【爬虫】每天定时爬取网页小故事并发送至指定邮箱
看题目 ,需要实现三部分工作,第一部分为爬取网页小故事,第二部分为发送至指定邮箱,第三部分为定时启动程序。爬取网页内容可以使用BeautifulSoup库实现,发送邮件可以使用smtplib库实现,定时启动程序可以在Windows下设置任务计划程序实现。因此,本文主要包含了以下三部分内容:
文章目录
- 一、爬取网页故事
- 1. 思路分析
- 2. 示例代码
- 二、Python发送邮件
- 三、Windows设置任务计划程序
- 四、完整代码
- 本文参考
一、爬取网页故事
1. 思路分析
爬取网页内容的思路一般是这样的:
- 规定一个或多个入口url
- 获取所有内容所在页面的url
- 请求目标页面url得到数据,解析数据得到文本内容
例如我们要爬取贝瓦故事http://story.beva.com/网站中的睡前所有睡前故事。通过分析我们知道了它的睡前故事列表所在的页面url结构都类似于http://story.beva.com/99/category/shui-qian/1了,随着页码的增加最后的数字也发生变化。那么我们可以使用一个循环遍历它的页码范围,构造出所有的故事列表所在页面的url,组成一个url列表,这些url列表也就是入口url。
![]()

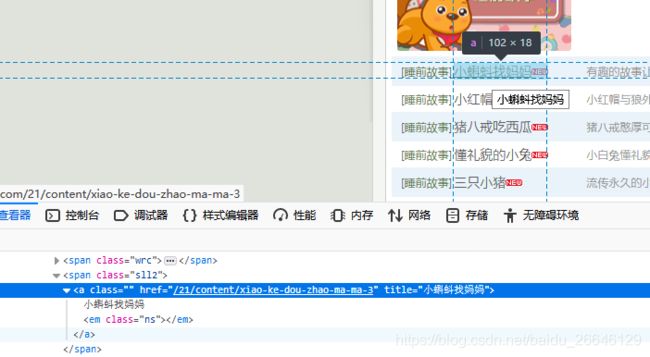
接着,我们请求每个入口url,解析该页面上故事列表的url,得到了每一则故事对应的url。打开开发者工具,通过分析网页结构我们了解到每一个故事页面的url在class为sll2的span标签下的a标签的href属性中,而且从这个a标签title属性中我们还可以得到故事名称。
注意,a标签的href属性中内容并不是故事网页的完整url,点击进入故事页面我们可以发现故事页面的完整url应该是http://story.beva.com + a标签href内容。根据这个规律,我们先获取所有符合条件a标签的href,并且在href之前加上http://story.beva.com构成完整的故事页面url列表。
![]()
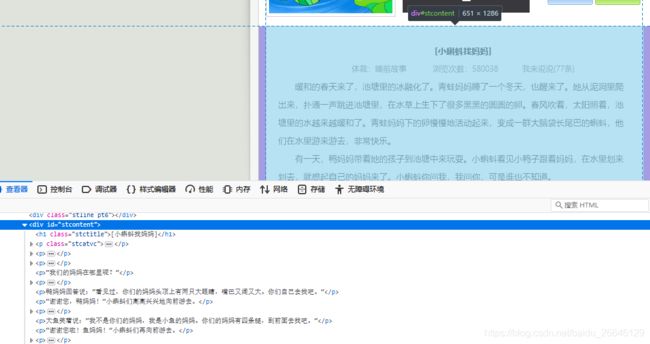
最后,我们就可以请求故事页面url,并且解析其中的内容啦。分析网页结构可以发现,故事正文内容在class为stcontent的div标签中,我们可以借助BeautifulSoup来解析文本内容。
2. 示例代码
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
def getHtmlText(url, headers):
"""
请求url,返回HTML文本
:param url: 页面url
:return html: 页面HTML
"""
try:
res = requests.get(url, headers = headers, timeout = 30) # headers伪造请求头,模拟浏览器,防止和谐
res.raise_for_status() # 返回4XX、5XX时抛出异常
res.encoding = res.apparent_encoding # 设置该html文档可能的编码
