目标检测坐标信息txt文件转Pascal VOC XML 格式(仅包括对角框正矩形标注)
一、生成txt对应的xml文件
我们使用我们自己的数据集,关于航空车辆检测,来源VEDAI。
数据集txt与对应的图片如图1。
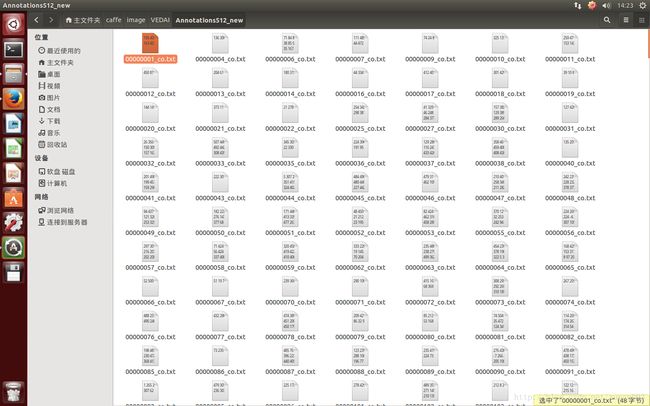

图1。txt与对应的图片
每一副图像所对应的txt里面的内容对应目标的坐标信息。如图2。文件格式为:xmin, ymin, xmax, ymax, label。
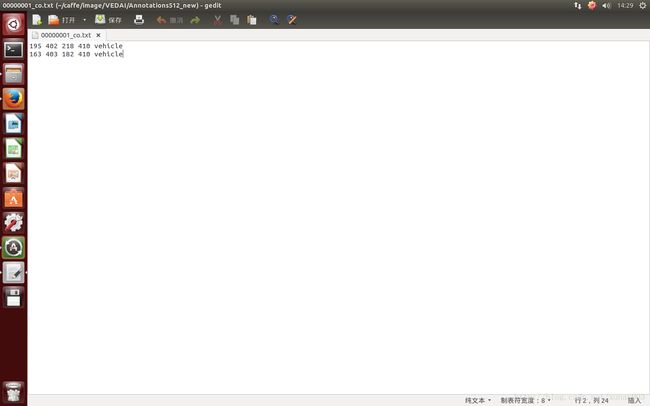
图2。txt内部信息。
将 txt 文件转换为 Pascal VOC 的 XML 格式的代码如下:
#! /usr/bin/python
# -*- coding:UTF-8 -*-
import os, sys
import glob
from PIL import Image
# VEDAI 图像存储位置
src_img_dir = "/home/xn/caffe/image/VEDAI/Vehicules1024_new"
# VEDAI 图像的 ground truth 的 txt 文件存放位置
src_txt_dir = "/home/xn/caffe/image/VEDAI/Annotations1024_new"
src_xml_dir = "/home/xn/caffe/image/VEDAI/Annotations1024_xml"
img_Lists = glob.glob(src_img_dir + '/*.png')
img_basenames = [] # e.g. 100.jpg
for item in img_Lists:
img_basenames.append(os.path.basename(item))
img_names = [] # e.g. 100
for item in img_basenames:
temp1, temp2 = os.path.splitext(item)
img_names.append(temp1)
for img in img_names:
im = Image.open((src_img_dir + '/' + img + '.png'))
width, height = im.size
# open the crospronding txt file
gt = open(src_txt_dir + '/' + img + '.txt').read().splitlines()
#gt = open(src_txt_dir + '/gt_' + img + '.txt').read().splitlines()
# write in xml file
#os.mknod(src_xml_dir + '/' + img + '.xml')
xml_file = open((src_xml_dir + '/' + img + '.xml'), 'w')
xml_file.write('\n')
xml_file.write(' VOC2007 \n')
xml_file.write(' ' + str(img) + '.png' + ' \n')
xml_file.write(' \n')
xml_file.write(' ' + str(width) + ' \n')
xml_file.write(' ' + str(height) + ' \n')
xml_file.write(' 3 \n')
xml_file.write(' \n')
# write the region of image on xml file
for img_each_label in gt:
spt = img_each_label.split(' ') #这里如果txt里面是以逗号‘,’隔开的,那么就改为spt = img_each_label.split(',')。
xml_file.write(' \n')
xml_file.write(' ')00000004_co.png 图像示例,其转换结果如下:

图3。xml内容示例。
二、转换对应的trainval.txt与test.txt
这一步,按照 SSD 训练的需求,将图像位置,及其对应的 XML 文件位置写入一个 txt 文件,供训练时读取,一个文件名称叫做:trainval.txt 文件,另一个叫做:test.txt 文件。形式如下:
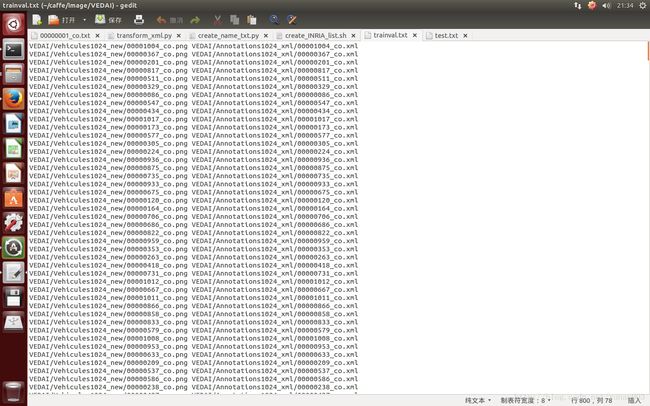
图4。trainval.txt。
生成的代码如下:
#! /usr/bin/python
# -*- coding:UTF-8 -*-
import os, sys
import glob
trainval_dir = "/home/xn/caffe/image/VEDAI/Vehicules1024_new/trainval"
test_dir = "/home/xn/caffe/image/VEDAI/Vehicules1024_new/test"
trainval_img_lists = glob.glob(trainval_dir + '/*.png')
