java高并发-并行模式(下).md
高性能的生产者-消费者:无锁的实现
在上文中,BlockingQueue用于实现生产者-消费者,其作为生产者和消费者的内存缓冲区,目的是为了方便共享数据,但BlockigQueue并不是一个高性能的实现,它完全使用锁和阻塞来实现线程间的同步,在高并发的场合下,它的性能不是很优越,ConcurrentLinkedQueue是一个高性能的队列,其秘诀在于大量使用了无锁的CAS操作;
阻塞方式是指:当试图对文件描述符进行读写时,如果当时没有东西可读,或者暂时不可写,程序进入等待状态,直到所有东西可读可写为止;
非阻塞方式是指:如果没有东西可读,或者不可写,读写函数马上返回,而不会等待;
剖析ConcurrentLinkedQueue
ConcurrentLinkedQueue类用于实现高并发的队列,这个队列使用链表作为其数据结构,作为一个链表,需要定义有关链表的节点,在ConcurrentLinkedQueue中,定义的节点Node核心如下:
private static class Node<E>{volatile E item;volatile Node<E> next;}
其中item是用来表示目标元素,字段next表示当前Node的下一个元素,这样的每个Node就能环环相扣了,下图是ConcurrentLinkedQueue的基本结构。
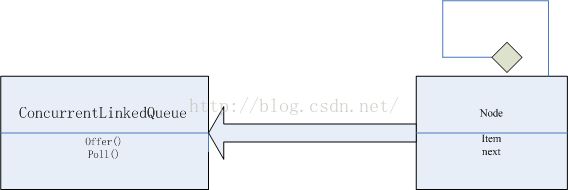

其中的offer()起了添加元素的作用,poll()的起了获取但不移除队列的头,如果队列为空,则返回null。
- CAS(compare and swap)操作的基本原理:有3个操作数,内存值为V,旧的预期值为A,要修改的新值为B,当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。但是利用CAS操作来实现并行模式,难度较大,此时Disruptor框架,将会代替CAS操作来实现高性能的生产者-消费者。
无锁的缓存框架:Disruptor
Disruptor框架是一款高效的无锁内存队列,它使用无锁的方式实现了一个环形队列,在Disruptor中使用了环形队列(RingBuffer)来代替普通的线性队列,其内部实现为一个普通的数组。对于一般的队列,必须要提供队列同步head和尾部tail两个指针用于线程的出队和入队,这样明显增加了线程协作的复杂度,但是Disruptor框架实现了一个环形队列,这样就省去了一些不必要的麻烦,只需要对外提供一个当前位置position,利用这个指针既可以进入队列,也可以进行出队操作,由于队列是环形的,队列的总大小必须事先指定,不能动态扩展,为了快速从序列对应到数组的实际位置(每次有元素入队,序列加1)。
注意:Disruptor要求必须将数组的大小设置为2的整数次方,这样就能立即定位到实际的元素位置index;
Disruptor框架之所以应用广泛,究其原因在于其利用无锁的方式实现了一个环形队列,其好处表现在以下两个方面:
- 巧妙利用环形队列(RingBuffer)来代替普通线性队列,当生产者向缓冲区写入数据时,消费者则从中读取数据,生产者写入数据时,使用CAS操作,消费者读取数据时,为了防止多个消费者处理同一个数据,也使用CAS操作进行数据保护。
- RingBuffer的大小是固定的,可以做到完全的内存复用,在运行过程中,不会有新的空间需要分配或者老的空间需要回收,因此大大减少了系统分配空间以及回收空间的额外开销。
用Disruptor实现生产者-消费者案例
import java.nio.ByteBuffer;import java.util.concurrent.Executor;import java.util.concurrent.Executors;//代表数据的PCData1class PCData1{private long value;public void set(long value){this.value = value;}public long get(){return value;}}//消费者实现为WorkHandler接口,它来自Disruptor框架:class Consumer1 implements WorkHandler<PCData1>{public void onEvent(PCData1 event) throws Exception{System.out.println(Thread.currentThread().getId()+":Event:--"+event.get()*event.get()+"--");}}//产生PCData1的工厂类,在Disruptor系统初始化时,构造所有的缓冲区中的对象实例class PCData1Factory implements EventFactory<PCData1>{public PCData1 newInstance(){return new PCData1();}}//生产者class Producer1{private final static RingBuffer<PCData1> ringBuffer;//创建一个RingBuffer的引用,即环形缓冲区;public