return res.text # 返回网页HTML代码
except:
return "获取失败"
def parseHtml(html, story_url_list, story_title_list):
"""
解析HTML文本,得到故事链接和故事名字列表
:param html: 故事列表页面html
"""
base_url = 'http://story.beva.com'
soup = BeautifulSoup(html, 'html.parser')
spans = soup.find('span', attrs = {'class': 'sll2'}
for span in spans:
story_url = base_url + span.a.get('href')
story_url_list.append(story_url)
story_title_list.append(span.a.get('title'))
def parseHtml2(html):
"""
解析故事页面HTMl文本,得到故事正文
:param html: 故事页面html
"""
story_content = []
soup = BeautifulSoup(html, 'html.parser')
div = soup.find('div', class_ = 'stcontent')
for p in div.findAll('p'):
story_content.append(p.text)
#print(story_content)
return "\n".join(story_content)
if __name__ == '__main__':
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
}
story_url_list = [] # 保存所有故事url
story_title_list = [] # 保存所有故事title
for i in range(22):
story_list_url = 'http://story.beva.com/99/category/shui-qian/' + str(i + 1)
print('正在爬取第%s页的故事链接:'%(i+1))
print(story_list_url)
html = getHtmlText(story_list_url, headers) # 请求故事列表页面url
parseHtml(html, story_url_list, story_title_list) # 得到故事页面的url
print("爬取链接完成")
'''
for url in story_url_list:
html = getHtmlText(url, headers) # 请求故事页面url
parseHtml2(html) # 得到故事正文
'''
二、Python发送邮件
smtplib模块是python中smtp(简单邮件传输协议)的客户端实现。我们可以使用smtplib模块,轻松的发送电子邮件。有关smtplib模块的介绍,可以参考http://www.cnblogs.com/babykick/archive/2011/03/28/1997587.html。
