代码小白也能学会的爬虫软件——Webscraper基本介绍
今天分享一个依附于Chrome浏览器的爬虫软件——Webscraper(个人感觉比八爪鱼好用一些,而且所占内存2M不到!)
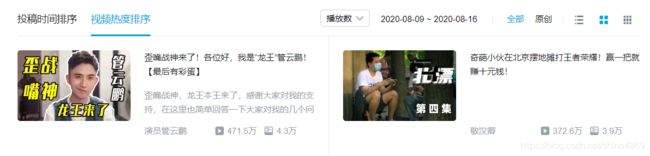
爬取内容:B站生活区的热门视频名称、UP主名、播放量、弹幕数
将webscraper添加至Chrome扩展程序后,打开需要爬取的网页,使用检查功能即可看到webscraper的标识。其基本步骤如下所示。
基本步骤
-
-
- 1、创建sitemap
- 2、选取爬取内容
- 3、导出数据
-
1、创建sitemap
由于我们需要爬取多页数据,这里首先对URL进行分析
![]()
![]()
不难看出,图中数字的变化则反映出页数的变化,因此创建如下sitemap(当然,如果有现成的sitemap,即可直接导入)


Start URL为:https://www.bilibili.com/v/life/funny/?spm_id_from=333.5.b_6c6966655f66756e6e79.29#/all/click/0/[1-10]/2020-08-09,2020-08-16
注意:这里的[1-10]则表明爬取第1-10页网页数据,默认步长为1。若某些网页呈现的变化规律步长为n,可修改为[1-10:n]
2、选取爬取内容
爬取路线:
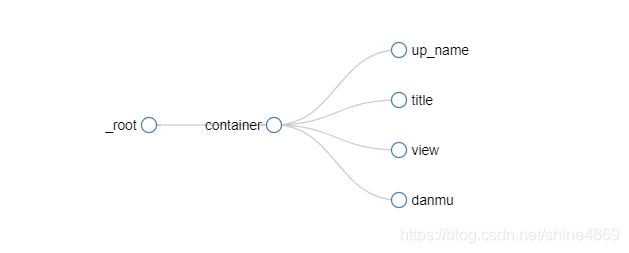
(1)添加选择器selector

(2)由于需要爬取多个内容,这里先创建Element对象(相当于一个容器,存储爬取的内容,否则只能分开爬取各个部分)
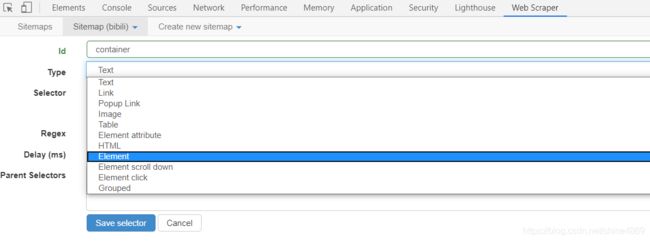
(3)勾选Multiple(可爬取多个),选中第一、二个视频区域(注意需要将爬取内容都包括)后,它会自动选取所有相同的区域,最后点击Done Selecting。

保存后的选择器如下所示:

(4)继续点击添加选择器,依次选取爬取的内容
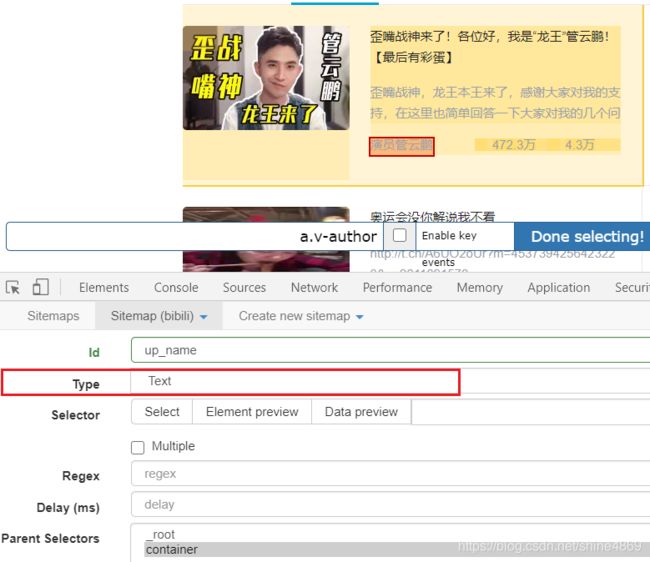
注意:此时Type选择的为Text,不用勾选Multiple(因为之前已经勾选过,此时选取我们需要爬取的内容如UP主名,会显示如上样式。)
按照,同样的方式,选择视频名称、播放量、弹幕数添加选择器,如下所示

3、导出数据
勾选Scrape,即可开始爬取。完成后点击Export data as CSV即可导出数据

Sitemap如下所示,可以直接import Sitemap
{
"_id":"bibili",
"startUrl":"https://www.bilibili.com/v/life/funny/?spm_id_from=333.5.b_6c6966655f66756e6e79.29#/all/click/0/[1-10]/2020-08-09,2020-08-16",
"selectors":[{
"parentSelectors":
["_root"],"type":"SelectorElement","multiple":true,"id":"container","selector":"div.l-item","delay":""},{
"parentSelectors":
["container"],"type":"SelectorText","multiple":false,"id":"up_name","selector":"a.v-author","regex":"","delay":""},{
"parentSelectors":
["container"],"type":"SelectorText","multiple":false,"id":"title","selector":"a.title","regex":"","delay":""},{
"parentSelectors":
["container"],"type":"SelectorText","multiple":false,"id":"view","selector":"span.v-info-i:nth-of-type(1) span","regex":"","delay":""},
{
"parentSelectors":
["container"],"type":"SelectorText","multiple":false,"id":"danmu","selector":"span.v-info-i:nth-of-type(2) span","regex":"","delay":""}]}
软件地址如下:
链接:https://pan.baidu.com/s/1t4uyU79Q1n916WPcVI88zA
提取码:a62n