Producer1(RingBuffer<PCData1> ringBuffer){//创建一个生产者的构造函数,将RingBuffer的引用作为参数传入到函数当中;this.ringBuffer = ringBuffer;}public static void pushData(ByteBuffer bb){//pushData作为RingBuffer的重要方法将数据推入缓冲区,接收一个ByteBuffer对象;long sequence = ringBuffer.next(); //得到一个可用的序列号/*java中的异常处理try{存放可能出现的异常}catch{处理异常}finally{清理资源,释放资源;}三种方法也可以组合在一起使用,其使用方法如下所示:1.try+catch:运行到try块中,如果有异常抛出,则转到catch块去处理。然后执行catch块后面的语句2.try+catch+finally:运行到try块中,如果有异常抛出,则转到catch块,catch块执行完毕后,执行finally块的代码,再执行finally块后面的代码。注意:如果没有异常抛出,执行完try块,也要去执行finally块的代码,然后执行finally块后面的语句;3.try+finally:运行到try块中,如果有异常抛出的话,程序转向执行finally块的代码。由此引发一个问题?就是程序是否会执行finall块后面的代码呢,结果是不会,因为没有处理异常,所以遇到异常后,执行完finally后,方法就已抛出异常的方式退出了。这种方法需要注意的是:由于你没有捕获异常,所以要在方法后面声明抛出异常;*/try{PCData event = ringBuffer.get(sequence);event.set(bb.getLong(0));}finally{ringBuffer.publish(sequence);}}}//生产者和消费者和数据已准备就绪,只差主函数将所有的内容整合起来;public static void main(String[] args) throws Exception{Executor executor = Executors.newCachedThreadPool();//调用线程池工厂Executors中newCachedThreadPool()的方法,该方法返回一个可以根据实际情况调整线程数量的线程池,线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。PCData1Factory factory = new PCData1Factory();int bufferSize = 1024;//设置缓冲区的大小;Disruptor<PCData1> disruptor = new Disruptor<PCData1>(factory,bufferSize,executor,ProducerType.MULTI,new BlockingWaitStrategy()); //创建disruptor对象,它封装了整个disruptor库的使用,提供了一些API,方便其他方法进行调用disruptor.handlerEventWithWorkerPool(//设置用于数据处理的消费者,设置了4个消费者实例;new Consumer1(),new Consumer1(),new Consumer1(),new Consumer1());disruptor.start();//启动并初始化disruptor系统RingBuffer<PCData1> ringBuffer = disruptor.getRingBuffer();Producer1 producer1 = new Producer1(ringBuffer);//创建了生产者类Producer1,将ringBuffer作为实例传入到生产者类中;ByteBuffer bb = ByteBuffer.allocate(8);//allocate()方法是用来说明ByteBuffer对象的容量大小,在ByteBuffer对象中可以用来包装任何数据类型,这里用来存储long型整数;for(long i = 0;true;i++){bb.putLong(0,i);Producer1.pushData(bb);Thread.sleep(100);System.out.println("add data"+i);//这部分的代码实际上是为了让生产者不断的向缓冲区中存入数据;}}}
- poll()和push()方法
poll方式,也称为轮循,是一种数据同步方式,客户端定期去ping查询服务器,确定是否有需要的数据,当服务器没有数据的时候,poll方式会浪费大量的带宽。为了降低带宽,通常采用减低poll的频率来实现的,这就导致了消息的长延迟,实时性不高。
push方式在大多数的情况下通信信道往往是单向的,为了解决poll的问题将其设计双向的,这样服务器就可以采用push方式主动向客户端进行数据同步,当前实现push的方法有两种:- 客户端首先连接到服务器,并维持长连接;
- 服务器能够直接访问到客户端,不需要长连接;
CPU Cache 的优化:解决伪共享问题
在上面提到Disruptor 使用CAS和提供不同的等待策略来提高系统的吞吐量,还尝试着解决CPU缓存的伪共享问题。
- 什么是伪共享模式?
