任意字符 |
| \B | 匹配非单词开始或结束的位置 |
| [^x] | 匹配除x以外的任意字符 |
可以看出正则表达式严格区分大小写.
重复限定符
限定符共有6个, 假设重复次数为x次, 那么将有如下规则:
| 限定符 | 描述 |
|---|---|
| * | x>=0 |
| + | x>=1 |
| ? | x=0 or x=1 |
| {n} | x=n |
| {n,} | x>=n |
| {n,m} | n<=x<=m |
字符组
[…] 匹配中括号内字符之一. 如: [xyz] 匹配字符 x, y 或 z. 如果中括号中包含元字符, 则元字符降级为普通字符, 不再具有元字符的功能, 如 [+.?] 匹配 加号, 点号或问号.
排除性字符组
[^…] 匹配任何未列出的字符,. 如: [^x] 匹配除x以外的任意字符.
多选结构
| 就是或的意思, 表示两者中的一个. 如: a|b 匹配a或者b字符.
括号
括号 常用来界定重复限定符的范围, 以及将字符分组. 如: (ab)+ 可以匹配abab..等, 其中 ab 便是一个分组.
转义字符
\ 即转义字符, 通常 \ * + ? | { [ ( ) ] }^ $ . # 和 空白 这些字符都需要转义.
操作符的运算优先级
- \ 转义符
- (), (?:), (?=), [] 圆括号或方括号
- *, +, ?, {n}, {n,}, {n,m} 限定符
- ^, $ 位置
- | “或” 操作
测试
我们来测试下上面的知识点, 写一个匹配手机号码的正则表达式, 如下:
(\+86)?1\d{10}① “\+86” 匹配文本 “+86”, 后面接元字符问号, 表示可匹配1次或0次, 合起来表示 “(\+86)?” 匹配 “+86” 或者 “”.
② 普通字符”1” 匹配文本 “1”.
③ 元字符 “\d” 匹配数字0到9, 区间量词 “{10}” 表示匹配 10 次, 合起来表示 “\d{10}” 匹配连续的10个数字.
以上, 匹配结果如下:

修饰符
javaScript中正则表达式默认有如下五种修饰符:
- g (全文查找), 如上述截图, 实际上就开启了全文查找模式.
- i (忽略大小写查找)
- m (多行查找)
- y (ES6新增的粘连修饰符)
- u (ES6新增)
常用的正则表达式
- 汉字: ^[\u4e00-\u9fa5]{0,}$
- Email: ^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
- URL: ^https?://([\w-]+.)+[\w-]+(/[\w-./?%&=]*)?$
- 手机号码: ^1\d{10}$
- 身份证号: ^(\d{15}|\d{17}(\d|X))$
- 中国邮政编码: [1-9]\d{5}(?!\d) (邮政编码为6位数字)
密码验证
密码验证是常见的需求, 一般来说, 常规密码大致会满足规律: 6-16位, 数字, 字母, 字符至少包含两种, 同时不能包含中文和空格. 如下便是常规密码验证的正则描述:
var reg = /(?!^[0-9]+$)(?!^[A-z]+$)(?!^[^A-z0-9]+$)^[^\s\u4e00-\u9fa5]{6,16}$/;正则的几大家族
正则表达式分类
在 linux 和 osx 下, 常见的正则表达式, 至少有以下三种:
- 基本的正则表达式( Basic Regular Expression 又叫 Basic RegEx 简称 BREs )
- 扩展的正则表达式( Extended Regular Expression 又叫 Extended RegEx 简称 EREs )
- Perl 的正则表达式( Perl Regular Expression 又叫 Perl RegEx 简称 PREs )
正则表达式比较
| 字符 | 说明 | Basic RegEx | Extended RegEx | python RegEx | Perl regEx |
|---|---|---|---|---|---|
| 转义 | |||||
| ^ | 匹配行首,例如’^dog’匹配以字符串dog开头的行(注意:awk 指令中,’^’则是匹配字符串的开始) | ^ | ^ | ^ | ^ |
| $ | 匹配行尾,例如:’^、dog\$’ 匹配以字符串 dog 为结尾的行(注意:awk 指令中,’$’则是匹配字符串的结尾) | $ | $ | $ | $ |
| ^$ | 匹配空行 | ^$ | ^$ | ^$ | ^$ |
| ^string$ | 匹配行,例如:’^dog$’匹配只含一个字符串 dog 的行 | ^string$ | ^string$ | ^string$ | ^string$ |
| \< | 匹配单词,例如:’\| \< |
\< |
不支持 |
不支持(但可以使用\b来匹配单词,例如:’\bfrog’) |
|
| > | 匹配单词,例如:’frog>‘(等价于’frog\b ‘),匹配以 frog 结尾的单词 | > | > | 不支持 | 不支持(但可以使用\b来匹配单词,例如:’frog\b’) |
