Grid LSTM相关
Grid LSTM的参考资料:
1. 下面这篇参考很好
http://blog.sina.com.cn/s/blog_5309cefc0102wbcv.html
2. 最近在看GitHub上的这个例子
https://github.com/phvu/grid-lstm-tensorflow
3. rnn_cell源码
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/keras/layers/legacy_rnn/rnn_cell_impl.py
4. grid_rnn在TensorFlow的库
https://tensorflow.google.cn/versions/r1.15/api_docs/python/tf/contrib/grid_rnn
5. grid_rnn_cell源码
https://github.com/tensorflow/tensorflow/blob/4386a6640c9fb65503750c37714971031f3dc1fd/tensorflow/contrib/grid_rnn/python/ops/grid_rnn_cell.py#L221
6. Multi-Dimensional Recurrent Neural Networks(MDRNN)论文
https://arxiv.org/abs/0705.2011
7. Grid Long Short-Term Memory论文
https://arxiv.org/abs/1507.01526
下面是论文的总结和自己的一些理解。
1. LSTM
计算公式如下:

每个lstm cell都包含一个memory向量和hidden state向量
lstm的一大特点是通过线性变换(加法和点对点的乘积)进行传播,有效解决梯度消失问题。
2. multi-dimensional RNN
论文对多维RNN前向传播过程的描述为:During the forward pass, at each point in the data sequence, the hidden layer of the network receives both an external input and its own activations from one step back along all dimensions. 大意是每次计算输入序列中一点时,网络的隐藏层都有两个输入:一个是数据序列本身的输入,另一个是来自另外(n-1)个维度的最新输出(在定义序列时,这些点必须在要计算的点的前面)
首先,需要定义n维数据的顺序(sequence)。这个顺序需要满足:在到达n维空间一点时,需要已经经过该点在(n-1)个维度上前一步的所有点。比如下图,2维RNN的序列定义为
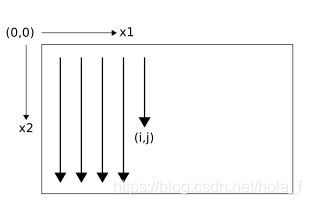
则,前向传播过程中点(i,j)在两个维度上面前一步的点分别为(i-1,j)和(i,j-1),即网络在点(i,j)的输入为该点本身对应的外部输入加上网络在点(i-1,j)和(i,j-1)的中间输出。
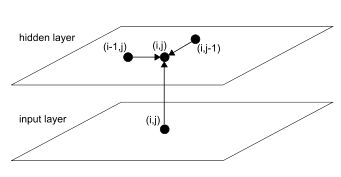
需要注意的是,输入序列中的点通常为一个多值向量。
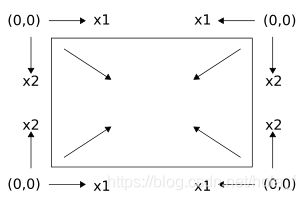
MDRNNs还有一个很有意思的点——Multi-directional MDRNNs,这个结构能够学习到各个方向上的上下文信息。Multi-directional MDRNNs包含 个隐层结构,每个结构学习的序列的定义相同,但是使用不同的坐标系(原点不同)。例如,2维RNN有如下图的四个不同坐标系,对应四个隐层结构。
个隐层结构,每个结构学习的序列的定义相同,但是使用不同的坐标系(原点不同)。例如,2维RNN有如下图的四个不同坐标系,对应四个隐层结构。
3. multi-dimensional LSTM
n维LSTM学习n个forget gate。原文如下:
![]()
每个cell的输入包含原始输入、n个隐层向量和n个记忆向量(来自one step back cell)。四个门的计算公式同LSTM,其中的H为:
![]()
这里的门向量的维度和cell的h和m向量维度相同。记忆向量m的计算为:
