从链表到跳表——跳表是什么?
文章目录
- 从数组到链表的改进
-
- 1. 数组的局限性
- 2. 链表的改进
- 跳表的提出
-
- 1. 跳表的结构
- 2. 使用跳表查找元素
- 3. 跳表的复杂度分析
-
- 3.1 时间复杂度分析
- 3.2 空间复杂度分析
- 4. 现实中的跳表
- 5. 跳表的应用
- 参考资料
从数组到链表的改进
1. 数组的局限性
众所周知,数组是内存上连续的数据结构,因此其各操作的时间复杂度为:
- 查找:O(1)
- 插入:O(n)
- 删除:O(n)
可以看到其插入和删除因为需要移动大量元素,导致了其线性的时间复杂度O(n)。
Java中的ArrayList就是在数组的基础上进行的封装
2. 链表的改进
为了降低对集合元素进行插入删除操作时的时间复杂度,前人提出了链表的概念。
常见的链表可以分为以下几种类型:
- 单向链表(每个节点包含当前值和指向下一个节点的链接)
- 双向链表(每个节点包含当前值、指向前一个节点的链接和指向后一个节点的链接)
- 循环链表(尾节点的下一个链接指向头节点)
Java中的LinkedList是基于双向链表实现的
与数组对应,链表的相关操作的时间复杂度为:
- 查找:O(n)
- 插入:O(1)
- 删除:O(1)
与数组相关操作的时间复杂度进行对比之后可以看到,链表将数组为O(n)复杂度的插入和删除操作降为了O(1)常数级,但是查找操作的时间复杂度却提升到了O(n)。
跳表的提出
为了解决链表查找操作为O(n)的时间复杂度的问题,William Pugh 在论文《Skip lists: a probabilistic alternative to balanced trees》中提出了跳跃表(简称跳表)的数据结构。
其实基本思路也很好理解,链表的问题是查找一个元素时必须要从头节点遍历到链表尾,每次只根据节点的指向下一个节点的链接跳跃一步,那么可不可以用某种方式使得链表在遍历查找过程中每次不只是向前走一步而是跳跃多步呢?这就引出了跳表的定义。
那么跳表是如何提高链表线性查找的效率呢?那就是把一维线性结构转变为多维结构。
1. 跳表的结构
(1)添加一级索引

在原始链表上增加一个索引层,该索引层上每个节点指向原始链表的节点,但并不是一一对应而是每隔两个节点用一个索引节点指向。
添加索引后,查找某元素时将首先从第一级索引上进行遍历查找,这样每次向前遍历时都是向前走多个节点(上图为两个)
(2)添加二级索引
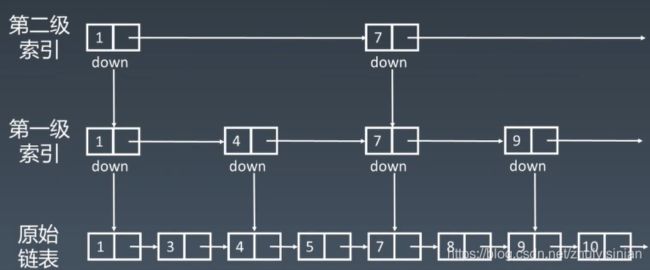
因为一级索引虽然加快了对原始链表的查找搜索速度,但只是加快了一倍的遍历查找速度而已(从每次向前走一步变为了两步)。
可以在第一级索引之上,按照建立索引的方式,继续新建一个索引层,使得遍历查找速度再增加一倍(变为每一步跳跃4个节点)。
以此类推,最终可以增加多层索引。
这里需要注意的一点是:跳表最底层的原始链表必须是有序链表
2. 使用跳表查找元素

如上图所示,跳表在查找第62个节点时,首先从最高层索引依次向底层索引递进,最终找到原始链表中的对应元素。
如果使用链表的按节点依次遍历的方式,则需要遍历62个元素;而使用上述跳表则只需要遍历11个节点,查找速度大大提升。
3. 跳表的复杂度分析
3.1 时间复杂度分析
跳表的第一级索引节点数是 n 2 \frac{n}{2} 2n,第二级为 n 4 \frac{n}{4} 4n,第三级为 n 8 \frac{n}{8} 8n,以此类推可以得到第k级索引节点个数为 n 2 k \frac{n}{2^k} 2kn
假设索引有h级,且最高 级索引只有2个节点,那么可以得到 n 2 h = 2 \frac{n}{2^h}=2 2hn=2,从而求得 h = l o g 2 n − 1 h=log_2n-1 h=log2n−1,再将原始链表层算上后,可以得到整个跳表的高度为 l o g 2 n log_2n log2n