| \ | 匹配一个单词或者一个特定字符,例如:’\‘(等价于’\bfrog\b’)、’\ ‘ | \ | \ | 不支持 | 不支持(但可以使用\b来匹配单词,例如:’\bfrog\b’ |
| () | 匹配表达式,例如:不支持’(frog)’ | 不支持(但可以使用,如:dog | () | () | () |
| 匹配表达式,例如:不支持’(frog)’ | 不支持(同()) | 不支持(同()) | 不支持(同()) | ||
| ? | 匹配前面的子表达式 0 次或 1 次(等价于{0,1}),例如:where(is)?能匹配”where” 以及”whereis” | 不支持(同\?) | ? | ? | ? |
| \? | 匹配前面的子表达式 0 次或 1 次(等价于’{0,1}‘),例如:’whereis\? ‘能匹配 “where”以及”whereis” | \? | 不支持(同?) | 不支持(同?) | 不支持(同?) |
| ? | 当该字符紧跟在任何一个其他限制符(*, +, ?, {n},{n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,’o+?’ 将匹配单个”o”,而 ‘o+’ 将匹配所有 ‘o’ | 不支持 | 不支持 | 不支持 | 不支持 |
| . | 匹配除换行符(’\n’)之外的任意单个字符(注意:awk 指令中的句点能匹配换行符) | . | .(如果要匹配包括“\n”在内的任何一个字符,请使用: [\s\S] | . | .(如果要匹配包括“\n”在内的任何一个字符,请使用:’ [.\n] ‘ |
| * | 匹配前面的子表达式 0 次或多次(等价于{0, }),例如:zo* 能匹配 “z”以及 “zoo” | * | * | * | * |
| + | 匹配前面的子表达式 1 次或多次(等价于’{1, }‘),例如:’whereis+ ‘能匹配 “whereis”以及”whereisis” | + | 不支持(同+) | 不支持(同+) | 不支持(同+) |
| + | 匹配前面的子表达式 1 次或多次(等价于{1, }),例如:zo+能匹配 “zo”以及 “zoo”,但不能匹配 “z” | 不支持(同\+) | + | + | + |
| {n} | n 必须是一个 0 或者正整数,匹配子表达式 n 次,例如:zo{2}能匹配 | 不支持(同\{n\}) | {n} | {n} | {n} |
| {n,} | “zooz”,但不能匹配 “Bob”n 必须是一个 0 或者正整数,匹配子表达式大于等于 n次,例如:go{2,} | 不支持(同\{n,\}) | {n,} | {n,} | {n,} |
| {n,m} | 能匹配 “good”,但不能匹配 godm 和 n 均为非负整数,其中 n <= m,最少匹配 n 次且最多匹配 m 次 ,例如:o{1,3}将配”fooooood” 中的前三个 o(请注意在逗号和两个数之间不能有空格) | 不支持(同\{n,m\}) | {n,m} | {n,m} | {n,m} |
| x l y | 匹配 x 或 y | 不支持(同x \l y | x l y | x l y | x l y |
| [0-9] | 匹配从 0 到 9 中的任意一个数字字符(注意:要写成递增) | [0-9] | [0-9] | [0-9] | [0-9] |
| [xyz] | 字符集合,匹配所包含的任意一个字符,例如:’[abc]’可以匹配”lay” 中的 ‘a’(注意:如果元字符,例如:. *等,它们被放在[ ]中,那么它们将变成一个普通字符) | [xyz] | [xyz] | [xyz] | [xyz] |
| [^xyz] | 负值字符集合,匹配未包含的任意一个字符(注意:不包括换行符),例如:’[^abc]’ 可以匹配 “Lay” 中的’L’(注意:[^xyz]在awk 指令中则是匹配未包含的任意一个字符+换行符) | [^xyz] | [^xyz] | [^xyz] | [^xyz] |
| [A-Za-z] | 匹配大写字母或者小写字母中的任意一个字符(注意:要写成递增) | [A-Za-z] | [A-Za-z] | [A-Za-z] | [A-Za-z] |
| [^A-Za-z] | 匹配除了大写与小写字母之外的任意一个字符(注意:写成递增) | [^A-Za-z] | [^A-Za-z] | [^A-Za-z] | [^A-Za-z] |
| \d | 匹配从 0 到 9 中的任意一个数字字符(等价于 [0-9]) | 不支持 | 不支持 | \d | \d |
| \D | 匹配非数字字符(等价于 [^0-9]) | 不支持 | 不支持 | \D | \D |
| \S | 匹配任何非空白字符(等价于[^\f\n\r\t\v]) | 不支持 | 不支持 | \S | \S |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等(等价于[ \f\n\r\t\v]) | 不支持 | 不支持 | \s | \s |
| \W | 匹配任何非单词字符 (等价于[^A-Za-z0-9_]) | \W | \W | \W | \W |
