Task 2:数据的探索性分析(EDA)
赛题:零基础入门数据挖掘 - 二手车交易价格预测
EDA(Exploratory Data Analysis):
对已有的数据(特别是原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的数据分析方法。
目标:
1.了解数据集,初步分析;
2.了解比数据集中各变量间的关系;
3.数据处理/特征工程;
4.对数据集进行图文总结, 分析特征和label的关联性。
代码示例:
import warnings
warnings.filterwarnings('ignore')
# 避免出现:代码正常运行,但提示警告
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
## 通过Pandas载入数据
Train_data = pd.read_csv('datalab/231784/used_car_train_20200313.csv', sep=' ')
Test_data = pd.read_csv('datalab/231784/used_car_testA_20200313.csv', sep=' ')
# 源文件指定为' '分隔符,以防报错
Train_data.head(3).append(Train_data.tail(3))
# 查看训练集前3行和后3行的数据,结果略
Train_data.shape # 输出:(150000, 31)
Test_data.shape # 输出:(50000, 30)
# 训练集比测试集多1列:'price'
Train_data.describe()
# 通过describe查看相关统计量,掌握数据的大概范围以及对异常值的判断
Train_data.info()
# 熟悉数据类型,其中'notRepairedDamage'是object类型,其余都是数值
Train_data.isnull().sum()
# 查看每个字段的缺失情况(汇总)
# 可视化查看训练集缺失值情况
missing = Train_data.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
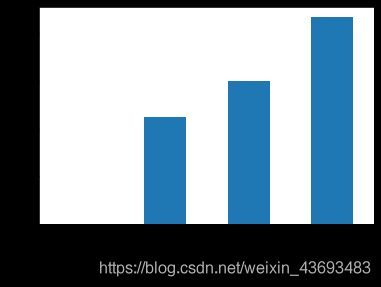
关于缺失值:
1.缺失值个数如果很小一般选择填充;
2.如果使用lgb等树模型可以直接空缺,让树自己去优化;
3.如果nan存在的过多,可以删掉。
Train_data['notRepairedDamage'].value_counts()
# 对'notRepairedDamage'的值类型进行计数
# 输出:0.0 111361
# - 24324
# 1.0 14315
Train_data['notRepairedDamage'].replace('-', np.nan, inplace=True)
# 将‘ - ’替换成nan
其中我们发现,"seller"和"offerType"特征严重倾斜,一般不会对预测有帮助,故先删掉:
Train_data["seller"].value_counts()
Train_data["offerType"].value_counts()
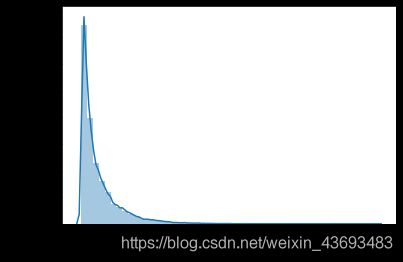
查看预测值‘price’的分布:
# 查看偏度和峰度
sns.distplot(Train_data['price']);
print("Skewness: %f" % Train_data['price'].skew())
print("Kurtosis: %f" % Train_data['price'].kurt())
# 输出:Skewness: 3.346487
# Kurtosis: 18.995183
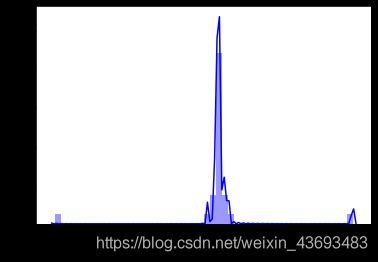
绘制训练集各变量偏度、峰度的概率分布:
sns.distplot(Train_data.skew(),color='blue',axlabel ='Skewness')
sns.distplot(Train_data.kurt(),color='orange',axlabel ='Kurtness')

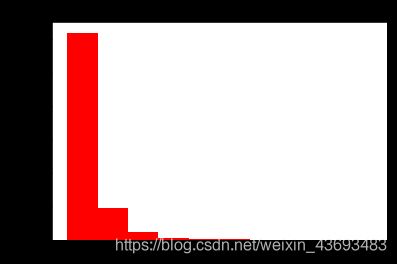
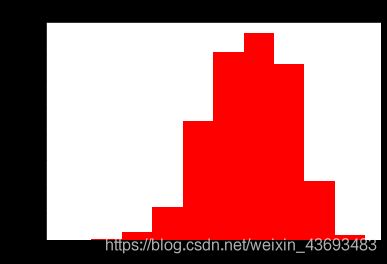
# 查看预测值price的具体频数
plt.hist(Train_data['price'], orientation = 'vertical',histtype = 'bar', color ='red')
plt.title( 'price')
plt.show()
对数变换之后的分布较均匀:
plt.hist(np.log(Train_data['price']), orientation = 'vertical',histtype = 'bar', color ='red')
plt.title( 'log-price')
plt.show()
特征:
1.类别特征
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
2.数字特征
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ]
查看训练集的类别特征分布:
for cat_fea in categorical_features:
print(cat_fea + "的特征分布如下:")
print("{}特征有个{}不同的值".format(cat_fea, Train_data[cat_fea].nunique()))
print(Train_data[cat_fea].value_counts())
相关性可视化:
price_numeric = Train_data[numeric_features]
correlation = price_numeric.corr()
f , ax = plt.subplots(figsize = (7, 7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)

各数字特征分布的可视化:
f = pd.melt(Train_data, value_vars=numeric_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
# 略
各数字特征关系的可视化:
sns.set()
columns = ['price', 'v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14']
sns.pairplot(Train_data[columns],size = 2 ,kind ='scatter',diag_kind='kde')
plt.show()
# 略
生成一份数据预览报告:
import pandas_profiling
pfr = pandas_profiling.ProfileReport(Train_data)
pfr.to_file("./example.html")