视频超分:DUF(Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without ...)

论文:基于 非动作补偿 动态上采样滤波器的深度视频超分网络
文章检索出处:2018 Conference on Computer Vision and Pattern Recognition(CVPR)
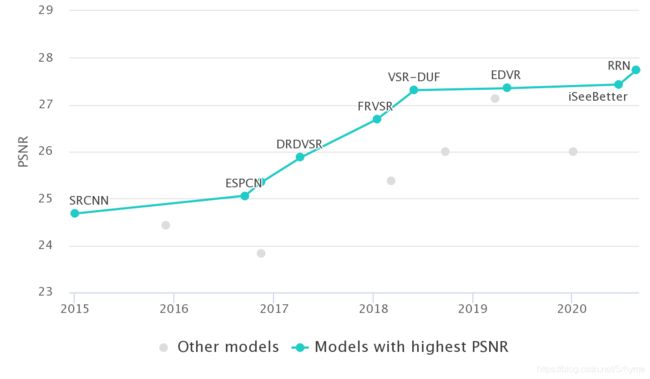
Video Super-Resolution on Vid4 - 4x upscaling
FRVSR:26.690 VSR-DUF:27.310 EDVR:27.350 RRN:27.690 (图像出自paper with code 2020.9.7)
摘要:
- 我们提出了一种新的端到端深度神经网络,用于生成动态上采样滤波器和残差图像,这些滤波器和残差图像是根据每个像素的局部时空邻域来计算的,以避免显式运动补偿。该方法使用动态上采样滤波器对输入图像进行直接重构,并通过计算残差增加细节。
- 我们的网络借助一种新的数据增强技术,可以生成具有时间一致性的更清晰的HR视频。我们还通过大量的实验对我们的网络进行分析,以显示网络如何隐式地处理运动。
模型结构:
在dense block中,我们使用3D卷积去替代2D卷积去从视频中学习时空特征
在残差图像的生成中,我们使用VDSR的残差结构(conv(3x3x64),relu),不同的是我们的残差图像来自于多帧而不是单帧
每个输入的LR帧都由共享的2D卷积层处理,然后在时空axis上进行连接
最终输出的Yt图像是由滤波器层输出的图像和残差图像相加获得的

