Spark学习笔记@第一个例子wordcount+Eclipse
编写程序代码
使用IDE为Eclipse;
1、 新建Scalaproject,完成后右击“wordcount”工程,选择properties在弹出的框中,按照下图所示,依次选择“Java Build Path” –>“Libraties” –>“Add External JARs…”,导入spark依赖的jar包,如下:
$SPARK_HOME/lib
$HADOOP_HOME/share/hadoop/common
$HADOOP_HOME/share/hadoop/common/lib
$HADOOP_HOME/share/hadoop/hdfs
$HADOOP_HOME/share/hadoop/hdfs/lib
$HADOOP_HOME/share/hadoop/mapreduce
$HADOOP_HOME/share/hadoop/yarn
$HADOOP_HOME/share/hadoop/tools/lib

2、新建Scala object
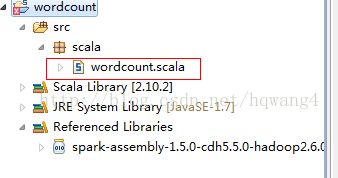
3、wordcount代码如下:
package scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object wordcount {
def main(args:Array[String]) {
if(args.length < 1) {
System.err.println("Usage:
System.exit(1)
}
val conf = new SparkConf()
val sc = new SparkContext(conf)
val line = sc.textFile(args(0))
line.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect.foreach(println)
sc.stop
}
}
将程序打包
在Scala工程中,右击“wordcount.scala”,选择“Export”,并在弹出框中选择“Java” –> “JAR File”,进而将该程序编译成jar包

编写执行脚本
vi run_wordcount.sh
#!/bin/bash
$SPARK_HOME/bin/spark-submit \
--master spark://192.168.1.108:7077 \
--class scala.wordcount \
--name wordcount \
--executor-memory 128m \
--driver-memory 128m \
/home/hadoop/work/wordcount/spark-wordcount-scala.jar\
hdfs://192.168.1.106:9000/mr/input/start-all.sh
执行脚本
将本地文件导入Hdfs
hadoop fs -put/home/hadoop/cdh5.5.0/spark/sbin/start-all.sh /mr/input
运行wordcount脚本
sh run_wordcount.sh
运行结果
17/04/10 15:02:35 INFO spark.SecurityManager:Changing view acls to: hadoop
17/04/10 15:02:35 INFOspark.SecurityManager: Changing modify acls to: hadoop
17/04/10 15:02:35 INFOspark.SecurityManager: SecurityManager: authentication disabled; ui aclsdisabled; users with view permissions: Set(hadoop); users with modifypermissions: Set(hadoop)
17/04/10 15:02:51 INFO slf4j.Slf4jLogger:Slf4jLogger started
17/04/10 15:02:53 INFO Remoting: Startingremoting
17/04/10 15:02:55 INFO Remoting: Remotingstarted; listening on addresses :[akka.tcp://[email protected]:49582]
17/04/10 15:02:55 INFO Remoting: Remotingnow listens on addresses: [akka.tcp://[email protected]:49582]
17/04/10 15:02:55 INFO util.Utils:Successfully started service 'sparkDriver' on port 49582.
17/04/10 15:02:55 INFO spark.SparkEnv:Registering MapOutputTracker
17/04/10 15:02:56 INFO spark.SparkEnv:Registering BlockManagerMaster
17/04/10 15:02:57 INFOstorage.DiskBlockManager: Created local directory at/tmp/blockmgr-17c60685-0a70-40fa-a525-bd85811b5d08
17/04/10 15:02:57 INFO storage.MemoryStore:MemoryStore started with capacity 66.7 MB
17/04/10 15:02:59 INFOspark.HttpFileServer: HTTP File server directory is/tmp/spark-f030ed67-30ee-4c16-9657-1c82ff530233/httpd-e8fad2c1-2522-4e53-b9de-3ed58eb1704b
17/04/10 15:02:59 INFO spark.HttpServer:Starting HTTP Server
17/04/10 15:03:01 INFO server.Server:jetty-8.y.z-SNAPSHOT
17/04/10 15:03:01 INFOserver.AbstractConnector: Started [email protected]:56333
17/04/10 15:03:01 INFO util.Utils:Successfully started service 'HTTP file server' on port 56333.