| \w | 匹配包括下划线的任何单词字符(等价于[A-Za-z0-9_]) | \w | \w | \w | \w |
| \B | 匹配非单词边界,例如:’er\B’ 能匹配 “verb” 中的’er’,但不能匹配”never” 中的’er’ | \B | \B | \B | \B |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置,例如: ‘er\b’ 可以匹配”never” 中的 ‘er’,但不能匹配 “verb” 中的’er’ | \b | \b | \b | \b |
| \t | 匹配一个横向制表符(等价于 \x09和 \cI) | 不支持 | 不支持 | \t | \t |
| \v | 匹配一个垂直制表符(等价于 \x0b和 \cK) | 不支持 | 不支持 | \v | \v |
| \n | 匹配一个换行符(等价于 \x0a 和\cJ) | 不支持 | 不支持 | \n | \n |
| \f | 匹配一个换页符(等价于\x0c 和\cL) | 不支持 | 不支持 | \f | \f |
| \r | 匹配一个回车符(等价于 \x0d 和\cM) | 不支持 | 不支持 | \r | \r |
| \ | 匹配转义字符本身”\” | \ | \ | \ | \ |
| \cx | 匹配由 x 指明的控制字符,例如:\cM匹配一个Control-M 或回车符,x 的值必须为A-Z 或 a-z 之一,否则,将 c 视为一个原义的 ‘c’ 字符 | 不支持 | 不支持 | \cx | |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长,例如:’\x41’ 匹配 “A”。’\x041’ 则等价于’\x04’ & “1”。正则表达式中可以使用 ASCII 编码 | 不支持 | 不支持 | \xn | |
| \num | 匹配 num,其中 num是一个正整数。表示对所获取的匹配的引用 | 不支持 | \num | \num | |
| [:alnum:] | 匹配任何一个字母或数字([A-Za-z0-9]),例如:’[[:alnum:]] ‘ | [:alnum:] | [:alnum:] | [:alnum:] | [:alnum:] |
| [:alpha:] | 匹配任何一个字母([A-Za-z]), 例如:’ [[:alpha:]] ‘ | [:alpha:] | [:alpha:] | [:alpha:] | [:alpha:] |
| [:digit:] | 匹配任何一个数字([0-9]),例如:’[[:digit:]] ‘ | [:digit:] | [:digit:] | [:digit:] | [:digit:] |
| [:lower:] | 匹配任何一个小写字母([a-z]), 例如:’ [[:lower:]] ‘ | [:lower:] | [:lower:] | [:lower:] | [:lower:] |
| [:upper:] | 匹配任何一个大写字母([A-Z]) | [:upper:] | [:upper:] | [:upper:] | [:upper:] |
| [:space:] | 任何一个空白字符: 支持制表符、空格,例如:’ [[:space:]] ‘ | [:space:] | [:space:] | [:space:] | [:space:] |
| [:blank:] | 空格和制表符(横向和纵向),例如:’[[:blank:]]’ó’[\s\t\v]’ | [:blank:] | [:blank:] | [:blank:] | [:blank:] |
| [:graph:] | 任何一个可以看得见的且可以打印的字符(注意:不包括空格和换行符等),例如:’[[:graph:]] ‘ | [:graph:] | [:graph:] | [:graph:] | [:graph:] |
| [:print:] | 任何一个可以打印的字符(注意:不包括:[:cntrl:]、字符串结束符’\0’、EOF 文件结束符(-1), 但包括空格符号),例如:’[[:print:]] ‘ | [:print:] | [:print:] | [:print:] | [:print:] |
| [:cntrl:] | 任何一个控制字符(ASCII 字符集中的前 32 个字符,即:用十进制表示为从 0 到31,例如:换行符、制表符等等),例如:’ [[:cntrl:]]’ | [:cntrl:] | [:cntrl:] | [:cntrl:] | [:cntrl:] |
| [:punct:] | 任何一个标点符号(不包括:[:alnum:]、[:cntrl:]、[:space:]这些字符集) | [:punct:] | [:punct:] | [:punct:] | [:punct:] |
| [:xdigit:] | 任何一个十六进制数(即:0-9,a-f,A-F) | [:xdigit:] | [:xdigit:] | [:xdigit:] | [:xdigit:] |
注意
- js中支持的是EREs.
