大数据:缓慢变化维
前言
在业务场景中有很多维度表,这些维度表并不是一成不变的,一些不在乎历史数据的维度表当数据发生变化时,仅需要直接覆盖即可。但是如果需要保存历史记录,那么可以添加两个字段来表明该条维度数据的有效时间:一个开始时间和一个结束时间。还可以添加一个标识符来表明数据是否是最新的维度数据。
因为HDFS的不可修改数据的特性,hive和spark-sql不能像传统数据库一样使用update修改数据的。通常对于变化的数据,可以使用拉链表的方案来应对,但是维度表的数据量往往不大,多则几十万条,少则几条,使用拉链表不免杀鸡用牛刀。
所以,对于变化的维度表,通常使用缓慢变化维的方式解决。
思路
更新思路
当某天新的数据从DWD层导入到DWS层时,两处的数据可以分为五种情况:
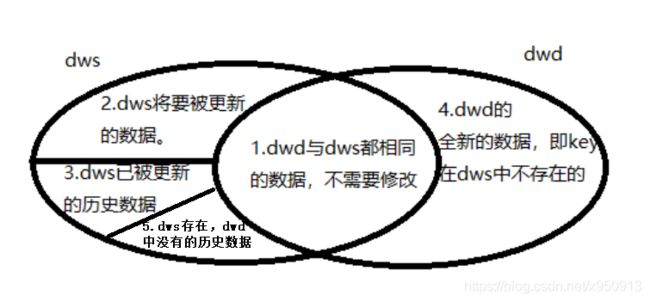
如上图,假设主键为key,在dwd和dws中分为如下五种情况:
- dwd与dws中最新的数据完全相同,不需要修改。
- dwd与dws中最新的数据不同,将dws中的数据设为过期数据,并将dwd的数据插入dws。
- dws中已过期的数据,原封不动保存回dws。
- dwd中新增的数据,即key在dws中不存在的数据,插入dws。
- dws中存在,但dwd本次不包含这部分数据,原封不动保存回dws。
举个栗子:
dws存在以下数据:
| key | data | start_date | end_date | is_current_flag |
| 1 |
a | 2020-08-01 | 9999-12-31 | 1 |
| 2 | b | 2020-08-01 | 9999-12-31 | 1 |
| 3 | c | 2020-08-01 | 2020-08-14 | 0 |
| 3 | d | 2020-08-15 | 9999-12-31 | 1 |
当日(假设为2020-08-26)的dwd的数据:
| key | data |
| 2 | b |
| 3 | e |
| 4 | f |
当天合并后的dws表数据应为:
| key | data | start_date | end_date | is_current_flag | 备注 |
| 1 | a | 2020-08-01 | 9999-12-31 | 1 | 情况5 |
| 2 | b | 2020-08-01 | 9999-12-31 | 1 | 情况1 |
| 3 | c | 2020-08-01 | 2020-08-14 | 0 | 情况3 |
| 3 | d | 2020-08-15 | 2020-08-25 | 0 | 情况2 |
| 3 | e | 2020-08-26 | 9999-12-31 | 1 | 情况2 |
| 4 | f | 2020-08-26 | 9999-12-31 | 1 | 情况4 |
解析:
key 1 :原先就存在dws层中,且本次dwd更新数据中不包含key为1的数据,所以将这条数据原封不动保存在dws层。
key 2 :原先就存在dws层中,但是本次dwd更新数据中的key为2的数据内容与dws的完全一致,所以不需要修改,原封不动保存在dws层。
key 3 : data为c的数据,is_current_flag字段的值为0,表明这条数据本就属于历史数据,将其原封不动保存在dws中;data为d的数据,dws中is_current_flag为1,但是dwd中存在key也为3的数据,且data与dws的这条数据不同,说明dws的这条数据即将被更新,所以将这条数据的end_date置为昨天的时间,且将is_current_flag置为0;data为e的数据,在dwd中,且与dws中key为3且is_current_flag为1的那条数据不同,将dwd的这条数据插入dws,并将start_date置为今日的时间,end_date为最大时间,is_current_flag为1.
key 4 :在dws中不存在key为4的数据,说明这是一条全新的维度记录,将其插入到dws,并将start_date置为今日的时间,end_date为最大时间,is_current_flag为1.
判断数据不同的方法
如上,缓慢变化维的实现需要判断key相同的情况下,其他字段是否相同。如果只有少量字段,可以用case when进行判断是否一致,可是如果有几百个字段呢?