17/04/10 15:03:02 INFO spark.SparkEnv:Registering OutputCommitCoordinator
17/04/10 15:03:14 INFO server.Server:jetty-8.y.z-SNAPSHOT
17/04/10 15:03:15 INFOserver.AbstractConnector: Started [email protected]:4040
17/04/10 15:03:15 INFO util.Utils:Successfully started service 'SparkUI' on port 4040.
17/04/10 15:03:15 INFO ui.SparkUI: StartedSparkUI at http://127.0.0.1:4040
17/04/10 15:03:16 INFO spark.SparkContext:Added JAR file:/home/hadoop/work/wordcount/spark-wordcount-scala.jar athttp://127.0.0.1:56333/jars/spark-wordcount-scala.jar with timestamp1491807796391
17/04/10 15:03:17 WARNmetrics.MetricsSystem: Using default name DAGScheduler for source becausespark.app.id is not set.
17/04/10 15:03:18 INFO client.AppClient$ClientEndpoint:Connecting to master spark://192.168.1.108:7077...
17/04/10 15:03:22 INFOcluster.SparkDeploySchedulerBackend: Connected to Spark cluster with app IDapp-20170410150322-0001
17/04/10 15:03:22 INFOclient.AppClient$ClientEndpoint: Executor added: app-20170410150322-0001/0 onworker-20170410144006-127.0.0.1-42015 (127.0.0.1:42015) with 1 cores
17/04/10 15:03:22 INFOcluster.SparkDeploySchedulerBackend: Granted executor IDapp-20170410150322-0001/0 on hostPort 127.0.0.1:42015 with 1 cores, 128.0 MBRAM
17/04/10 15:03:23 INFOclient.AppClient$ClientEndpoint: Executor updated: app-20170410150322-0001/0 isnow LOADING
17/04/10 15:03:23 INFOclient.AppClient$ClientEndpoint: Executor updated: app-20170410150322-0001/0 isnow RUNNING
17/04/10 15:03:25 INFO util.Utils:Successfully started service'org.apache.spark.network.netty.NettyBlockTransferService' on port 42824.
17/04/10 15:03:25 INFOnetty.NettyBlockTransferService: Server created on 42824
17/04/10 15:03:25 INFO storage.BlockManagerMaster:Trying to register BlockManager
17/04/10 15:03:25 INFOstorage.BlockManagerMasterEndpoint: Registering block manager 127.0.0.1:42824with 66.7 MB RAM, BlockManagerId(driver, 127.0.0.1, 42824)
17/04/10 15:03:25 INFOstorage.BlockManagerMaster: Registered BlockManager
17/04/10 15:03:32 INFOcluster.SparkDeploySchedulerBackend: SchedulerBackend is ready for schedulingbeginning after reached minRegisteredResourcesRatio: 0.0
17/04/10 15:03:51 INFO storage.MemoryStore:ensureFreeSpace(70832) called with curMem=0, maxMem=69929533
17/04/10 15:03:51 INFO storage.MemoryStore:Block broadcast_0 stored as values in memory (estimated size 69.2 KB, free 66.6MB)
17/04/10 15:03:53 INFO storage.MemoryStore:ensureFreeSpace(7626) called with curMem=70832, maxMem=69929533
17/04/10 15:03:53 INFO storage.MemoryStore:Block broadcast_0_piece0 stored as bytes in memory (estimated size 7.4 KB, free66.6 MB)
17/04/10 15:03:53 INFOstorage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 127.0.0.1:42824(size: 7.4 KB, free: 66.7 MB)
17/04/10 15:03:54 INFO spark.SparkContext:Created broadcast 0 from main at NativeMethodAccessorImpl.java:-2
17/04/10 15:04:15 INFOmapred.FileInputFormat: Total input paths to process : 1
17/04/10 15:04:16 INFO spark.SparkContext:Starting job: main at NativeMethodAccessorImpl.java:-2
17/04/10 15:04:16 INFOscheduler.DAGScheduler: Registering RDD 3 (main atNativeMethodAccessorImpl.java:-2)
17/04/10 15:04:16 INFOscheduler.DAGScheduler: Got job 0 (main at NativeMethodAccessorImpl.java:-2)with 2 output partitions
17/04/10 15:04:16 INFOscheduler.DAGScheduler: Final stage: ResultStage 1(main atNativeMethodAccessorImpl.java:-2)