- 当使用 BREs ( 基本正则表达式 ) 时,必须在下列这些符号(?,+,|,{,},(,))前加上转义字符 \ .
- 上述[[:xxxx:]] 形式的正则表达式, 是php中内置的通用字符簇, js中并不支持.
linux/osx下常用命令与正则表达式的关系
我曾经尝试在 grep 和 sed 命令中书写正则表达式, 经常发现不能使用元字符, 而且有时候需要转义, 有时候不需要转义, 始终不能摸清它的规律. 如果恰好你也有同样的困惑, 那么请往下看, 相信应该能有所收获.
grep , egrep , sed , awk 正则表达式特点
-
grep 支持:BREs、EREs、PREs 正则表达式
grep 指令后不跟任何参数, 则表示要使用 “BREs”
grep 指令后跟 ”-E” 参数, 则表示要使用 “EREs”
grep 指令后跟 “-P” 参数, 则表示要使用 “PREs”
-
egrep 支持:EREs、PREs 正则表达式
egrep 指令后不跟任何参数, 则表示要使用 “EREs”
egrep 指令后跟 “-P” 参数, 则表示要使用 “PREs”
-
sed 支持: BREs、EREs
sed 指令默认是使用 “BREs”
sed 指令后跟 “-r” 参数 , 则表示要使用“EREs”
-
awk 支持 EREs, 并且默认使用 “EREs”
正则表达式初阶技能
贪婪模式与非贪婪模式
默认情况下, 所有的限定词都是贪婪模式, 表示尽可能多的去捕获字符; 而在限定词后增加?, 则是非贪婪模式, 表示尽可能少的去捕获字符. 如下:
var str = "aaab",
reg1 = /a+/, //贪婪模式
reg2 = /a+?/;//非贪婪模式
console.log(str.match(reg1)); //["aaa"], 由于是贪婪模式, 捕获了所有的a
console.log(str.match(reg2)); //["a"], 由于是非贪婪模式, 只捕获到第一个a
实际上, 非贪婪模式非常有效, 特别是当匹配html标签时. 比如匹配一个配对出现的div, 方案一可能会匹配到很多的div标签对, 而方案二则只会匹配一个div标签对.
var str = "< class='v1'>< div class='v2'>test< /div>< input type='text'/>< /div>";
var reg1 = /< div.*<\/div>/; //方案一,贪婪匹配
var reg2 = /< div.*?<\/div>/;//方案二,非贪婪匹配
console.log(str.match(reg1));//"< div class='v1'>< div class='v2'>test< /div>< input type='text'/>< /div>"
console.log(str.match(reg2));//"< div class='v1'>< div class='v2'>test< /div>"
区间量词的非贪婪模式
一般情况下, 非贪婪模式, 我们使用的是”*?”, 或 “+?” 这种形式, 还有一种是 “{n,m}?”.
区间量词”{n,m}” 也是匹配优先, 虽有匹配次数上限, 但是在到达上限之前, 它依然是尽可能多的匹配, 而”{n,m}?” 则表示在区间范围内, 尽可能少的匹配.
需要注意的是:
- 能达到同样匹配结果的贪婪与非贪婪模式, 通常是贪婪模式的匹配效率较高.
- 所有的非贪婪模式, 都可以通过修改量词修饰的子表达式, 转换为贪婪模式.
- 贪婪模式可以与
固化分组(后面会讲到)结合,提升匹配效率,而非贪婪模式却不可以.