smtplib发送邮件的过程比较简单:
- 连接邮件服务器
- 使用邮箱地址和授权码登录邮件服务器
- 构造邮件主题、正文等内容,发送邮件
from email.mime.text import MIMEText
def sendEmail(url, headers):
msg_from = '[email protected]' # 发送方邮箱
pwd = 'xxxxxxxxxxxxxxxx' # 填入发送方邮箱的授权码
receivers = ['[email protected]'] # 收件人邮箱
subject = '今日份的睡前小故事' # 主题
html = getHTMLText(url, headers)
content = parseHtml2(html) # 正文
msg = MIMEText(content)
msg['Subject'] = subject
msg['From'] = msg_from
msg['To'] = ','.join(receivers)
try:
smtp=smtplib.SMTP_SSL("smtp.qq.com",465) # QQ邮箱邮件服务器及端口号
smtp.login(msg_from, pwd)
smtp.sendmail(msg_from, msg['To'].split(','), msg.as_string())
print("发送成功")
except:
print("发送失败")
finally:
smtp.quit()
三、Windows设置任务计划程序
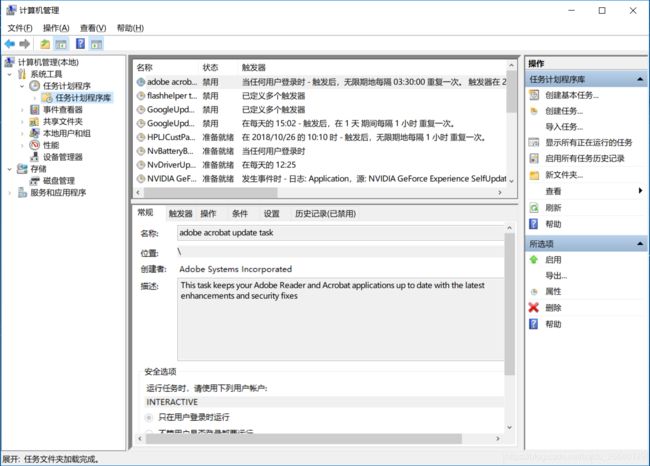
任务计划程序指的是那些在特定时刻,如开关机、每周或者每天特定时间执行的程序。在Windows10系统中,可以通过右键单击此电脑,点击管理进入设置任务计算程序。
1.右键单击任务计划程序库,选择创建基本任务。
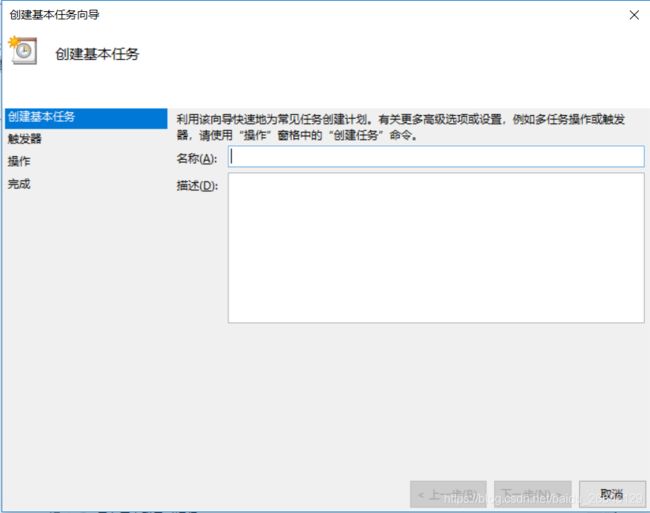
2.在弹出的对话框中,先输入这个任务的名称和描述。
3.选择执行的频率,这里默认选择每天。
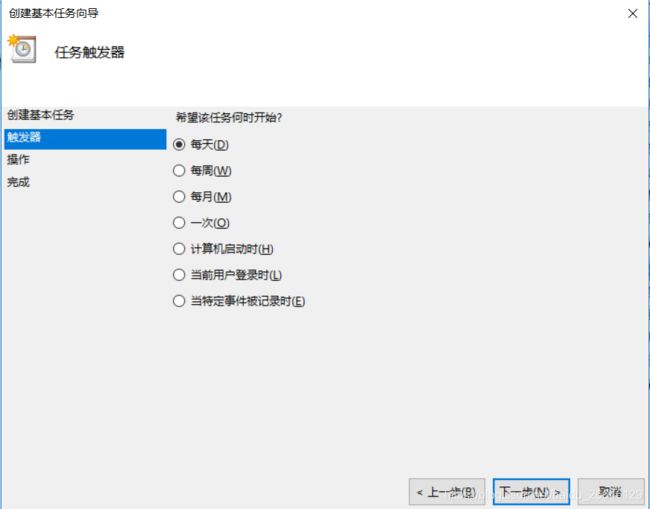
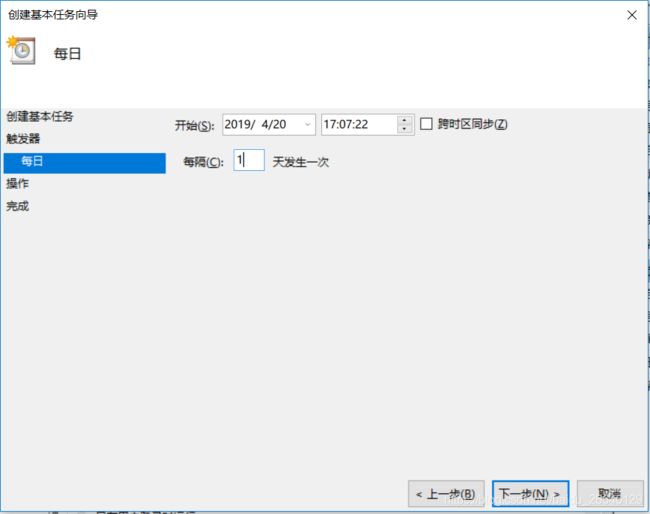
4.设置每天具体的执行时间点。
5.选择操作类型,这里选择启动程序。在命令行环境下,我们通常使用python filename.py来执行一个python脚本,同样的,我们需要在启动程序对话框中设置类似的格式来启动我们的python脚本。程序或脚本输入框填写的是你机器上python可执行文件所在的路径,python.exe和pythonw.exe的区别在于一个有对话框,一个是静默执行。添加参数输入框则为脚本文件所在路径。
这里需要注意一点,如果你机器上有多个python环境时,你得先确认默认使用的是哪个python环境,并将其可执行文件填入下图中的程序或脚本,否则没有效果。
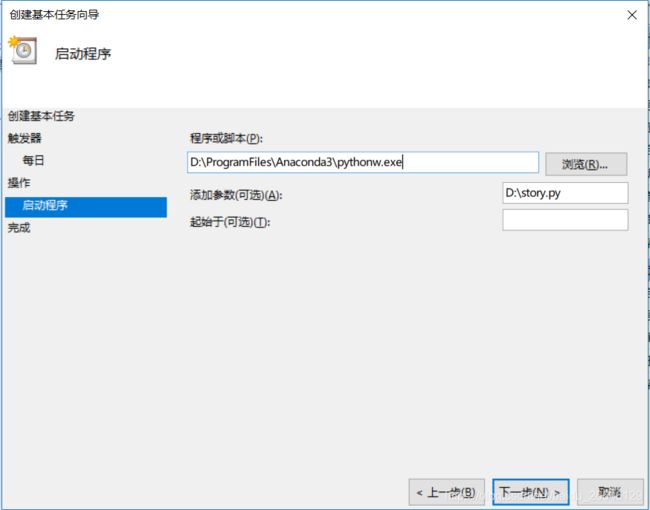
接着就大公告成啦!!!