trainval_img_names = []
for item in trainval_img_lists:
temp1, temp2 = os.path.splitext(os.path.basename(item))
trainval_img_names.append(temp1)
test_img_lists = glob.glob(test_dir + '/*.png')
test_img_names = []
for item in test_img_lists:
temp1, temp2 = os.path.splitext(os.path.basename(item))
test_img_names.append(temp1)
dist_img_dir = "VEDAI/Vehicules1024_new"
dist_anno_dir = "VEDAI/Annotations1024_xml"
trainval_fd = open("/home/xn/caffe/image/VEDAI/trainval.txt", 'w')
test_fd = open("/home/xn/caffe/image/VEDAI/test.txt", 'w')
for item in trainval_img_names:
trainval_fd.write(dist_img_dir + '/' + str(item) + '.png' + ' ' + dist_anno_dir + '/' + str(item) + '.xml\n')
for item in test_img_names:
test_fd.write(dist_img_dir + '/' + str(item) + '.png' + ' ' + dist_anno_dir + '/' + str(item) + '.xml\n')test_name_size.txt 的文件,里面记录训练图像、测试图像的图像名称、height、width。内容形式如下:
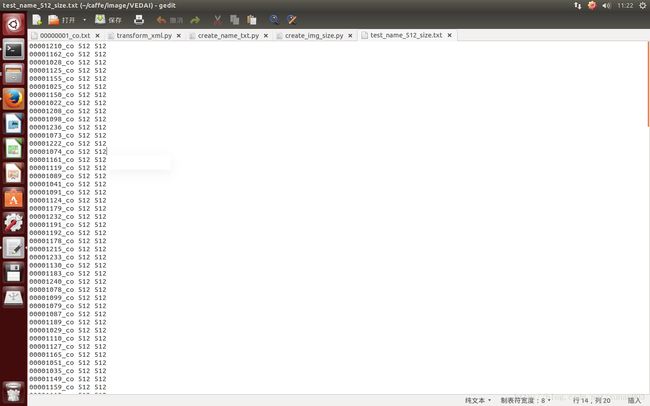
图5。test_name_size.txt文件内容。
生成这个文本文件的代码如下:
#! /usr/bin/python
import os, sys
import glob
from PIL import Image
img_dir = "/home/xn/caffe/image/VEDAI/Vehicules512_new/test/"
img_lists = glob.glob(img_dir + '/*.png')
test_name_size = open('/home/xn/caffe/image/VEDAI/test_name_512_size.txt', 'w')
for item in img_lists:
img = Image.open(item)
width, height = img.size
temp1, temp2 = os.path.splitext(os.path.basename(item))
test_name_size.write(temp1 + ' ' + str(height) + ' ' + str(width) + '\n')四、生成labelmap
这个 prototxt 文件是记录 label 与 name 之间的对应关系的,内容如下:
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "vehicule"
label: 1
display_name: "vehicule"
}这时候,需要修改调用 SSD 源码中提供的 create_data.sh 脚本文件(我将文件重命名为:create_VEDAI_data.sh):
代码如下,根据自己的路径与需求更改:
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
root_dir=/home/xn/caffe
cd $root_dir
redo=1
data_root_dir="$HOME/caffe/image"
dataset_name="VEDAI"
mapfile="$data_root_dir/VEDAI/labelmap_1024.prototxt"
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=png --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test_1024 trainval_1024
do
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/image/$dataset_name/$subset.txt $data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name
donebash 脚本会自动将训练的 ICDAR 2011 的图像文件与对应 label 转换为 lmdb 文件。转换后的文件位置可参见上面脚本的内容。
五、训练步骤请参看博主博文:点击打开链接