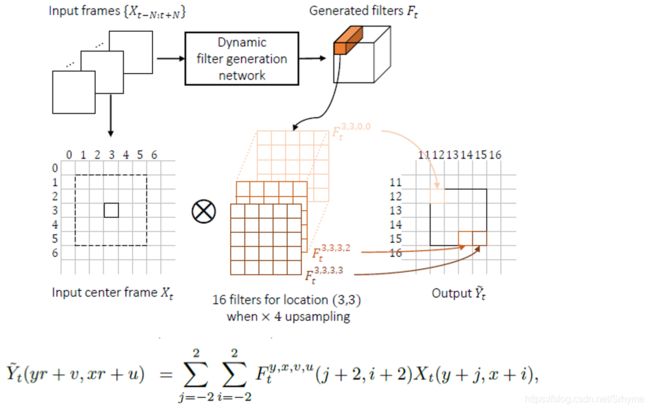
动态上采样滤波器:
将一组输入LR帧{Xt-n:t+n} (N = 3) 送入动态滤波器生成网络。训练网络输出一组 r²HW 大小(5x5)的上采样过滤器 Ft,然后对输入帧中的LR像素进行局部滤波,得到每个输出HR的像素值
模型代码:
import tensorflow as tf
import numpy as np
import keras
from keras.layers import Conv2D,BatchNormalization,ReLU,Conv3D,ZeroPadding3D,ZeroPadding2D,Reshape,Lambda
from keras.models import Sequential,Input,Model
from keras.utils import plot_model
from keras import losses
from keras.optimizers import Adam
import warnings
warnings.filterwarnings("ignore")
# Parameter
T = 7 # images num T = 2 * N +1
R = 4 # upscaling factor
pixel_x = 144
pixel_y = 180
# Custom Layers
def depth_to_space(x):
return tf.depth_to_space(x, R)
def depth_to_space_output_shape(input_shape):
return (input_shape[0], input_shape[1] * R, input_shape[2] * R , input_shape[3] // ( R * R ))
# Model
ori_input = Input( shape=(T,pixel_x,pixel_y,3) )
digit_input = ZeroPadding3D(padding=(0, 1, 1))(ori_input)
concatenated = Conv3D(64, (1, 3, 3))(digit_input)
for i in range(3):
input_shape=concatenated.shape
models = BatchNormalization()(concatenated)
models = ReLU()(models)
models = Conv3D(int(input_shape[-1]), 1 ,input_shape=input_shape[1:])(models)
models = BatchNormalization()(models)
models = ReLU()(models)
models = ZeroPadding3D(padding=(1, 1, 1))(models)
models = Conv3D(32, 3,input_shape=input_shape[1:])(models)
concatenated = keras.layers.concatenate([models, concatenated],axis=4)
for i in range(3):
input_shape=concatenated.shape
models = BatchNormalization()(concatenated)
models = ReLU()(models)
models = Conv3D(int(input_shape[-1]), 1 ,input_shape=input_shape[1:])(models)
models = BatchNormalization()(models)
models = ReLU()(models)
models = ZeroPadding3D(padding=(0, 1, 1))(models)
models = Conv3D(32, 3,input_shape=input_shape[1:])(models)
concatenated=Lambda(lambda a: a[:, 1:-1], input_shape=[5])(concatenated)
concatenated = keras.layers.concatenate([models, concatenated],axis=4)
models = BatchNormalization()(concatenated)
models = ReLU()(models)
models = ZeroPadding3D((0,1,1))(models)
models = Conv3D(256 , (1,3,3) ,input_shape= models.shape)(models)
# Residual generation network
rgn = ReLU()(models)
rgn = Conv3D( 256 , 1 ,input_shape= rgn.shape)(rgn)
rgn = ReLU()(rgn)
rgn = Conv3D(3 * 16 , 1 ,input_shape= rgn.shape)(rgn)
rgn = Reshape((pixel_x,pixel_y,16*3))(rgn)
rt = Lambda(depth_to_space,output_shape=depth_to_space_output_shape,name='residual')(rgn)
# Filter generation network
fgn = ReLU()(models)
fgn = Conv3D(512, 1 ,input_shape= fgn.shape)(fgn)
fgn = ReLU()(fgn)
fgn = Conv3D(1 * 5 * 5 * 16, 1 ,input_shape= fgn.shape)(fgn)
fgn = Reshape((pixel_x,pixel_y,25,16))(fgn)
fgn = Lambda( lambda x : tf.keras.activations.softmax(x, axis=3),name='softmax')(fgn)
sr=[]
for c in range(3):
xt=Lambda(lambda a: a[:,T//2,:,:,c], input_shape=[5])(ori_input)
xt =Reshape((pixel_x,pixel_y,1))(xt)
xt = Conv2D(1 * 5 * 5, 1 ,input_shape= xt.shape)(xt)
xt = Reshape((pixel_x,pixel_y,1,25))(xt)
xt = Lambda( lambda x: tf.matmul(x[0],x[1]))([xt,fgn])
xt = Reshape(((pixel_x, pixel_y, 16)))(xt)
xt = Lambda(depth_to_space,output_shape=depth_to_space_output_shape)(xt)
