Java 7 Fork/Join 并行计算框架概览
应用程序并行计算遇到的问题
当硬件处理能力不能按摩尔定律垂直发展的时候,选择了水平发展。多核处理器已广泛应用,未来处理器的核心数将进一步发布,甚至达到上百上千的数量。而现在很多的应用程序在运行在多核心的处理器上并不能得到很好的性能提升,因为应用程序的并发处理能力不强,不能够合理有效地的利用计算资源。线性的计算只能利用n分之一的计算支援。
要提高应用程序在多核处理器上的执行效率,只能想办法提高应用程序的本身的并行能力。常规的做法就是使用多线程,让更多的任务同时处理,或者让一部分操作异步执行,这种简单的多线程处理方式在处理器核心数比较少的情况下能够有效地利用处理资源,因为在处理器核心比较少的情况下,让不多的几个任务并行执行即可。但是当处理器核心数发展很大的数目,上百上千的时候,这种按任务的并发处理方法也不能充分利用处理资源,因为一般的应用程序没有那么多的并发处理任务(服务器程序是个例外)。所以,只能考虑把一个任务拆分为多个单元,每个单元分别得执行最后合并每个单元的结果。一个任务的并行拆分,一种方法就是寄希望于硬件平台或者操作系统,但是目前这个领域还没有很好的结果。另一种方案就是还是只有依靠应用程序本身对任务经行拆封执行。
Fork/Join框架
依靠应用程序本身并行拆封任务,如果使用简单的多线程程序的方法,复杂度必然很大。这就需要一个更好的范式或者工具来代程序员处理这类问题。Java 7也意识到了这个问题,才标准库中集成了由Doug Lea开发的Fork/Join并行计算框架。通过使用 Fork/Join 模式,软件开发人员能够方便地利用多核平台的计算能力。尽管还没有做到对软件开发人员完全透明,Fork/Join 模式已经极大地简化了编写并发程序的琐碎工作。对于符合 Fork/Join 模式的应用,软件开发人员不再需要处理各种并行相关事务,例如同步、通信等,以难以调试而闻名的死锁和 data race 等错误也就不会出现,提升了思考问题的层次。你可以把 Fork/Join 模式看作并行版本的 Divide and Conquer 策略,仅仅关注如何划分任务和组合中间结果,将剩下的事情丢给 Fork/Join 框架。但是Fork/Join并行计算框架,并不是银弹,并不能解决所有应用程序在超多核心处理器上的并发问题。
如果一个应用能被分解成多个子任务,并且组合多个子任务的结果就能够获得最终的答案,那么这个应用就适合用 Fork/Join 模式来解决。其原理如下图。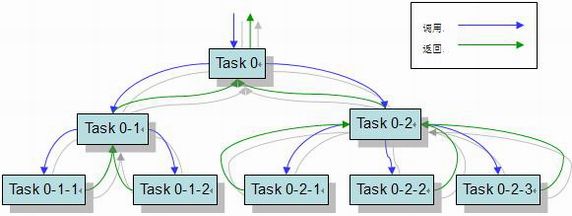
应用程序开发者需要做的就是拆分任务并组合每个子任务的中间结果,而不用再考虑线程和锁的问题。
一个简单的例子
我们首先看一个简单的Fork/Join的任务定义。
public class Calculator extends RecursiveTask {
private static final int THRESHOLD = 100;
private int start;
private int end;
public Calculator(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
if((start - end) < THRESHOLD){
for(int i = start; i< end;i++){
sum += i;
}
}else{
int middle = (start + end) /2;
Calculator left = new Calculator(start, middle);
Calculator right = new Calculator(middle + 1, end);
left.fork();
right.fork();
sum = left.join() + right.join();
}
return sum;
}
} 这段代码中,定义了一个累加的任务,在compute方法中,判断当前的计算范围是否小于一个值,如果是则计算,如果没有,就把任务拆分为连个子任务,并合并连个子任务的中间结果。程序递归的完成了任务拆分和计算。
任务定义之后就是执行任务,Fork/Join提供一个和Executor框架 的扩展线程池来执行任务。
@Test
public void run() throws Exception{
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future result = forkJoinPool.submit(new Calculator(0, 10000));
assertEquals(new Integer(49995000), result.get());
} Fork/Join框架的主要类

RecursiveAction供不需要返回值的任务继续。
RecursiveTask通过泛型参数设置计算的返回值类型。
ForkJoinPool提供了一系列的submit方法,计算任务。ForkJoinPool默认的线程数通过Runtime.availableProcessors()获得,因为在计算密集型的任务中,获得多于处理性核心数的线程并不能获得更多性能提升。
public
doSubmit(task);
return task;
}
sumit方法返回了task本身,ForkJoinTask实现了Future接口,所以可以通过它等待获得结果。
另一例子
这个例子并行排序数组,不需要返回结果,所以继承了RecursiveAction。
public class SortTask extends RecursiveAction {
final long[] array;
final int start;
final int end;
private int THRESHOLD = 100; //For demo only
public SortTask(long[] array) {
this.array = array;
this.start = 0;
this.end = array.length - 1;
}
public SortTask(long[] array, int start, int end) {
this.array = array;
this.start = start;
this.end = end;
}
protected void compute() {
if (end - start < THRESHOLD)
sequentiallySort(array, start, end);
else {
int pivot = partition(array, start, end);
new SortTask(array, start, pivot - 1).fork();
new SortTask(array, pivot + 1, end).fork();
}
}
private int partition(long[] array, int start, int end) {
long x = array[end];
int i = start - 1;
for (int j = start; j < end; j++) {
if (array[j] <= x) {
i++;
swap(array, i, j);
}
}
swap(array, i + 1, end);
return i + 1;
}
private void swap(long[] array, int i, int j) {
if (i != j) {
long temp = array[i];
array[i] = array[j];
array[j] = temp;
}
}
private void sequentiallySort(long[] array, int lo, int hi) {
Arrays.sort(array, lo, hi + 1);
}
} @Test
public void run() throws InterruptedException {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Random rnd = new Random();
long[] array = new long[SIZE];
for (int i = 0; i < SIZE; i++) {
array[i] = rnd.nextInt();
}
forkJoinPool.submit(new SortTask(array));
forkJoinPool.shutdown();
forkJoinPool.awaitTermination(1000, TimeUnit.SECONDS);
for (int i = 1; i < SIZE; i++) {
assertTrue(array[i - 1] < array[i]);
}
}动手尝试
Fork/Join框架的代码已经整合到了最新的JDK7的Binary Snapshot Releases中,可以通过这个地址 下载。
本文中的代码见附件。