分组
正则的分组主要通过小括号来实现, 括号包裹的子表达式作为一个分组, 括号后可以紧跟限定词表示重复次数. 如下, 小括号内包裹的abc便是一个分组:
/(abc)+/.test("abc123") == true那么分组有什么用呢? 一般来说, 分组是为了方便的表示重复次数, 除此之外, 还有一个作用就是用于捕获, 请往下看.
捕获性分组
捕获性分组, 通常由一对小括号加上子表达式组成. 捕获性分组会创建反向引用, 每个反向引用都由一个编号或名称来标识, js中主要是通过 $+编号 或者 \+编号 表示法进行引用. 如下便是一个捕获性分组的例子.
var color = "#808080";
var output = color.replace(/#(\d+)/,"$1"+"~~");//自然也可以写成 "$1~~"
console.log(RegExp.$1);//808080
console.log(output);//808080~~以上, (\d+) 表示一个捕获性分组, RegExp.$1 指向该分组捕获的内容. $+编号 这种引用通常在正则表达式之外使用. \+编号 这种引用却可以在正则表达式中使用, 可用于匹配不同位置相同部分的子串.
var url = "www.google.google.com";
var re = /([a-z]+)\.\1/;
console.log(url.replace(re,"$1"));//"www.google.com"
以上, 相同部分的”google”字符串只被替换一次.
非捕获性分组
非捕获性分组, 通常由一对括号加上”?:”加上子表达式组成, 非捕获性分组不会创建反向引用, 就好像没有括号一样. 如下:
var color = "#808080";
var output = color.replace(/#(?:\d+)/,"$1"+"~~");
console.log(RegExp.$1);//""
console.log(output);//$1~~
以上, (?:\d+) 表示一个非捕获性分组, 由于分组不捕获任何内容, 所以, RegExp.$1 就指向了空字符串.
同时, 由于$1 的反向引用不存在, 因此最终它被当成了普通字符串进行替换.
实际上, 捕获性分组和无捕获性分组在搜索效率方面也没什么不同, 没有哪一个比另一个更快.
命名分组
语法: (? …)
命名分组也是捕获性分组, 它将匹配的字符串捕获到一个组名称或编号名称中, 在获得匹配结果后, 可通过分组名进行获取. 如下是一个python的命名分组的例子.
import re
data = "#808080"
regExp = r"#(?P< one>\d+)"
replaceString = "\g< one>" + "~~"
print re.sub(regExp,replaceString,data) # 808080~~
python的命名分组表达式与标准格式相比, 在 ? 后多了一大写的 P 字符, 并且python通过“\g<命名>”表示法进行引用. (如果是捕获性分组, python通过”\g<编号>”表示法进行引用)
与python不同的是, javaScript 中并不支持命名分组.
固化分组
固化分组, 又叫原子组.
语法: (?>…)
如上所述, 我们在使用非贪婪模式时, 匹配过程中可能会进行多次的回溯, 回溯越多, 正则表达式的运行效率就越低. 而固化分组就是用来减少回溯次数的.
实际上, 固化分组(?>…)的匹配与正常的匹配并无分别, 它并不会改变匹配结果. 唯一的不同就是: 固化分组匹配结束时, 它匹配到的文本已经固化为一个单元, 只能作为整体而保留或放弃, 括号内的子表达式中未尝试过的备用状态都会被放弃, 所以回溯永远也不能选择其中的状态(因此不能参与回溯). 下面我们来通过一个例子更好地理解固化分组.
假如要处理一批数据, 原格式为 123.456, 因为浮点数显示问题, 部分数据格式会变为123.456000000789这种, 现要求只保留小数点后2~3位, 但是最后一位不能为0, 那么这个正则怎么写呢?
var str = "123.456000000789";
str = str.replace(/(\.\d\d[1-9]?)\d*/,"$1"); //123.456
以上的正则, 对于”123.456” 这种格式的数据, 将白白处理一遍. 为了提高效率, 我们将正则最后的一个”*”改为”+”. 如下:
var str = "123.456";
str = str.replace(/(\.\d\d[1-9]?)\d+/,"$1"); //123.45
此时, “\d\d[1-9]?” 子表达式, 匹配是 “45”, 而不是 “456”, 这是因为正则末尾使用了”+”, 表示末尾至少要匹配一个数字, 因此末尾的子表达式”\d+” 匹配到了 “6”. 显然 “123.45” 不是我们期望的匹配结果, 那我们应该怎么做呢? 能否让 “[1-9]?” 一旦匹配成功, 便不再进行回溯, 这里就要用到我们上面说的固化分组.