17/04/10 15:04:16 INFOscheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
17/04/10 15:04:16 INFOscheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 0)
17/04/10 15:04:16 INFOscheduler.DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] atmain at NativeMethodAccessorImpl.java:-2), which has no missing parents
17/04/10 15:04:17 INFO storage.MemoryStore:ensureFreeSpace(4072) called with curMem=78458, maxMem=69929533
17/04/10 15:04:17 INFO storage.MemoryStore:Block broadcast_1 stored as values in memory (estimated size 4.0 KB, free 66.6MB)
17/04/10 15:04:17 INFO storage.MemoryStore:ensureFreeSpace(2326) called with curMem=82530, maxMem=69929533
17/04/10 15:04:17 INFO storage.MemoryStore:Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free66.6 MB)
17/04/10 15:04:17 INFOstorage.BlockManagerInfo: Added broadcast_1_piece0 in memory on 127.0.0.1:42824(size: 2.3 KB, free: 66.7 MB)
17/04/10 15:04:17 INFO spark.SparkContext:Created broadcast 1 from broadcast at DAGScheduler.scala:861
17/04/10 15:04:17 INFOscheduler.DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0(MapPartitionsRDD[3] at main at NativeMethodAccessorImpl.java:-2)
17/04/10 15:04:17 INFOscheduler.TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
17/04/10 15:04:26 ERROR akka.ErrorMonitor:AssociationError [akka.tcp://[email protected]:49582] <-[akka.tcp://[email protected]:41014]: Error [Shut down address:akka.tcp://[email protected]:41014] [
akka.remote.ShutDownAssociation: Shut downaddress: akka.tcp://[email protected]:41014
Caused by:akka.remote.transport.Transport$InvalidAssociationException: The remote systemterminated the association because it is shutting down.
]
akka.event.Logging$Error$NoCause$
17/04/10 15:04:32 WARNscheduler.TaskSchedulerImpl: Initial job has not accepted any resources; checkyour cluster UI to ensure that workers are registered and have sufficientresources
17/04/10 15:04:34 INFOcluster.SparkDeploySchedulerBackend: Registered executor:AkkaRpcEndpointRef(Actor[akka.tcp://[email protected]:43159/user/Executor#866625468])with ID 0
17/04/10 15:04:35 INFOscheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 127.0.0.1,partition 0,ANY, 2209 bytes)
17/04/10 15:04:38 INFOstorage.BlockManagerMasterEndpoint: Registering block manager 127.0.0.1:59746with 66.7 MB RAM, BlockManagerId(0, 127.0.0.1, 59746)
17/04/10 15:04:52 INFOstorage.BlockManagerInfo: Added broadcast_1_piece0 in memory on 127.0.0.1:59746(size: 2.3 KB, free: 66.7 MB)
17/04/10 15:04:58 INFO storage.BlockManagerInfo:Added broadcast_0_piece0 in memory on 127.0.0.1:59746 (size: 7.4 KB, free: 66.7MB)
17/04/10 15:05:20 INFOscheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 127.0.0.1,partition 1,ANY, 2209 bytes)
17/04/10 15:05:20 INFOscheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 45983 ms on127.0.0.1 (1/2)
17/04/10 15:05:21 INFOscheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 619 ms on127.0.0.1 (2/2)
17/04/10 15:05:21 INFO scheduler.DAGScheduler:ShuffleMapStage 0 (main at NativeMethodAccessorImpl.java:-2) finished in 63.646s
17/04/10 15:05:21 INFOscheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have allcompleted, from pool
17/04/10 15:05:21 INFOscheduler.DAGScheduler: looking for newly runnable stages
17/04/10 15:05:21 INFOscheduler.DAGScheduler: running: Set()
17/04/10 15:05:21 INFOscheduler.DAGScheduler: waiting: Set(ResultStage 1)