为了提高CPU的速度,CPU有一个高速缓存Cache,在高速缓存中,读写数据最小的是缓存行(Cache Line),它是从主存(memory)复制到缓存(Cache)的最小单位,一般为32个字节到128字节。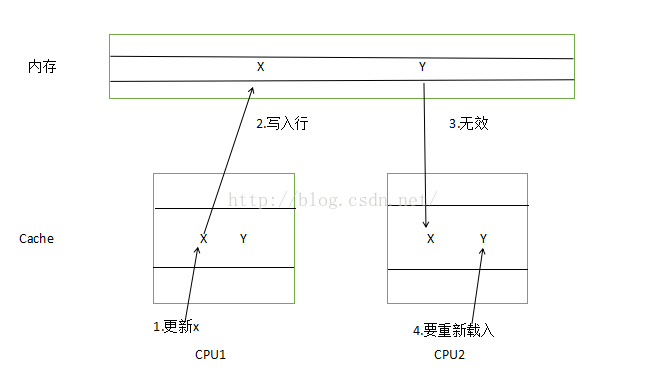 X和Y在同一个缓存行中
X和Y在同一个缓存行中
- 从上图可以看出,如果将两个变量放在同一个缓存行中,在多线程访问过程中,可能会互相影响彼此的性能。假设X和Y同在一个缓存行中,运行在CPU1上的线程更新了X,那么CPU2上的缓存行就会失效,同一行的Y即使没有被修改也会变成无效的,导致Cache无法命中,接着,如果在CPU2上的线程更新了Y,则导致CPU1上的缓存行失效,此时,同一行的X又变得无法访问,这样反复发生,使得CPU经常不能命中缓存,那么系统的吞吐量(指的是网络设备,端口,虚电路或其他设施,单位时间内成功地传递数据的数量,以比特,字节,分组等测量)会急剧下降。
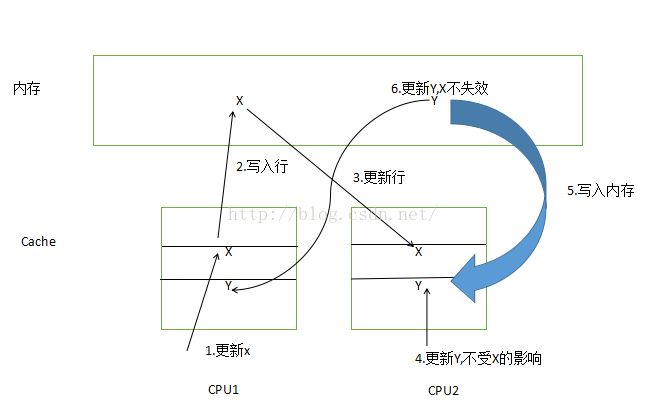
- 变量X和Y各占据一个缓冲行
public final class FalseSharing implements Runnable{public final static int NUM_THREADS = 1;//线程的数量是可变的;public final static long ITERATIONS = 500L*1000L*1000L;//设置迭代次数;private final int arrayIndex;private static VolatileLong[] longs = new VolatileLong[NUM_THREADS];//数组的元素个数和线程数量一致,每个线程都会访问自己对应的longs中的元素;static{for(int i= 0;i<longs.length;i++){//遍历数组;longs[i] = new VolatileLong();}}public FalseSharing(final int arrayIndex){this.arrayIndex = arrayIndex;}public static void main(final String[] args) throws Exception{final long start = System.currentTimeMillis();//获取当前的时间戳;runTest();System.out.println("duration = "+(System.currentTimeMillis() - start));}private static void runTest() throws InterruptedException {Thread[] threads = new Thread[NUM_THREADS];//限定线程的长度for(int i=0;i<threads.length;i++){threads[i] = new Thread(new FalseSharing(i));}for(Thread t : threads){//遍历线程数组,变量定义为t,这是java for循环的一种,将其翻译过来的是for(int i=0;it.join();/*join的字面意思是加入,即一个线程要加入另一个线程,那么最好的方法就是等着它一起走,1.public final void join() throws InterruptedException,第一个join()方法表示无限等待,它会一直阻塞当前线程,直到目标线程执行完毕;2.public final synchronized void join(long millis) throws InterruptedException ,第二个方法给出了一个最大的等待时间,如果超过给定时间目标线程还在执行,当前线程也会因为“等不及了 ”,而继续往下执行;*/}}public void run(){long i = ITERATIONS + 1; //定义i的变量值大小为迭代次数加1;while(0 != --i){longs[arrayIndex].value = i;}}public final static class VolatileLong{//本程序中最关键的点是VolatileLong,定义了7个long型变量用来填充缓存,使得变量不在一个缓存行中public volatile long value = 0L;// public long p1,p2,p3,p4,p5,p6,p7;}}