“(\.\d\d(?>[1-9]?))\d+” 便是上述正则的固化分组形式. 由于字符串 “123.456” 不满足该固化分组的正则, 所以, 匹配会失败, 符合我们期望.
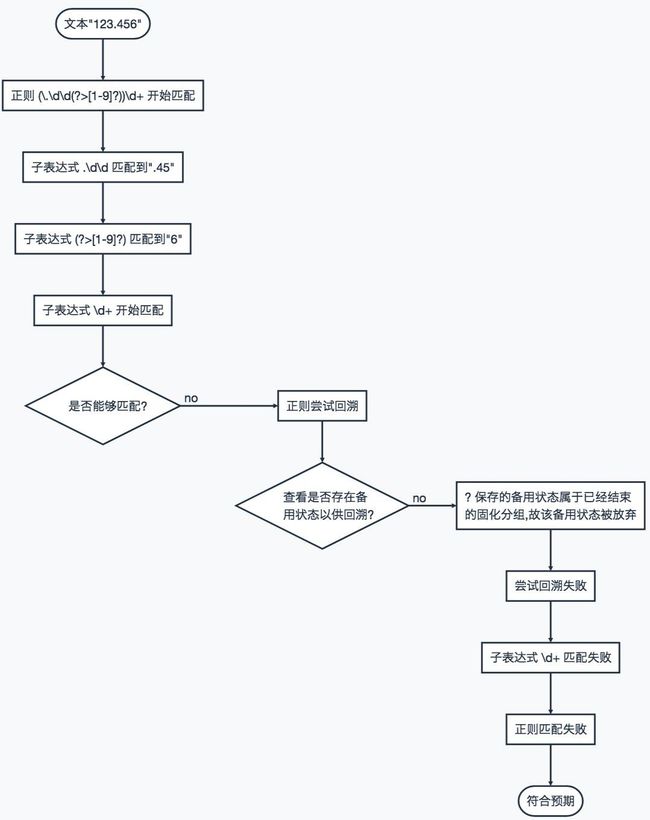
下面我们来分析下固化分组的正则 (\.\d\d(?>[1-9]?))\d+ 为什么匹配不到字符串”123.456”.
很明显, 对于上述固化分组, 只存在两种匹配结果.
情况①: 若 [1-9] 匹配失败, 正则会返回 ? 留下的备用状态. 然后匹配脱离固化分组, 继续前进到[\d+]. 当控制权离开固化分组时, 没有备用状态需要放弃(因固化分组中根本没有创建任何备用状态).
情况②: 若 [1-9] 匹配成功, 匹配脱离固化分组之后, ? 保存的备用状态仍然存在, 但是, 由于它属于已经结束的固化分组, 所以会被抛弃.
对于字符串 “123.456”, 由于 [1-9] 能够匹配成功, 所以它符合情况②. 下面我们来还原情况②的执行现场.
- 匹配所处的状态: 匹配已经走到了 “6” 的位置, 匹配将继续前进;==>
- 子表达式 \d+ 发现无法匹配, 正则引擎便尝试回溯;==>
- 查看是否存在备用状态以供回溯?==>
- “?” 保存的备用状态属于已经结束的固化分组, 所以该备用状态会被放弃;==>
- 此时固化分组匹配到的 “6”, 便不能用于正则引擎的回溯;==>
- 尝试回溯失败;==>
- 正则匹配失败.==>
- 文本 “123.456” 没有被正则表达式匹配上, 符合预期.
相应的流程图如下:
遗憾的是, javaScript, java 和 python中并不支持固化分组的语法, 不过, 它在php和.NET中表现良好. 下面提供了一个php版的固化分组形式的正则表达式, 以供尝试.
$str = "123.456";
echo preg_replace("/(\.\d\d(?>[1-9]?))\d+/","\\1",$str); //固化分组
不仅如此, php还提供了占有量词优先的语法. 如下:
$str = "123.456";
echo preg_replace("/(\.\d\d[1-9]?+)\d+/","\\1",$str); //占有量词优先
虽然java不支持固化分组的语法, 但java也提供了占有量词优先的语法, 同样能够避免正则回溯. 如下:
String str = "123.456";
System.out.println(str.replaceAll("(\\.\\d\\d[1-9]?+)\\d+", "$1"));// 123.456
值得注意的是: java中 replaceAll 方法需要转义反斜杠.