考虑用md5或hash对除了key和star_date、end_date、is_current_flag以外的所有字段进行计算,比较计算结果即相当于比较所有字段是否一致。
我选择使用hash,因为md5在对null值进行计算时,每次的结果都不一致,如果数据中存在null值,则无法判断数据是否一致。
但是使用hash也存在一定问题,最后会说。
实现
准备数据
建表
create table ldltmp.test_scd_dwd
(
id int,
name string
)
stored as parquet;
create table ldltmp.test_scd_dws
(
id int,
name string,
start_date string,
end_date string,
is_current_flag tinyint
)
stored as parquet;
create table ldltmp.test_scd_dws_bak
(
id int,
name string,
start_date string,
end_date string,
is_current_flag tinyint
)
PARTITIONED BY (scd_date string)
stored as parquet;插入数据
INSERT OVERWRITE TABLE ldltmp.test_scd_dwd
SELECT 1, 'a1'
UNION ALL
SELECT 2, 'b4'
UNION ALL
SELECT 3, 'c1'
UNION ALL
SELECT 4, 'd'
UNION ALL
SELECT 5, 'e'
UNION ALL
SELECT 7, 'g'
INSERT OVERWRITE TABLE ldltmp.test_scd_dws
SELECT 1, 'a', '2020-01-01', '9999-12-31', 1
UNION ALL
SELECT 2, 'b', '2020-01-01', '2020-01-07', 0
UNION ALL
SELECT 3, 'c', '2020-01-01', '9999-12-31', 1
UNION ALL
SELECT 4, 'd', '2020-01-01', '9999-12-31', 1
UNION ALL
SELECT 6, 'f', '2020-01-01', '9999-12-31', 1
UNION ALL
SELECT 2, 'b1', '2020-01-08', '9999-12-31', 1代码实现
将dws的数据全部取出来,创建成视图dws。
计算dwd的数据,并创建成视图dwd。
将视图dws和dwd做inner join,关联条件为dws.id=dwd.id且dws.hash_all <> dwd.hash_all且dws.is_current_flag = 1。将关联结果中dwd的数据加上start_date等三个字段创建成dws_modify视图,表示dws中这些key即将被更新后的数据。
另外,由于这个维度表不是分区表,每次都全量刷全表,如果一次数据错误,那之前的历史记录也不可靠了。所以,用一个备份表来保存每天的数据,备份表以天为分区,当维度表被更新时,同时将更新后的数据写入备份表的当天的分区内,为保证两部分数据同步的原子性,使用with as的方式将结果同时写入两张表。然后定期清理备份表一个月前的数据,这样当数据出现问题时,至少可以回溯到一个月内的数据状态。
--创建dws临时视图
CREATE OR REPLACE TEMPORARY VIEW dws
AS
SELECT *, HASH(`(id|start_date|end_date|is_current_flag)?+.+`) AS hash_all FROM ldltmp.test_scd_dws
;
--创建dwd临时视图
CREATE OR REPLACE TEMPORARY VIEW dwd
AS
SELECT *, HASH(`(id)?+.+`) AS hash_all FROM ldltmp.test_scd_dwd
;
--使用dws、dwd视图创建dws中将被修改的数据视图(dws和dwd中都有的,且dws中is_current_flag 为1,且数据内容不同的)
CREATE OR REPLACE TEMPORARY VIEW dws_modify
AS
SELECT dwd.`(hash_all)?+.+`, DATE_FORMAT(CURRENT_TIMESTAMP(), 'yyyy-MM-dd'), '9999-12-31' , 1
FROM dws INNER JOIN dwd ON dws.id = dwd.id AND dws.hash_all <> dwd.hash_all AND dws.is_current_flag = 1
;
WITH scd_table AS
(
--情况4
SELECT dwd.`(hash_all)?+.+`, DATE_FORMAT(CURRENT_TIMESTAMP(), 'yyyy-MM-dd'), '9999-12-31', 1
FROM dwd LEFT JOIN dws ON dwd.id = dws.id
WHERE dws.id IS NULL
UNION ALL
--情况1、情况3、情况5
SELECT dws.`(hash_all)?+.+`
FROM dws LEFT JOIN dws_modify ON dws.id = dws_modify.id
where dws_modify.id IS NULL OR is_current_flag = 0
UNION ALL
--情况2 dws
SELECT dws.`(end_date|is_current_flag|hash_all)?+.+`, DATE_FORMAT(DATE_SUB(CURRENT_TIMESTAMP(), 1), 'yyyy-MM-dd'), 0
FROM dws INNER JOIN dws_modify ON dws.id = dws_modify.id
WHERE dws.is_current_flag = 1
UNION ALL
--情况2 dwd
SELECT * FROM dws_modify
)
FROM scd_table
--写入维度表
INSERT OVERWRITE TABLE ldltmp.test_scd_dws SELECT *
--写入备份表
INSERT OVERWRITE TABLE ldltmp.test_scd_dws_bak SELECT *, DATE_FORMAT(CURRENT_TIMESTAMP(), 'yyyy-MM-dd')
;另外,应用以上代码时,只需要修改三个视图的代码即可,更新插入逻辑部分仅需要修改表名与关联键即可。
踩坑
当跑完一次数据后,维度表的数据为30+w条,测试相同数据重跑一次,因为数据完全相同,所以数据都应该不会修改,数据量应该不变,可是跑完之后数据量变成了60+w。整整翻了一倍。
取某个key,对比dws和dwd所有数据的hash值,发现数据完全相同的情况下,hash值竟然不同。
怀疑是数据类型不一致,导致对相同数据取hash时,结果不同。
如hash(5)和hash('5')的结果时不同的。
但是dwd从原表取的数据字段与dws的是一致的,猜测是经过join或sum等计算之后,在spark中转换成了string类型,在落表时才会再次转换成对应的数据类型。那么在建dwd视图时,先将非string类型的字段使用cast强制转换一下试试,如:
CREATE OR REPLACE TEMPORARY VIEW dwd
AS
SELECT *, HASH(`(material_code)?+.+`) AS hash_all
FROM
(
select
CASE WHEN core.material_code REGEXP '^[0-9]*$' then ltrim('0', core.material_code) else core.material_code end as material_code,
info.itemname as material_name_cn,
core.material_name_en as material_name_en,
......
cast(core.gross_contents as double) ,
cast(core.gross_weight as double) ,
cast(core.net_contents as double) ,
cast(core.net_weight as double) ,
core.industry_standard_description ,
cast(core.volume as double) ,
cast(core.material_height as double) ,
cast(core.material_length as double) ,
core.purchasing_valuekey ,
cast(core.material_width as double) ,
core.tax_classification_of_material ,
......
from ldldws.dim_core_material core
left join
(
...
)info
on CASE WHEN core.material_code REGEXP '^[0-9]*$' then ltrim('0', core.material_code) else core.material_code end = info.itemunitcode
--core join info
left join
(
...
)group
on core.material_group_code = group.material_group_code
--join group
...
...
...
;
结果hash值与dws的相同了,问题解决。