YOLOV3的三个门限值解释以及yolov3详解
YOLOV3
关于yolov3必须了解的三个门限值
ignore_iou_thresh:【IOU门限】标记与真实框有交集的锚框的objectness(框内是否有物体)为1还是-1的分界线
yolov3是对生成的每个锚框进行标记
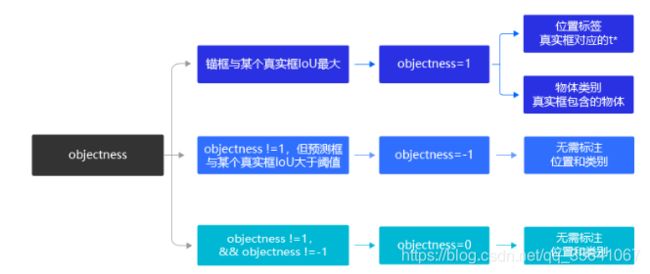
标记与真实框IOU最大的锚框objectness=1【只有该锚框对应的预测框才参与损失函数计算和类别预测】
标记与真实框的非最大但IOU大于等于ignore_iou_thresh的锚框的objectness=-1表示是真实框对应的锚框(锚框包含真实目标),但其对应的预测框不负责损失函数计算和类别预测
其他锚框统一标记objectness=0表示锚框不包含真实目标【俗称负样本/背景】,其对应的预测框不负责损失函数计算和类别预测
objectness!=0锚框对应的目标称为正样本(前景)
score_thresh:[置信度门限]:表示进行预测时被保留的预测框应该达到的置信度门限值
注:yolov3的置信度(score)与其他two-stage检测器不同,yolov3置信度表示对于此预测框有多大把握此框内包含物体且分类正确,而two-stage检测器只表示有多大把握分类正确
YOLOV3类别置信度 = 条件类别概率 * 置信度
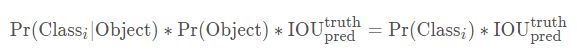
nms_iou_thresh:[IOU门限]进行nms筛选预测框,去掉预测同一物体重复框的阈值
在进行nms时,会先对同类的预测框按score从大到小排序然后筛选该类所有物体的真实框,但是如何知道预测框是预测同一物体还是不同物体呢?具体方法是对于每个真实物体先挑选score最高的作为自身的最终预测框,而对于那些与最终预测框的IOU>=nms_iou_thresh则会当作预测该物体的重复框(对同一物体重复预测),然后被排除
生成锚框与预测框
锚框:yolov3产生锚框的方式不同于two_stage检测器的随机生成锚框的方式,而是将一张图片划分成m*n个小方格,每个小方格生成k个(默认k=3)以每个小方格的中心为中心的不同大小的锚框【k个锚框就是k种大小】
预测框: 每个锚框对应一个预测框,但是只有objectness=1的锚框对应的预测框计入损失函数和进行分类判别
对于一张图片会生成 m ∗ n ∗ k m*n*k m∗n∗k个锚框/预测框,其中objectness=1的锚框数等于真实框的个数
如何由锚框(xywh格式)生成预测框
预测框相当于锚框的一个微调量,设预测框相对于锚框的微调量表示为 ( t x , t y , t w , t h ) (t_x,t_y,t_w,t_h) (tx,ty,tw,th)
1.求出锚框的中心坐标 ( c x , c y ) (c_x,c_y) (cx,cy),在此锚框中心的基础偏移一定量得到预测框中心 ( b x , b y ) (b_x,b_y) (bx,by)

2.利用预设定好的锚框大小 ( p w , p h ) (p_w,p_h) (pw,ph)求出预测框的大小 ( b h , b w ) (b_h,b_w) (bh,bw)


如何学习定位(回归任务):
目标: 预测框的坐标与真实框的坐标一样
如何表示真实框: 把上述预测框当作真实框 ( g t x ∗ , g t y ∗ , g t w ∗ , g t h ∗ ) (gt^*_x,gt^*_y,gt^*_w,gt^*_h) (gtx∗,gty∗,gtw∗,gth∗),反解出真实框对于锚框的微调量 ( t x ∗ , t y ∗ , t w ∗ , t h ∗ ) (t^*_x,t^*_y,t^*_w,t^*_h) (tx∗,ty∗,tw∗,th∗)

而定位准确的目标,就是以预测微调量 ( t x , t y , t w , t h ) (t_x,t_y,t_w,t_h) (tx,ty,tw,th)与真实微调量 ( t x ∗ , t y ∗ , t w ∗ , t h ∗ ) (t^*_x,t^*_y,t^*_w,t^*_h) (tx∗,ty∗,tw∗,th∗)之间的差距缩小为目标进行回归任务
在实际任务中由于sigmoid函数的反函数不好求解,输出的预测变量为 ( σ ( t x ) , σ ( t y ) , σ ( t w ) , σ ( t h ) ) (\sigma (t_x),\sigma (t_y),\sigma (t_w),\sigma (t_h)) (σ(tx),σ(ty),σ(tw),σ(th)),目标变为 ( d x ∗ , d y ∗ , d w ∗ , d h ∗ ) (d^*_x,d^*_y,d^*_w,d^*_h) (dx∗,dy∗,dw∗,dh∗)