正则表达式高阶技能-零宽断言
如果说正则分组是写轮眼, 那么零宽断言就是万花筒写轮眼终极奥义-须佐能乎(这里借火影忍术打个比方). 合理地使用零宽断言, 能够能分组之不能, 极大地增强正则匹配能力, 它甚至可以帮助你在匹配条件非常模糊的情况下快速地定位文本.
零宽断言, 又叫环视. 环视只进行子表达式的匹配, 匹配到的内容不保存到最终的匹配结果, 由于匹配是零宽度的, 故最终匹配到的只是一个位置.
环视按照方向划分, 有顺序和逆序两种(也叫前瞻和后瞻), 按照是否匹配有肯定和否定两种, 组合之, 便有4种环视. 4种环视并不复杂, 如下便是它们的描述.
| 字符 | 描述 | 示例 |
|---|---|---|
| (?:pattern) | 非捕获性分组, 匹配pattern的位置, 但不捕获匹配结果.也就是说不创建反向引用, 就好像没有括号一样. | ‘abcd(?:e)匹配’abcde |
| (?=pattern) | 顺序肯定环视, 匹配后面是pattern 的位置, 不捕获匹配结果. | ‘Windows (?=2000)’匹配 “Windows2000” 中的 “Windows”; 不匹配 “Windows3.1” 中的 “Windows” |
| (?!pattern) | 顺序否定环视, 匹配后面不是 pattern 的位置, 不捕获匹配结果. | ‘Windows (?!2000)’匹配 “Windows3.1” 中的 “Windows”; 不匹配 “Windows2000” 中的 “Windows” |
| (?<=pattern) | 逆序肯定环视, 匹配前面是 pattern 的位置, 不捕获匹配结果. | ‘(?<=Office)2000’匹配 “ Office2000” 中的 “2000”; 不匹配 “Windows2000” 中的 “2000” |
| (?pattern) | 逆序否定环视, 匹配前面不是 pattern 的位置, 不捕获匹配结果. | ‘(? |
非捕获性分组由于结构与环视相似, 故列在表中, 以做对比. 以上4种环视中, 目前 javaScript 中只支持前两种, 也就是只支持 顺序肯定环视 和 顺序否定环视. 下面我们通过实例来帮助理解下:
var str = "123abc789",s;
//没有使用环视,abc直接被替换
s = str.replace(/abc/,456);
console.log(s); //123456789
//使用了顺序肯定环视,捕获到了a前面的位置,所以abc没有被替换,只是将3替换成了3456
s = str.replace(/3(?=abc)/,3456);
console.log(s); //123456abc789
//使用了顺序否定环视,由于3后面跟着abc,不满意条件,故捕获失败,所以原字符串没有被替换
s = str.replace(/3(?!abc)/,3456);
console.log(s); //123abc789下面通过python来演示下 逆序肯定环视 和 逆序否定环视 的用法.
import re
data = "123abc789"
# 使用了逆序肯定环视,替换左边为123的连续的小写英文字母,匹配成功,故abc被替换为456
regExp = r"(?< =123)[a-z]+"
replaceString = "456"
print re.sub(regExp,replaceString,data) # 123456789
# 使用了逆序否定环视,由于英文字母左侧不能为123,故子表达式[a-z]+捕获到bc,最终bc被替换为456
regExp = r"(?< !123)[a-z]+"
replaceString = "456"
print re.sub(regExp,replaceString,data) # 123a456789需要注意的是: python 和 perl 语言中的 逆序环视 的子表达式只能使用定长的文本. 比如将上述 “(?<=123)” (逆序肯定环视)子表达式写成 “(?<=[0-9]+)”, python解释器将会报错: “error: look-behind requires fixed-width pattern”.
场景回顾
获取html片段
假如现在, js 通过 ajax 获取到一段 html 代码如下:
var responseText = " ";
";现我们需要替换img标签的src 属性中的 “dev”字符串 为 “test” 字符串.
① 由于上述 responseText 字符串中包含至少两个子字符串 “dev”, 显然不能直接 replace 字符串 “dev”为 “test”.
② 同时由于 js 中不支持逆序环视, 我们也不能在正则中判断前缀为 “src=’”, 然后再替换”dev”.
