Python_数据分析_读写excel(1)
接触到爬虫之后,会发现数据量越来越大,在进行格式化数据清洗阶段就会出现很多的问题,因此用程序来进行数据清洗确实能节省很多的时间。处理excel文件分为读和写。分别用到xlrd和xlwt库。
1. 读文件
读Excel表主要用到xlrd,这个库用起来十分方便,可以直接将excel看做二位数组。
需要注意的是,在处理excel时,经常遇到excel单元格内出现多余的空格与Tab键,这种单元格处理起来不易发现,建议使用strip()函数进行处理,这样处理起来的效果比较理想。
import xlrd
def read_excel():
# 打开文件
work_url = r'C:\Users\lenovo\Desktop\10.内科_过敏反应科.xlsx'
workbook = xlrd.open_workbook(work_url)
# 获取所有sheet
print(workbook.sheet_names()) # [u'sheet1', u'sheet2']
# 根据sheet索引或者名称获取sheet内容
sheet1 = workbook.sheet_by_index(0) # 通过元组索引顺序获取
# sheet1 = workbook.sheet()[0] # 通过列表索引顺序获取
# sheet1 = workbook.sheet_by_name(u'sheet1') # 通过名称获取
# sheet的名称,行数,列数
print(sheet1.name, sheet1.nrows, sheet1.ncols)
# 获取整行和整列的值(数组)
rows = sheet1.row_values(3) # 获取第四行内容
cols = sheet1.col_values(2) # 获取第三列内容
print(rows)
print(cols)
# 获取单元格内容
print(sheet1.cell(1, 0).value)
if __name__ == '__main__':
read_excel()
2.写文件
前面介绍读excel相当于只读形式,能够从excel中提取出相应的内容但不能写入。写excel文件则需要使用xlwt库来进行。
import xlwt
workbook = xlwt.Workbook(encoding = 'ascii') # 实例化一个Workbook
worksheet = workbook.add_sheet('My Worksheet') # 创建一个工作薄
worksheet.write(0, 0, label = '1') # 填充数据
workbook.save('Excel_Workbook.xls') # 保存数据
上面的代码可以完成简单的excel的写操作,当需要进行更为复杂的操作时,也可以用xlwt来进行书写,比如合并单元格、设置表格样式等。下面给出一个更复杂的例子,如果需要进行复杂操作可以在使用时查阅库介绍。
import xlwt
#设置表格样式
def set_style(name,height,bold=False):
style = xlwt.XFStyle()
font = xlwt.Font()
font.name = name
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
#写Excel
def write_excel():
f = xlwt.Workbook()
sheet1 = f.add_sheet('学生',cell_overwrite_ok=True)
row0 = ["姓名","年龄","出生日期","爱好"]
colum0 = ["张三","李四","恋习Python","小明","小红","无名"]
#写第一行
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i],set_style('Times New Roman',220,True))
#写第一列
for i in range(0,len(colum0)):
sheet1.write(i+1,0,colum0[i],set_style('Times New Roman',220,True))
sheet1.write(1,3,'2006/12/12')
sheet1.write_merge(6,6,1,3,'未知')#合并行单元格
sheet1.write_merge(1,2,3,3,'打游戏')#合并列单元格
sheet1.write_merge(4,5,3,3,'打篮球')
f.save('test.xls')
if __name__ == '__main__':
write_excel()
可以得到以下结果:

3.向已有文件中进行写操作–一个具体实例
前面介绍了读操作和写操作,可以发现写操作时新建立excel表格进行写操作,那么如何像一个已有的文件中进行写操作。我们用一个实例来进行学习。
由于前面介绍了SnowNLP库(https://blog.csdn.net/weixin_44585839/article/details/90444593 ),因此相对商品评论进行情感分析,我使用爬虫对京东上的某商品下评论进行爬取,一共爬取350条评论,存储“京东商品评论”的excel中,局部截图如下:

在这里我希望从excel的第四列中(不包括第一行),取出评论并使用snownlp()函数进行分析,得到相关的情感系数并写入excel中。相关代码如下。
from xlrd import open_workbook
from xlwt import easyxf
from xlutils.copy import copy
import os
from snownlp import SnowNLP
url = r"C:\Users\lenovo\Desktop\Python\完整代码区\京东评论情感分析\京东商品评论.xlsx"
def nlp(work_url):
read_workbook = open_workbook(work_url)
write_workbook = copy(read_workbook)
sheet_read = read_workbook.sheet_by_index(0)
sheet_write = write_workbook.get_sheet(0)
sheet_write.write(0, 4, "sentiment")
line = sheet_read.nrows
for i in range(1, line):
txt = sheet_read.cell(i,3).value
sentiment = SnowNLP(txt)
sheet_write.write(i, 4, sentiment.sentiments)
os.remove(work_url)
write_workbook.save(work_url)
if __name__ == '__main__':
nlp(url)
经过运行,得到excel文件的效果为:
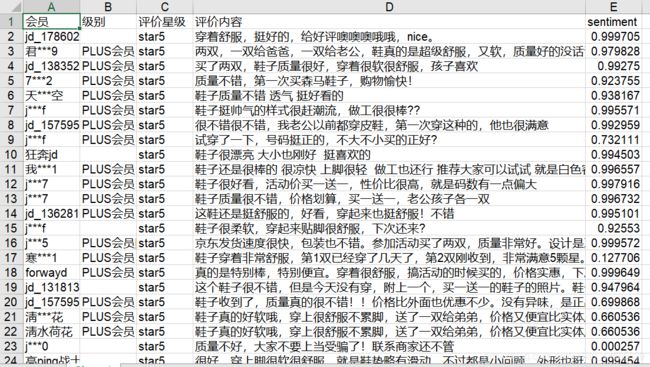
针对上述代码进行总结
- 该代码实现向已有文件中进行写操作时使用copy函数,将读操作的excel复制到写操作中,并用os将源文件删除,保存新的写操作中的文件
- 通过建立循环可以快速进行操作
- 在程序运行结束后,打开excel文件发现文件损毁。经过查阅(理解的不一定对),我使用的ms office为2016版本,文件拓展名为xlsx,而xlwt进行写操作后保留的excel文件为低版本文件,这里将文件的拓展名改为xls就可以打开。