对锚框进行标记,确定负责预测真实物体的锚框
此部分可参考 ignore_iou_thresh的讲解
负责预测真实物体的锚框数(预测框数)等于真实物体数
YOLOV3的网络
1.YOLOV3的基础网络
YOLOV3网络用的Darknet(原版是53层训练在Imagenet的网络)。YOLOV3对YOLOV2的darknet进行改进,加入多尺度,残差块,跳跃连接以及上采样的功能。YOLO v3整体是一个106层的全卷积网络,包括了残差模块,上采样模块,检测模块。关于106层的全结构,[请参考这篇文章]
(https://blog.csdn.net/dpengwang/article/details/85839652)

2.传给检测模块的输入
在具体讲解网络之前,有一个问题要解决,就是传入检测模块的输入。设每个格子对应B个锚框(Bounding box),每个锚框对于一个预测框,每个预测框有三个属性坐标位置微调量,框内是否包含物体,类别,对于coco数据集(类别80类)来说,对于每个格子三个锚框的设置,则一个格子的属性维度为BX(5+C)=3X(5+80)=255维.
这255维对于网络来说就是255个通道,然后每个通道的特征图大小(mm)对应原图划分为mm格子(即每个特征图的像素点对应原图的一个格子)

3.三种尺度的检测网络
以416*416的输入图像,3个锚框,coco8类(即每个格子255维属性)为例,
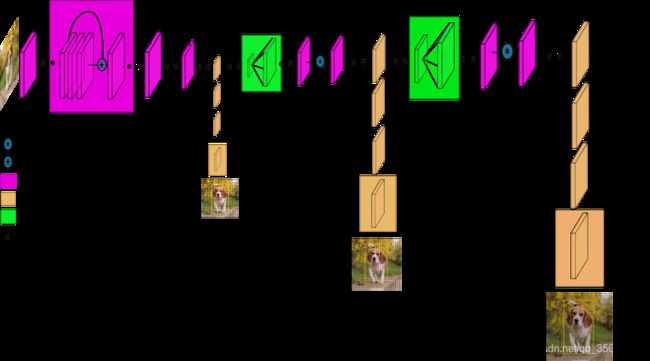
尺度1: yolov3提取第81层 的网络输出做为第一个尺度的检测网络的输入,81层 网络采用1x1的kernel得到检测特征层(82层)(13x13x255),整个下采样的步长为32(416/32=13)
尺度2: 第79层 的网络输出经过几个卷积操作,然后进行2X的上采样特征图至26x26的大小,上采样的特征图和第61层的特征图进行通道拼接操作,再进行几个卷积操作得到93层,93层 网络采用1x1的kernel得到检测特征层(94层)(26x26x255),整个下采样的步长为16(416/16=26)
尺度3: 第91层 的网络输出经过几个卷积操作,然后进行2X的上采样特征图至52x52的大小,上采样的特征图和第36层的特征图进行通道拼接操作,再进行几个卷积操作得到105层,105层 网络采用1x1的kernel得到检测特征层(106层)(52x52x255),整个下采样的步长为52(416/8=52)
尺度1用于检测大目标,尺度2用于检测中目标,尺度3用于检测小目标
YOLOV3的损失函数
YOLO v3相对于YOLOv2损失函数的改进:
1.类别没有用softmax,而是用logistic regression对每个类别都进行二分类
2.框内是否包含物体的置信度的预测,改为用logistic regression预测进行输出
3.去掉v2的 λ c o o r d 和 λ n o o b j \lambda_{coord}和\lambda_{noobj} λcoord和λnoobj参数

注意此处总的loss为三个scale的总loss的之和

YOLOV3的预测方法
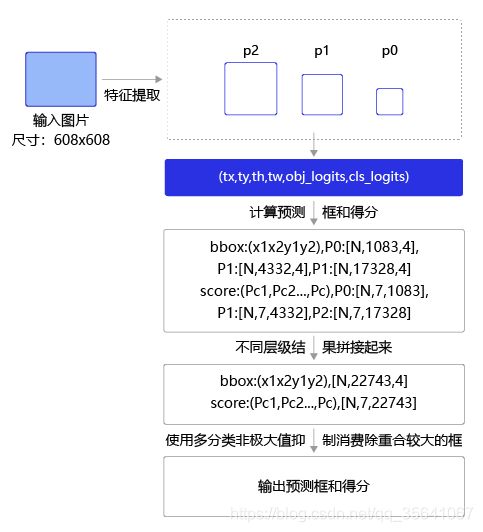
其实此预测方法并非yolov3专属,是当前目标检测通用的方法——非极大值抑制NMS
NMS的步骤
1.设定score_thresh,nms_iou_thresh
2.对每个类别分别从高到低的对每个预测框的score排序,过滤score
4.所有类别重复步骤3即完成预测
注意此处得到的所有预测框来自三个scale的预测框的总和
本文参考
paddle_yolov3
什么是yolov3