由上图可以看出,遍历过程中,每层索引遍历的节点个数最多为3个,所以在跳表中查找元素的时间复杂度可视为为 3 ∗ l o g 2 n 3*log_2n 3∗log2n,即 O ( l o g 2 n ) O(log_2n) O(log2n)
这里为什么每层索引遍历的节点数最多为3个呢?
当遍历到如上图所示第k级索引时,发现要查找的元素x大于y小于z,则通过y的down指针下降到第k-1级索引上。在第k-1级索引上,y和z之间最多只有3个节点(包含y和z),因此最多只需要遍历3个节点即可。
由于跳表底层的原始链表是有序链表,因此对其进行插入删除操作和对普通链表不同。它首先需要查找到需要插入或者删除的位置,这个查找过程与查找元素的时间复杂度相同,均为O(logn)。因此,跳表的各操作时间复杂度为:
- 查找:O(logn)
- 插入:O(logn)
- 删除:O(logn)
3.2 空间复杂度分析
单看跳表的结构,其在原始链表上增加了大量的索引层级,那这样会不会导致整个结构的空间复杂度急剧膨胀呢?其实并不会。
(1)假设原始链表长度为n个节点,按照每2个节点抽取一个节点生成上级索引的方式来构建,那么每层索引的节点数从最低级到最高级分别为: n 2 , n 4 , n 8 , . . . , 8 , 4 , 2 \frac{n}{2}, \frac{n}{4}, \frac{n}{8}, ..., 8, 4, 2 2n,4n,8n,...,8,4,2
很明显,这是一个等比数列,应用等比数列的求和公式可以得到所有的索引节点总和数为: n 2 + n 4 + n 8 + . . . + 8 + 4 + 2 = n 2 − 2 ∗ 1 2 1 − 1 2 = n − 2 \frac{n}{2}+\frac{n}{4}+\frac{n}{8}+...+8+4+2=\frac{\frac{n}{2}-2*\frac{1}{2}}{1-\frac{1}{2}}=n-2 2n+4n+8n+...+8+4+2=1−212n−2∗21=n−2
而原始链表的长度为n,因此该跳表的空间复杂度为O(n)
(2)而同样,假设原始链表长度为n,为减少索引节点数量,将索引节点改为每3个节点抽取1个的方式生成索引,那么每层索引的节点数分别为: n 3 , n 9 , n 27 , . . . , 9 , 3 , 1 \frac{n}{3}, \frac{n}{9}, \frac{n}{27}, ..., 9, 3, 1 3n,9n,27n,...,9,3,1
此时应用等比数列求和公式可以得到的所有索引节点总数为:
n 3 + n 9 + n 27 + . . . + 9 + 3 + 1 = n 3 − 1 ∗ 1 3 1 − 1 3 = n − 1 2 \frac{n}{3}+\frac{n}{9}+\frac{n}{27}+...+9+3+1=\frac{\frac{n}{3}-1*\frac{1}{3}}{1-\frac{1}{3}}=\frac{n-1}{2} 3n+9n+27n+...+9+3+1=1−313n−1∗31=2n−1
可以看到,虽然时间复杂度仍为O(n),但相比每个两个节点取一个的方式,已经减少了将近一半的索引节点数。
4. 现实中的跳表
实际应用中由于元素的增加和删除会导致跳表的索引并不工整,所以各索引步跨的步数不尽相同。如下图所示。
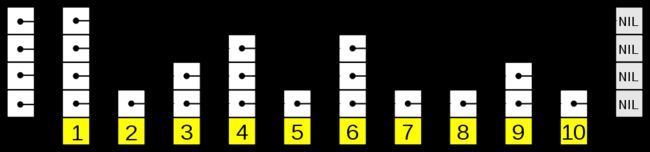
因为随着不断插入新节点和删除旧节点,某级相邻的两个索引节点跨越的链表节点数目在变化,这种变化最坏情况下可能退化为跨越整个原始链表,使得查找速度退化为O(n)。为了避免这种情况,实际应用中还会随着对底层链表的插入和删除操作,对上层的索引节点采用某些策略进行动态调整。
5. 跳表的应用
跳表最经典的应用就是在Redis中实现有序集数据类型。当然,跳表在Redis中的唯一作用也就是对该数据类型的实现。但是Redis中除了使用跳表作为有序集类型的底层数据结构外,还使用了字典来构成有序集。
当然,为了满足自身的需要,Redis也基于William Pugh 论文中描述的跳跃表进行了修改,包括:
-
score值可重复(score值可理解为跳表的原始链表中每个节点中存储的值)
-
对比一个元素需要同时检查它的 score 和 memeber (因为第一条,所以仅依靠score值无法判断一个元素节点)
-
每个节点带有高度为 1 层的后退指针,用于从表尾方向向表头方向迭代。
参考资料
[1] 极客时间-数据结构与算法之美:https://time.geekbang.org/column/intro/126
[2] 跳跃列表-维基百科:https://zh.wikipedia.org/wiki/%E8%B7%B3%E8%B7%83%E5%88%97%E8%A1%A8
[3] 跳跃表——Redis设计与实现:https://redisbook.readthedocs.io/en/latest/internal-datastruct/skiplist.html