sr+=[xt]
yt = keras.layers.concatenate([sr[0],sr[1],sr[2]],axis=3)
# combine
out = Lambda( lambda x: x + rt , name='combine')(yt)
# model summary
model = Model(ori_input, out)
model.summary()
# plot_model(model, show_shapes=True,to_file='model.png')
WARNING:tensorflow:From D:\Anaconda\envs\env1\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
Using TensorFlow backend.
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 7, 144, 180, 0
__________________________________________________________________________________________________
zero_padding3d_1 (ZeroPadding3D (None, 7, 146, 182, 0 input_1[0][0]
__________________________________________________________________________________________________
conv3d_1 (Conv3D) (None, 7, 144, 180, 1792 zero_padding3d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 7, 144, 180, 256 conv3d_1[0][0]
__________________________________________________________________________________________________
re_lu_1 (ReLU) (None, 7, 144, 180, 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv3d_2 (Conv3D) (None, 7, 144, 180, 4160 re_lu_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 7, 144, 180, 256 conv3d_2[0][0]
__________________________________________________________________________________________________
re_lu_2 (ReLU) (None, 7, 144, 180, 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
zero_padding3d_2 (ZeroPadding3D (None, 9, 146, 182, 0 re_lu_2[0][0]
__________________________________________________________________________________________________
conv3d_3 (Conv3D) (None, 7, 144, 180, 55328 zero_padding3d_2[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 7, 144, 180, 0 conv3d_3[0][0]
conv3d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 7, 144, 180, 384 concatenate_1[0][0]
...
Total params: 1,826,630
Trainable params: 1,822,662
Non-trainable params: 3,968
__________________________________________________________________________________________________
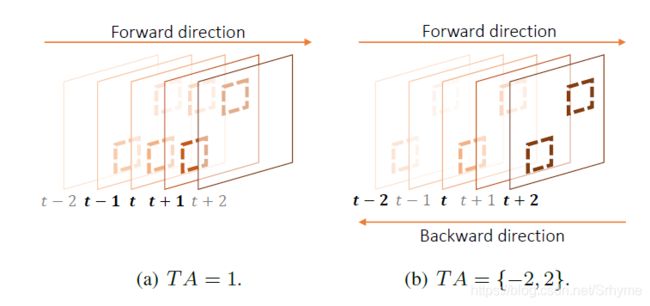
数据扩充:
为了拟合真实世界的运动,我们需要相应的训练数据。我们在一般数据扩充(如随机旋转和翻转)之上,在时间轴上采用数据扩充。我们引入变量TA,它决定了时间增强的采样间隔。例如,TA=2,我们将对每间隔一帧进行采样,以模拟更快的运动。当我们将TA值设置为负值时,我们还可以按照相反的顺序创建一个新的视频样本。
(注意,在|TA|>3的情况下,VSR性能会随着object的位移太大而降低。)
实施
训练集:在VSR中没有像ImageNet这样的数据集。因此作者收集了351个来自不同领域的视频,获得了160,000个大小为144*144的有效样本。
验证集:来自Derf’s collection 的四个视频。
测试集:Vid4
在获取LR的过程中,样本首先经过Gaussian filter,后下采样r倍。本文大小为(32x32)
使用Huber损失作为损失函数,其中δ=0.01
>使用Adam优化器,初始学习率为0.0001,每10个epochs后 x0.1
在测试阶段,我们在时间维度上对输入使用zero padded去避免帧数量的降低。
本文mini_batch设置为16,T设置为7,变量初始化使用He初始化
损失函数与优化器:
def huber_loss(y_true, y_pred, clip_delta=1.0):
error = y_true - y_pred
cond = tf.keras.backend.abs(error) < clip_delta
squared_loss = 0.5 * tf.keras.backend.square(error)
linear_loss = clip_delta * (tf.keras.backend.abs(error) - 0.5 * clip_delta)
return tf.where(cond, squared_loss, linear_loss)
model.compile(loss=huber_loss, optimizer=Adam())
实验效果
对比不同层数的模型:

量化分析 :

细节图:

总结:
使用NVidia GeForce GTX 1080Ti,对Ours-16L、Ours-28L和Ours-52L分别进行0.4030s、0.8382s和2.8189s的7个输入帧的480×270,生成单个1920×1080输出帧需要训练2天。其中大约一半的运行时间花在局部过滤上。
原创文章,如需转载请注明出处,谢谢。