17/04/10 15:05:21 INFOscheduler.DAGScheduler: failed: Set()
17/04/10 15:05:21 INFO scheduler.DAGScheduler:Missing parents for ResultStage 1: List()
17/04/10 15:05:21 INFOscheduler.DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at main atNativeMethodAccessorImpl.java:-2), which is now runnable
17/04/10 15:05:21 INFO storage.MemoryStore:ensureFreeSpace(2296) called with curMem=84856, maxMem=69929533
17/04/10 15:05:21 INFO storage.MemoryStore:Block broadcast_2 stored as values in memory (estimated size 2.2 KB, free 66.6MB)
17/04/10 15:05:21 INFO storage.MemoryStore:ensureFreeSpace(1383) called with curMem=87152, maxMem=69929533
17/04/10 15:05:21 INFO storage.MemoryStore:Block broadcast_2_piece0 stored as bytes in memory (estimated size 1383.0 B,free 66.6 MB)
17/04/10 15:05:21 INFOstorage.BlockManagerInfo: Added broadcast_2_piece0 in memory on 127.0.0.1:42824(size: 1383.0 B, free: 66.7 MB)
17/04/10 15:05:21 INFO spark.SparkContext:Created broadcast 2 from broadcast at DAGScheduler.scala:861
17/04/10 15:05:21 INFOscheduler.DAGScheduler: Submitting 2 missing tasks from ResultStage 1(ShuffledRDD[4] at main at NativeMethodAccessorImpl.java:-2)
17/04/10 15:05:21 INFOscheduler.TaskSchedulerImpl: Adding task set 1.0 with 2 tasks
17/04/10 15:05:21 INFOscheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, 127.0.0.1,partition 0,PROCESS_LOCAL, 1964 bytes)
17/04/10 15:05:22 INFOstorage.BlockManagerInfo: Added broadcast_2_piece0 in memory on 127.0.0.1:59746(size: 1383.0 B, free: 66.7 MB)
17/04/10 15:05:22 INFOspark.MapOutputTrackerMasterEndpoint: Asked to send map output locations forshuffle 0 to 127.0.0.1:43159
17/04/10 15:05:22 INFOspark.MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 147bytes
17/04/10 15:05:23 INFOscheduler.TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, 127.0.0.1,partition 1,PROCESS_LOCAL, 1964 bytes)
17/04/10 15:05:23 INFOscheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 1610 ms on127.0.0.1 (1/2)
17/04/10 15:05:23 INFOscheduler.DAGScheduler: ResultStage 1 (main atNativeMethodAccessorImpl.java:-2) finished in 2.278 s
17/04/10 15:05:23 INFOscheduler.TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 786 ms on127.0.0.1 (2/2)
17/04/10 15:05:23 INFOscheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have allcompleted, from pool
17/04/10 15:05:24 INFOscheduler.DAGScheduler: Job 0 finished: main atNativeMethodAccessorImpl.java:-2, took 67.839546 s
(;;,1)
(Unless,1)
(this,4)
(KIND,,1)
(is,1)
(under,4)
(--with-tachyon),1)
(one,1)
(Load,1)
(with,2)
(express,1)
("$0"`",1)
(WITHOUT,1)
(specific,1)
("AS,1)
(esac,1)
(IS",1)
(shift,1)
(ANY,1)
(ASF,1)
(Master,1)
(node.,1)
(2.0,1)
(BASIS,,1)
(file,3)
(node,1)
($TACHYON_STR,2)
(licenses,1)
(bash,1)
(specified,1)
(CONDITIONS,1)
(NOTICE,1)
(.,1)
(Apache,2)
(writing,,1)
(information,1)
(master,1)
(language,1)
(done,1)
(,31)
(TACHYON_STR="--with-tachyon",1)
(permissions,1)
(WARRANTIES,1)
(law,1)
(Start,3)
("$sbin/spark-config.sh",1)
(configuration,1)
(case,1)
(((,1)
(agreed,1)
(Version,1)
(sbin="`cd,1)
(implied.,1)
(worker,1)
("$sbin"/start-master.sh,1)
(Software,1)
(Spark,1)
(limitations,1)
(The,1)
(spark,1)
((the,1)
(TACHYON_STR="",1)
(daemons.,1)
(agreements.,1)
(on,3)
(You,2)
(each,1)
(while,1)
(#,22)
(contributor,1)
(at,1)
(in,4)
(#!/usr/bin/env,1)
(See,2)
(sbin="`dirname,1)
(copy,1)
(software,1)
(for,2)
(pwd`",1)
(License.,2)
(obtain,1)