Disruptor框架充分了考虑了由于各个JDK版本内部实现不一致的问题,它的核心组件Sequence会被非常频繁的访问(每次入队,它都会被加1)其结构如下:
class LhsPadding{protected long p1,p2,p3,p4,p5,p6,p7;}class Value extends LhsPadding{protected volatile long value;}class RhsPadding extends Value{protected long p9,p10,p11,p12,p13,p14,p15;}public class Sequence extends RhsPadding{}
在Sequence中,主要使用的是value,但是,通过LhsPadddin和RhsPaddding,这个value的前后安置了一些占位空间,使得value可以无冲突的存在于缓存中。
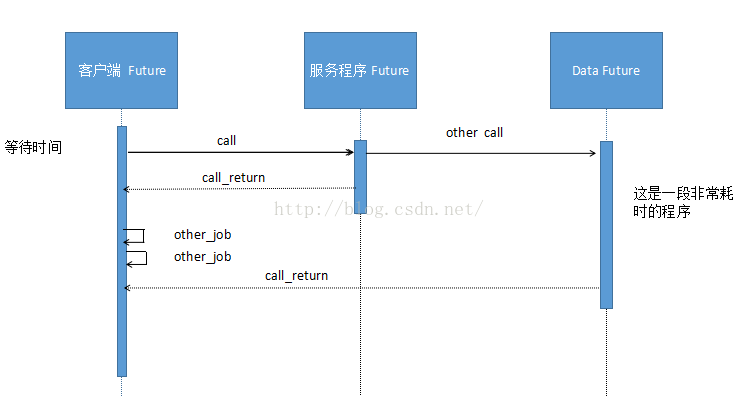
Future模式

从上图中可以看出,客户端发出call请求,这个请求需要相当一段时间才能返回,客户端一直在等待,直到数据返回,随后,再进行其他任务的处理。这样的话就存在一种弊端,有相当长的一段空闲时间,一直在等待。

Future模式的主要角色

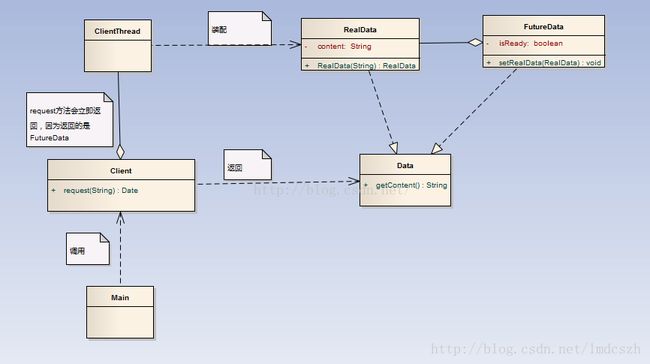


Future模式结构图
//Data数据interface Data{public String getResult();}//FutureData是Future模式的关键。它实际上是真实数据RealData的代理,封装了获取RealData的等待过程import javax.xml.crypto.Data;class FutureData implements Data{protected RealData realdata = null;protected boolean isReady = false;public synchronized void setRealData(RealData realdata){if(isReady){return;}this.realdata = realdata;isReady = true;notifyAll();}public synchronized String getResult(){while(!isReady){try{wait();}catch(InterruptedException e){}}return realdata.result;}}class RealData implements Data{protected final String result;public RealData(String para){//RealData的构造可能很慢,需要用户等待很久,这里使用sleep模拟;StringBuffer sb = new StringBuffer();for(int i =0;i<10;i++){sb.append(para);try{//这里使用sleep,代替一个很慢的操作过程;Thread.sleep(100);}catch(InterruptedException e){}}result = sb.toString();}public String getResult(){return result();}private String result() {// TODO Auto-generated method stubreturn null;}}//接下来是客户端程序,Client主要实现了获取FutureData,并开启构造RealData的线程,并在接受请求之后,很快的返回FutureData.//注意:它不会等待数据真的构造完毕再返回,而是立即返回FutureData,即使这个时候FutureData内并没有真实的数据class Client{public Data request(final String queryStr){final FutureData future = new FutureData();new Thread(){public void run(){RealData realdata = new RealData(queryStr);future.setRealData(realdata);}}.start();return future;}//主函数Main,主要负责调用Client发起请求,并消费要返回的数据;public static void main(String[] args){Client client = new Client();//这里会立即返回,因为得到的是FutureData而不是RealDataData data = client.request("name");System.out.println("请求完毕");try{//这里可以用一个sleep代替了对其他业务逻辑的处理;//在处理这些业务逻辑的过程中,RealData被创建;Thread.sleep(2000);}catch(InterruptedException e){}//使用真实数据;System.out.println("数据= "+ ((RealData) data).getResult());}}