四、完整代码
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import smtplib
from email.mime.text import MIMEText
import random
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
def getHtmlText(url, headers):
"""
请求url,返回HTML文本
:param url: 页面url
:return html: 页面HTML
"""
try:
res = requests.get(url, headers = headers, timeout = 30) # headers伪造请求头,模拟浏览器,防止和谐
res.raise_for_status() # 返回4XX、5XX时抛出异常
res.encoding = res.apparent_encoding # 设置该html文档可能的编码
return res.text # 返回网页HTML代码
except:
return "获取失败"
def parseHtml(html, story_url_list, story_title_list):
"""
解析HTML文本,得到故事链接和故事名字列表
:param html: 故事列表页面html
"""
base_url = 'http://story.beva.com'
soup = BeautifulSoup(html, 'html.parser')
spans = soup.find('span', attrs = {'class': 'sll2'}
for span in spans:
story_url = base_url + span.a.get('href')
story_url_list.append(story_url)
story_title_list.append(span.a.get('title'))
def parseHtml2(html):
"""
解析故事页面HTMl文本,得到故事正文
:param html: 故事页面html
"""
story_content = []
soup = BeautifulSoup(html, 'html.parser')
div = soup.find('div', class_ = 'stcontent')
for p in div.findAll('p'):
story_content.append(p.text)
#print(story_content)
return "\n".join(story_content)
def sendEmail(url, headers):
"""
将故事正文发送右键
"""
msg_from = '[email protected]' # 发送方邮箱
pwd = 'xxxxxxxxxxxxxxxx' # 填入发送方邮箱的授权码
receivers = ['[email protected]'] # 收件人邮箱
subject = '今日份的睡前小故事' # 主题
html = getHTMLText(url, headers)
content = parseHtml2(html) # 正文
msg = MIMEText(content)
msg['Subject'] = subject
msg['From'] = msg_from
msg['To'] = ','.join(receivers)
try:
smtp=smtplib.SMTP_SSL("smtp.qq.com",465) # QQ邮箱邮件服务器及端口号
smtp.login(msg_from, pwd)
smtp.sendmail(msg_from, msg['To'].split(','), msg.as_string())
print("发送成功")
except:
print("发送失败")
finally:
smtp.quit()
def main()
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
}
story_url_list = [] # 保存所有故事url
story_title_list = [] # 保存所有故事title
for i in range(22):
story_list_url = 'http://story.beva.com/99/category/shui-qian/' + str(i + 1)
print('正在爬取第%s页的故事链接:'%(i+1))
print(story_list_url)
html = getHtmlText(story_list_url, headers) # 请求故事列表页面url
parseHtml(html, story_url_list, story_title_list) # 得到故事页面的url
print("爬取链接完成")
'''
for url in story_url_list:
html = getHtmlText(url, headers) # 请求故事页面url
parseHtml2(html) # 得到故事正文
'''
sendemail(random.choice(urllist),headers)
if __name__ == '__main__':
main()
本文参考
[1] https://blog.csdn.net/lyc44813418/article/details/88583021