(distributed,3)
(required,1)
("$sbin"/start-slaves.sh,1)
(OR,1)
(use,1)
(except,1)
(the,11)
(OF,1)
(may,2)
(Workers,1)
(not,1)
(either,1)
(you,1)
(a,2)
(or,3)
());,1)
(do,1)
(work,1)
("$#",1)
(all,1)
("License");,1)
(to,3)
(http://www.apache.org/licenses/LICENSE-2.0,1)
(applicable,1)
(more,1)
(License,3)
(license,1)
(of,1)
(by,1)
((ASF),1)
(governing,1)
(regarding,1)
(ownership.,1)
(License,,1)
(an,1)
(Foundation,1)
($1,1)
(and,1)
(copyright,1)
(conf/slaves,1)
(compliance,1)
("$sbin";,1)
(Licensed,1)
(Starts,2)
(additional,1)
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/metrics/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
17/04/10 15:05:24 INFO handler.ContextHandler:stopped o.s.j.s.ServletContextHandler{/static,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/executors/threadDump/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/executors/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/environment/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/environment,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/storage/rdd/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/storage/rdd,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/stages/pool/json,null}
17/04/10 15:05:24 INFO handler.ContextHandler:stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/stages/stage/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/stages/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stoppedo.s.j.s.ServletContextHandler{/jobs/job/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
17/04/10 15:05:24 INFOhandler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
17/04/10 15:05:24 WARNthread.QueuedThreadPool: 5 threads could not be stopped
17/04/10 15:05:24 INFO ui.SparkUI: StoppedSpark web UI at http://127.0.0.1:4040
17/04/10 15:05:25 INFOscheduler.DAGScheduler: Stopping DAGScheduler
17/04/10 15:05:25 INFOcluster.SparkDeploySchedulerBackend: Shutting down all executors
17/04/10 15:05:25 INFOcluster.SparkDeploySchedulerBackend: Asking each executor to shut down
17/04/10 15:05:25 INFOspark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
17/04/10 15:05:26 ERROR akka.ErrorMonitor:AssociationError [akka.tcp://[email protected]:49582] <- [akka.tcp://[email protected]:43159]:Error [Shut down address: akka.tcp://[email protected]:43159] [
akka.remote.ShutDownAssociation: Shut downaddress: akka.tcp://[email protected]:43159
Caused by:akka.remote.transport.Transport$InvalidAssociationException: The remote systemterminated the association because it is shutting down.
]
akka.event.Logging$Error$NoCause$
17/04/10 15:05:26 INFO storage.MemoryStore:MemoryStore cleared
17/04/10 15:05:26 INFOstorage.BlockManager: BlockManager stopped
17/04/10 15:05:26 INFOstorage.BlockManagerMaster: BlockManagerMaster stopped
17/04/10 15:05:26 INFOscheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint:OutputCommitCoordinator stopped!
17/04/10 15:05:26 INFO spark.SparkContext:Successfully stopped SparkContext
17/04/10 15:05:27 INFOutil.ShutdownHookManager: Shutdown hook called
17/04/10 15:05:27 INFOremote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
17/04/10 15:05:27 INFOutil.ShutdownHookManager: Deleting directory /tmp/spark-f030ed67-30ee-4c16-9657-1c82ff530233
17/04/10 15:05:27 INFOremote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down;proceeding with flushing remote transports.
