Linux 使用正则表达式的常用命令
【grep 命令】
1.基本操作
1)作用:grep命令用于打印输出文本中匹配的模式串,它使用正则表达式作为模式匹配的条件。
2)命令格式:grep [选项] 要匹配的字符串 文件名
3)常见选项:
| -b | 将二进制文件作为文本来进行匹配 |
| -c | 统计以模式匹配的数目 |
| -i | 忽略大小写 |
| -n | 显示匹配文本所在行的行号 |
| -v | 反选,输出不匹配行的内容 |
| -r | 递归匹配查找 |
| -A n | 除了列出匹配行之外,还列出后面的 n 行 |
| -B n | 除了列出匹配行之外,还列出前面的 n 行 |
| --color=auto | 将输出中的匹配项设置为自动颜色显示 |
4)实例:

2.使用正则表达式
1)正则表达式引擎
grep 支持三种正则表达式引擎,分别用三个参数指定:
| -G | POSIX 基本正则表达式,BRE |
| -E | POSIX 扩展正则表达式,ERE |
| -P | Perl 正则表达式,PCRE |
2)使用基本正则表达式,BRE
grep 默认使用基本正则表达式,或者在使用的时候加上 -G 参数
① 位置
例:
查找 /etc/group 文件中以 "root" 为开头的行

② 数量
例:
匹配以 'z' 开头以 'o' 结尾的所有字符串

匹配以 'z' 开头以 'o' 结尾,中间包含一个任意字符的字符串
![]()
匹配以'z'开头,以任意多个'o'结尾的字符串

注:\n 是换行符
③ 选择
特殊符号及说明
| [:alnum:] |
代表英文大小写字母及数字,即:0-9, A-Z, a-z |
| [:alpha:] | 代表英文大小写字母,即:A-Z, a-z |
| [:digit:] | 代表数字,即:0-9 |
| [:lower:] | 代表小写字母,即:a-z |
| [:upper:] | 代表大写字母,即:A-Z |
| [:punct:] | 代表标点符号,即:" ' ? ! ; : # $ 等 |
| [:cntrl:] | 代表键盘上面的控制按键,包括:CR, LF, Tab, Del 等 |
| [:print:] | 代表任何可以被列印出来的字符 |
| [:blank:] | 代表空白键与 [Tab] 按键 |
| [:graph:] | 除了空白字节(空白键与 [Tab] 键)外的其他所有按键 |
| [:space:] | 代表任何会产生空白的字符,包括:空白键, [Tab], CR 等 |
| [:xdigit:] | 代表 16 进位的数字类型,包括: 0-9, A-F, a-f 的数字与字节 |
例:
匹配所有的小写字母
![]()
匹配所有的数字
![]()
匹配所有的数字
![]()
匹配所有的小写字母
![]()
匹配所有的大写字母
![]()
匹配所有的字母和数字

匹配所有的字母

3)使用扩展正则表达式,ERE
通过 grep 使用扩展正则表达式需要加上 -E 参数,或使用 egrep
① 数量
例:
只匹配 "zo"

匹配以 "zo" 开头的所有单词

② 选择
例:
匹配 "www.baidu.com" 和 "www.google.com"