JDK中的Future模式
JDK中的Future模式相比上文所讲的Future模式更加复杂,在这里我们先来向大家介绍一下它的使用方式。
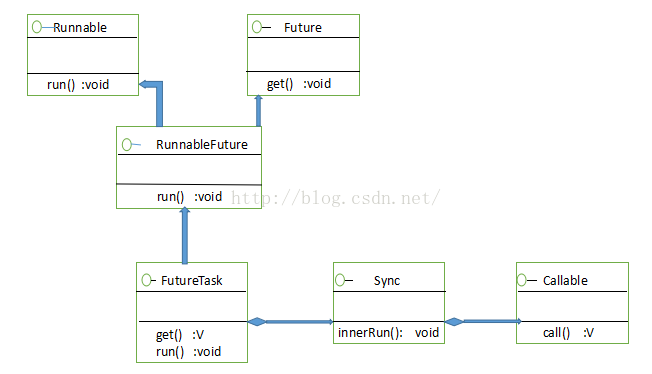

JDK内置的Future模式
从上图中可知,Future接口类似于前文中描述的订单或者契约。通过它,你可以得到真实的数据。RunnableFuture继承了Future和Runnable两个接口,其中run()方法用于构造真实的数据。它有一个具体的实现FutureTask类,FutureTask有一个内部类Sync,将一些实质性的工作交给内部类来实现,Sync类最终会调用Callable接口,完成实际数据的组装。
Callable接口只有一个方法call(),它会返回需要构造的实际数据,这个Callable接口也是Future框架和应用程序之间的重要接口,如果我们要实现自己的业务系统,通常需要实现自己的Callable对象。
import java.util.concurrent.Callable;import java.util.concurrent.ExecutionException;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.FutureTask;//上述代码实现了Callable接口,它的call()方法会构造我们需要的真实数据并返回,当然这个构造过程很缓慢,这里使用Thread.sleep()模拟它;class RealData1 implements Callable<String>{private String para;public RealData1(String para){this.para = para;}public String call() throws Exception{StringBuffer sb = new StringBuffer();for(int i = 0;i<10;i++){sb.append(para);try{Thread.sleep(100);}catch(InterruptedException e){}}return sb.toString();}}//以下代码是使用Future模式的典型,public class FutureMain {public static void main(String[] args) throws InterruptedException,ExecutionException{//构造FutureTaskFutureTask<String> future = new FutureTask<String>(new RealData1("a"));//构造Future对象实例,表示这个任务有返回值。在构造FutureTask时,使用Callable接口,告诉FutureTask我们需要的数据是如何产生的。ExecutorService executor = Executors.newFixedThreadPool(1);//执行FutureTask,相当于上例中的client.request("a")发送请求//在这里开启线程进行RealData的call()执行executor.submit(future);//将FutureTask提交给线程池,显然,作为一个简单的任务提交,在此会立即返回的,因此程序不会阻塞System.out.println("请求完毕");try{//这里依然可以做额外的数据操作,这里使用sleep代替其他业务逻辑的处理Thread.sleep(2000);}catch(InterruptedException e){}//相当于在data.getResult(),取得call()方法的返回值//如果此时call()方法没有执行完成,则会依然等待System.out.println("数据 = "+future.get());//在需要数据时,利用future.get()得到实际的数据;}}