问题解决
编译错误:RDD.class
问题描述
bad symbolic reference. A signature in RDD.classrefers to term compress in value org.apache.io which is not available. It maybe completely missing from the current classpath, or the version on theclasspath might be incompatible with the version used when compiling RDD.class. wordcount Unknown Scala Problem
bad symbolic reference. A signature inRDD.class refers to term hadoop in package org.apache which is not available.It may be completely missing from the current classpath, or the version on theclasspath might be incompatible with the version used when compiling RDD.class. wordcount Unknown Scala Problem
bad symbolic reference. A signature inRDD.class refers to term io in value org.apache.hadoop which is not available.It may be completely missing from the current classpath, or the version on theclasspath might be incompatible with the version used when compiling RDD.class. wordcount Unknown Scala Problem
问题解决
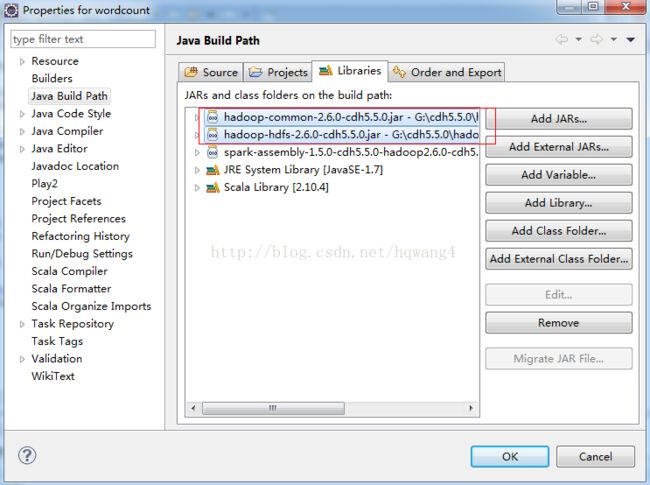
在libraries中增加common\hdfs包,如下:
执行spark-shell报util.SparkUncaughtExceptionHandler错误
错误描述
17/04/10 11:45:06 ERROR util.SparkUncaughtExceptionHandler:Uncaught exception in thread Thread[appclient-registration-retry-thread,5,main]
java.util.concurrent.RejectedExecutionException:Task java.util.concurrent.FutureTask@30d47af3 rejected fromjava.util.concurrent.ThreadPoolExecutor@4dd40090[Running, pool size = 1, activethreads = 1, queued tasks = 0, completed tasks = 0]
atjava.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2048)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:821)
atjava.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1372)
atjava.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:110)
at org.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$tryRegisterAllMasters$1.apply(AppClient.scala:96)
atorg.apache.spark.deploy.client.AppClient$ClientEndpoint$$anonfun$tryRegisterAllMasters$1.apply(AppClient.scala:95)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
atscala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
atscala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:108)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:108)
atorg.apache.spark.deploy.client.AppClient$ClientEndpoint.tryRegisterAllMasters(AppClient.scala:95)
atorg.apache.spark.deploy.client.AppClient$ClientEndpoint.org$apache$spark$deploy$client$AppClient$ClientEndpoint$$registerWithMaster(AppClient.scala:121)
atorg.apache.spark.deploy.client.AppClient$ClientEndpoint$$anon$2$$anonfun$run$1.apply$mcV$sp(AppClient.scala:132)
at org.apache.spark.util.Utils$.tryOrExit(Utils.scala:1119)
at org.apache.spark.deploy.client.AppClient$ClientEndpoint$$anon$2.run(AppClient.scala:124)
atjava.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178)
atjava.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
atjava.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
问题解决
将SPARK_MASTER_IP=node03改成
SPARK_MASTER_IP=192.168.1.108
执行spark-shell报ERROR Remoting: Remoting error: [Startup timed out]
问题描述
执行spark-shell后,发现Master shut down,出现如下日志:
Exception in thread "main"17/04/10 12:29:17 ERROR Remoting: Remoting error: [Startup timed out] [
akka.remote.RemoteTransportException:Startup timed out
atakka.remote.Remoting.akka$remote$Remoting$$notifyError(Remoting.scala:129)
at akka.remote.Remoting.start(Remoting.scala:191)
atakka.remote.RemoteActorRefProvider.init(RemoteActorRefProvider.scala:184)
at akka.actor.ActorSystemImpl._start$lzycompute(ActorSystem.scala:579)
at akka.actor.ActorSystemImpl._start(ActorSystem.scala:577)
at akka.actor.ActorSystemImpl.start(ActorSystem.scala:588)
at akka.actor.ActorSystem$.apply(ActorSystem.scala:111)
at akka.actor.ActorSystem$.apply(ActorSystem.scala:104)
atorg.apache.spark.util.AkkaUtils$.org$apache$spark$util$AkkaUtils$$doCreateActorSystem(AkkaUtils.scala:121)
at org.apache.spark.util.AkkaUtils$$anonfun$1.apply(AkkaUtils.scala:53)
atorg.apache.spark.util.AkkaUtils$$anonfun$1.apply(AkkaUtils.scala:52)
atorg.apache.spark.util.Utils$$anonfun$startServiceOnPort$1.apply$mcVI$sp(Utils.scala:1913)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:141)
atorg.apache.spark.util.Utils$.startServiceOnPort(Utils.scala:1904)
atorg.apache.spark.util.AkkaUtils$.createActorSystem(AkkaUtils.scala:55)
atorg.apache.spark.rpc.akka.AkkaRpcEnvFactory.create(AkkaRpcEnv.scala:253)
at org.apache.spark.rpc.RpcEnv$.create(RpcEnv.scala:53)
atorg.apache.spark.deploy.master.Master$.startRpcEnvAndEndpoint(Master.scala:1074)
at org.apache.spark.deploy.master.Master$.main(Master.scala:1058)
at org.apache.spark.deploy.master.Master.main(Master.scala)
Caused by:java.util.concurrent.TimeoutException: Futures timed out after [10000milliseconds]
问题解决
在spark-env.sh中增加如下参数:
SPARK_LOCAL_IP=LOCALHOST
执行spark-shell报org.apache.hadoop.ipc.RemoteException
问题描述
Exception in thread "main"org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException):Zero blocklocations for /mr/input/1.txt. Name node is in safe mode.