匹配不包含 "baidu" 的内容

注:. 符号有特殊含义,所以需要转义
【sed 流编辑器】
sed 工具是用于过滤和转换文本的流编辑器,与 vim、emacs、geditdeng等编辑器不同的是,sed 是一个非交互式的编辑器。
本文仅介绍 sed 的基本操作,更多内容参考以下链接:sed 简明教程、sed 单行脚本快速参考、sed完全手册
1.sed 命令基本格式:sed [选项] [执行命令] [输入文件]
2.常用参数:
| -n | 安静模式,只打印受影响的行,默认打印输入数据的全部内容 |
| -e | 用于脚本添加多个执行命令一次执行,在命令行中执行多个命令不需要加 |
| -f filename | 指定执行 filename 文件中的命令 |
| -r | 使用扩展正则表达式,默认为标准正则表达式 |
| -i | 将直接修改输入文件内容,而不是打印到标准输出设备 |
3.执行命令格式:
1)[n1][,n2] command [作用范围]
2)[n1][~step] command [作用范围]
n1、n2 表示输入内容的行号,它们之间为 ,逗号表示从 n1 到 n2 行,~波浪号表示从 n1 开始以 step 为步进的所有行,command 为执行动作。
4.常见执行命令
| s | 行内替换 |
| c | 整行替换 |
| a |
插入到指定行的后面 |
| i | 插入到指定行的前面 |
| p | 打印指定行,通常与 -n 参数配合使用 |
| d | 删除指定行 |
5.实例
1)找一个操作用的文件
![]()
2)打印 2-5 行

3)打印奇数行
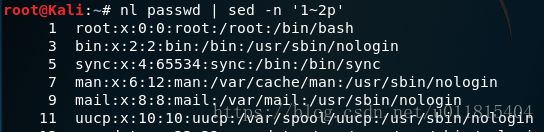
4)将输入文本中 "root" 全局替换为 "test",并只打印替换的那一行
![]()
5)行间替换
找出 root 的那一行并计算行号
![]()
将 root 替换为 www.root.com
![]()
【awk 文本处理语言】
1.概述
AWK 是一种优良的文本处理工具,是 Linux 中现有的功能最强大的数据处理引擎之一,其使用的 AWK 程序设计语言,又叫样式扫描和处理语言。它允许创建简短的程序,通过程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表等等。简单地说,AWK 是一种用于处理文本的编程语言工具。
awk 所有的操作都是基于 pattern(模式)—action(动作) 对 来完成的,其形式为:pattern {action}
如同很多编程语言一样,它将所有的动作操作用一对 {} 花括号包围起来,其中 pattern 通常是表示用于匹配输入的文本的“关系式”或“正则表达式”,action 则是表示匹配后将执行的动作。
在一个完整 awk 操作中,模式与动作可以只有其中一个。如果没有 pattern,则默认匹配输入的全部文本;如果没有 action,则默认为打印匹配内容到屏幕。
awk 处理文本的方式,是将文本分割成一些“字段”,然后再对这些字段进行处理,默认情况下,awk 以空格作为一个字段的分割符,也可以任意指定分隔符。
本文仅介绍 awk 的基本操作,更多内容参考以下链接:awk 程序设计语言、awk 简明教程、awk 用户指南
2.awk 命令基本格式:awk [-F fs] [-v var=value] [-f prog-file | 'program text'] [file...]
-F 参数用于预先指定字段分隔符,-v 参数用于预先为 awk 程序指定变量,-f 参数用于指定 awk 命令要执行的程序文件,或者在不加 -f 参数的情况下直接将程序语句放在这里,最后为 awk 需要处理的文本输入,且可以同时输入多个文本文件。
3.awk 常用内置变量
| FILENAME |
当前输入文件名,若有多个文件,则只表示第一个。如果输入是来自标准输入,则为空字符串 |
| $0 | 当前记录的内容 |
| $N | N表示字段号,最大值为NF变量的值 |
| FS | 字段分隔符,由正则表达式表示,默认为" "空格 |
| RS | 输入记录分隔符,默认为"\n",即一行为一个记录 |
| NF | 当前记录字段数 |
| NR | 已经读入的记录数 |
| FNR | 当前输入文件的记录数 |
| OFS | 输出字段分隔符,默认为" "空格 |
| ORS | 输出记录分隔符,默认为"\n" |
4.实例
存在一文档

1)使用 awk 将内容打印到终端

2)将 test 的第一行的每个字段单独显示为一行

注:在学习和使用 awk 的时候,应尽可能将其作为一门程序语言来理解,这样将会使你学习更容易,所以初学阶段在练习 awk 时应该尽量按照分多行按照一般程序语言的换行和缩进来输入,而不是全部写到一行。