③ 我们注意到 img 标签的 src 属性以 “.png” 结尾, 基于此, 就可以使用顺序肯定环视. 如下:
var reg = /dev(?=[^']*png)/; //为了防止匹配到第一个dev, 通配符前面需要排除单引号或者是尖括号
var str = responseText.replace(reg,"test");
console.log(str);//< div data='dev.xxx'>< /div>< img src='test.xxx.png' />
当然, 以上不止顺序肯定环视一种解法, 捕获性分组同样可以做到. 那么环视高级在哪里呢? 环视高级的地方就在于它通过一次捕获就可以定位到一个位置, 对于复杂的文本替换场景, 常有奇效, 而分组则需要更多的操作. 请往下看.
千位分割符
千位分隔符, 顾名思义, 就是数字中的逗号. 参考西方的习惯, 数字之中加入一个符号, 避免因数字太长难以直观的看出它的值. 故而数字之中, 每隔三位添加一个逗号, 即千位分隔符.
那么怎么将一串数字转化为千位分隔符形式呢?
var str = "1234567890";
(+str).toLocaleString();//"1,234,567,890"
如上, toLocaleString() 返回当前对象的”本地化”字符串形式.
- 如果该对象是Number类型, 那么将返回该数值的按照特定符号分割的字符串形式.
- 如果该对象是Array类型, 那么先将数组中的每项转化为字符串, 然后将这些字符串以指定分隔符连接起来并返回.
toLocaleString 方法特殊, 有本地化特性, 对于天朝, 默认的分隔符是英文逗号. 因此使用它恰好可以将数值转化为千位分隔符形式的字符串. 如果考虑到国际化, 以上方法就有可能会失效了.
我们尝试使用环视来处理下.
function thousand(str){
return str.replace(/(?!^)(?=([0-9]{3})+$)/g,',');
}
console.log(thousand(str));//"1,234,567,890"
console.log(thousand("123456"));//"123,456"
console.log(thousand("1234567879876543210"));//"1,234,567,879,876,543,210"
上述使用到的正则分为两块. (?!^) 和 (?=([0-9]{3})+$). 我们先来看后面的部分, 然后逐步分析之.
- “[0-9]{3}” 表示连续3位数字.
- “([0-9]{3})+” 表示连续3位数字至少出现一次或更多次.
- “([0-9]{3})+$” 表示连续3的正整数倍的数字, 直到字符串末尾.
- 那么
(?=([0-9]{3})+$)就表示匹配一个零宽度的位置, 并且从这个位置到字符串末尾, 中间拥有3的正整数倍的数字. - 正则表达式使用全局匹配g, 表示匹配到一个位置后, 它会继续匹配, 直至匹配不到.
- 将这个位置替换为逗号, 实际上就是每3位数字添加一个逗号.
- 当然对于字符串”123456”这种刚好拥有3的正整数倍的数字的, 当然不能在1前面添加逗号. 那么使用
(?!^)就指定了这个替换的位置不能为起始位置.
千位分隔符实例, 展示了环视的强大, 一步到位.
正则表达式在JS中的应用
ES6对正则的扩展
ES6对正则扩展了又两种修饰符(其他语言可能不支持):
- y (粘连sticky修饰符), 与g类似, 也是全局匹配, 并且下一次匹配都是从上一次匹配成功的下一个位置开始, 不同之处在于, g修饰符只要剩余位置中存在匹配即可, 而y修饰符确保匹配必须从剩余的第一个位置开始.
var s = "abc_ab_a";
var r1 = /[a-z]+/g;
var r2 = /[a-z]+/y;
console.log(r1.exec(s),r1.lastIndex); // ["abc", index: 0, input: "abc_ab_a"] 3
console.log(r2.exec(s),r2.lastIndex); // ["abc", index: 0, input: "abc_ab_a"] 3
console.log(r1.exec(s),r1.lastIndex); // ["ab", index: 4, input: "abc_ab_a"] 6
console.log(r2.exec(s),r2.lastIndex); // null 0
如上, 由于第二次匹配的开始位置是下标3, 对应的字符串是 “_”, 而使用y修饰符的正则对象r2, 需要从剩余的第一个位置开始, 所以匹配失败, 返回null.
正则对象的 sticky 属性, 表示是否设置了y修饰符. 这点将会在后面讲到.
- u 修饰符, 提供了对正则表达式添加4字节码点的支持. 比如 “