The reported blocks 0 needs additional 8blocks to reach the threshold 0.9990 of total blocks 8.
The number of live datanodes 2 has reachedthe minimum number 0. Safe mode will be turned off automatically once thethresholds have been reached.
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocationsInt(FSNamesystem.java:1880)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocations(FSNamesystem.java:1853)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.getBlockLocations(FSNamesystem.java:1825)
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getBlockLocations(NameNodeRpcServer.java:565)
atorg.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.getBlockLocations(AuthorizationProviderProxyClientProtocol.java:87)
atorg.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getBlockLocations(ClientNamenodeProtocolServerSideTranslatorPB.java:363)
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1060)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2086)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2082)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1671)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2080)
at org.apache.hadoop.ipc.Client.call(Client.java:1472)
at org.apache.hadoop.ipc.Client.call(Client.java:1403)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:230)
at com.sun.proxy.$Proxy19.getBlockLocations(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getBlockLocations(ClientNamenodeProtocolTranslatorPB.java:254)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
atsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
atsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
atorg.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:252)
atorg.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:104)
at com.sun.proxy.$Proxy20.getBlockLocations(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.callGetBlockLocations(DFSClient.java:1258)
atorg.apache.hadoop.hdfs.DFSClient.getLocatedBlocks(DFSClient.java:1245)
atorg.apache.hadoop.hdfs.DFSClient.getBlockLocations(DFSClient.java:1303)
atorg.apache.hadoop.hdfs.DistributedFileSystem$1.doCall(DistributedFileSystem.java:220)
atorg.apache.hadoop.hdfs.DistributedFileSystem$1.doCall(DistributedFileSystem.java:216)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
atorg.apache.hadoop.hdfs.DistributedFileSystem.getFileBlockLocations(DistributedFileSystem.java:216)
atorg.apache.hadoop.hdfs.DistributedFileSystem.getFileBlockLocations(DistributedFileSystem.java:208)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:228)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:207)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
atorg.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
atorg.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
atorg.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.Partitioner$.defaultPartitioner(Partitioner.scala:65)
atorg.apache.spark.rdd.PairRDDFunctions$$anonfun$reduceByKey$3.apply(PairRDDFunctions.scala:290)
atorg.apache.spark.rdd.PairRDDFunctions$$anonfun$reduceByKey$3.apply(PairRDDFunctions.scala:290)
atorg.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:147)
atorg.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:108)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:306)
atorg.apache.spark.rdd.PairRDDFunctions.reduceByKey(PairRDDFunctions.scala:289)
at scala.wordcount$.main(wordcount.scala:18)
at scala.wordcount.main(wordcount.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
atsun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
atsun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
atorg.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:672)
atorg.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:205)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:120)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
问题解决
有两个方法离开这种安全模式
1. 修改dfs.safemode.threshold.pct为一个比较小的值,缺省是0.999。
2. hadoopdfsadmin -safemode leave命令强制离开
参考资料
http://www.cnblogs.com/gaopeng527/p/4366505.html