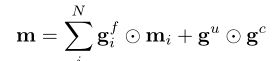
此处的 为第i个维度的记忆向量。总而言之,多维LSTM在计算一个点的m和h向量时包含n个维度的输入,但是每个点只计算一个m和h向量,该点作为下一状态在n个维度上继续传播。这样的做法有一个不足,就是观察m的计算时可以发现,累加操作的存在使得向量m中的值也会随着n的增大和向量维度的增加而增大。
为第i个维度的记忆向量。总而言之,多维LSTM在计算一个点的m和h向量时包含n个维度的输入,但是每个点只计算一个m和h向量,该点作为下一状态在n个维度上继续传播。这样的做法有一个不足,就是观察m的计算时可以发现,累加操作的存在使得向量m中的值也会随着n的增大和向量维度的增加而增大。
4. grid LSTM
是一种用途更广的结构,可以用于任意任务。相比较Grid LSTM,multidimensional LSTM的结构更加扁平,只是输入来自n个维度,值在向量上没有区分,而grid LSTM则把整个n维拉开,形成一个网格,每个网格的输入来自上一步相应维度的输出。2维grid lstm的示意图如下。
单个block
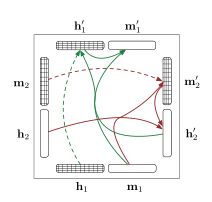
网络结构
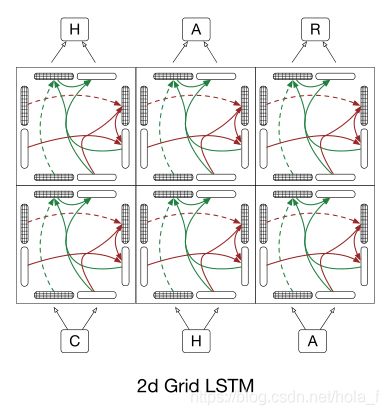
stacked lstm
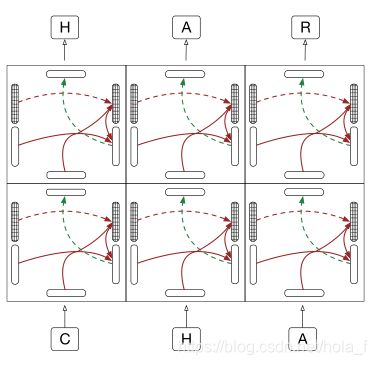
和stacked lstm对比可以看出来,2d grid lstm的每个block都在深度维度上增加了lstm的计算单元。不过,一个小小的疑问就是,我觉得上面的图是把第一维作为优先维度的priority grid lstm。
Grid LSTM的输入为n个隐状态向量 ,...,
,...,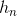 和n个记忆向量
和n个记忆向量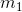 ,...,
,...,![]() ,每个lstm的block同样输出n个隐状态向量和n个记忆向量。其计算如下:
,每个lstm的block同样输出n个隐状态向量和n个记忆向量。其计算如下:
H向量为:
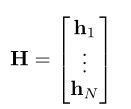
一个block计算n个transforms lstm,每个维度都输出一个隐状态向量和记忆向量,即
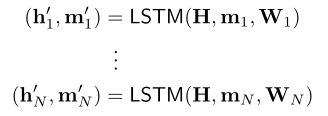
注意:在这个结构中,一个block不接收单独的数据表示(外部输入),这些输入是在grid的某个维度,通过映射为隐状态向量和记忆向量输入网络的。这点可以在grid rnn的源码中看出了,源码中会指定输入数据所在维度。
grid lstm还可以包含优先维度和非lstm维度。
优先维度就是指可以指定一个维度,最后计算他的h向量和m向量,该维度输入的h向量为其他维度已经transform的h向量,即
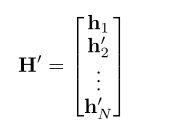
这样计算的意义,原文的说法为:

对输出所在维度的计算可能有好处。
非lstm维度就是该维度不用lstm的方式计算,而是简单的神经层,以第一个维度的计算为例,即
![]()
最后,在看代码时候的一些收获:
1. [a]*n和[a for _ in range(n)]的区别
这两个都是在一个列表里复制n次a,但是如果对象a的类型是可变的,则第一种写法里,列表里的每个a都是第一个a的引用。比如a如果是一个含有m个元素的列表对象,则这两个表达式的结果都是一个n行m列的数组。但是第一种写法得到的数组,每一列的所有元素的地址相同,所以改变某一值时,该列所有值都会进行相同的改变。
解答在这里:https://www.v2ex.com/amp/t/357903
2. functools.partial()函数
这个函数对函数进行处理,可以固定输入函数中的部分参数,达到减少参数的目的。
具体例子看这里:https://blog.csdn.net/cassiepython/article/details/76653897
3. tf.stop_gradient()函数
这个函数可以截断梯度传播,使用该函数的节点不会进行后向的梯度传播