Selenium配合chromedriver爬取网页pythonscraping.com/pages/javascript/ajaxDemo.html遇到的问题记录
1 介绍
Selenium是最初用于网站测试的工具,现在广泛用于网络爬虫。配合某个浏览器工具,其能自动加载网页,获取所需的数据,也能获取网页快照和判断某个事件是否在网站上发生。
利用urllib.request.urlopen、或者requests.get()等方法爬取网页有一个不适用的场景是:当网页是一个JavaScript驱动时。这时得到的是预加载的内容,而不是自己真正想要的内容。如果此时,我们用浏览器手工看到的网页内容,将会与爬取的html代码不一致。在这种情况下Selenium能大显身手。
Selenium的安装方法简单,在Python中用以下安装命令:
pip install selenium
其官方网站有对其使用方法的详细介绍讲解。Selenium本身是一个很好的爬虫工具,但其并不包含自身的Web浏览器,需要配合第三方浏览器使用。PhantomJS是一个无头浏览器(headless browser),它能够将网页加载到内存中,然后做各种有趣的事情。前几年它广泛配合Selenium使用,但最近Selenium已不推荐使用它了。在书籍《Web Scraping with Python: Collecting more data from the Modern Web》1的第二版的GitHub上公布的源代码已使用chromedriver作为第三方浏览器。chromedriver可以从其国内的镜像网站下载,我在win7电脑上安装的chrome版本为84.0.4147.135 (正式版本) (32 位) (cohort: Stable),所以我在该镜像网站上选取一个较为接近的版本,如下图:
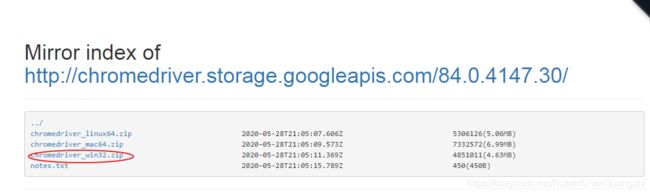
下载完成后,解压到Python项目的当前文件夹或其他路径,就可以配合Selenium使用了。
下面讲解书籍《Web Scraping with Python: Collecting more data from the Modern Web》1的第二版的GitHub上公布的源代码:
# ScrapeJavaScript.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(
executable_path='chromedriver',
options=chrome_options)
driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html')
time.sleep(3)
print(driver.find_element_by_id('content').text)
driver.close()
遇到的问题及相关解决过程。
2 相关问题及解决过程记录
问题1
运行上述代码,得到如下结果:
(.scenv) E:\StudyCard\WebScrape\WSwP2ed>python ScrapeJavaScript.py
DevTools listening on ws://127.0.0.1:6515/devtools/browser/88e3476a-7b6e-4e22-8b
b8-ff38a2e54cdc
This is some content that will appear on the page while it’s loading. You don’t
care about scraping this.
显然,根据书上的阐述,抓取返回的内容不对。经过试探,将代码改为(即删除代码行chrome_options.add_argument("--headless")):
# ScrapeJavaScript.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
driver = webdriver.Chrome(
executable_path='chromedriver',
options=chrome_options)
driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html')
time.sleep(3)
print(driver.find_element_by_id('content').text)
driver.close()
运行时,会自动弹出Chrome浏览器,如下图:

运行完后chrome浏览器会自动关闭。此时cmd中的运行结果为:
(.scenv) E:\StudyCard\WebScrape\WSwP2ed>python ScrapeJavaScript.py
DevTools listening on ws://127.0.0.1:6638/devtools/browser/9005ed67-d9d1-40cd-99
f0-99f106bc068d
[0823/092911.775:ERROR:gl_surface_egl.cc(699)] EGL Driver message (Error) eglQue
ryDeviceAttribEXT: Bad attribute.
[0823/092911.778:ERROR:gl_surface_egl.cc(699)] EGL Driver message (Error) eglQue
ryDeviceAttribEXT: Bad attribute.
[0823/092911.785:ERROR:gl_surface_egl.cc(699)] EGL Driver message (Error) eglQue
ryDeviceAttribEXT: Bad attribute.
[0823/092911.787:ERROR:gl_surface_egl.cc(699)] EGL Driver message (Error) eglQue
ryDeviceAttribEXT: Bad attribute.
[0823/092912.464:ERROR:gl_surface_egl.cc(699)] EGL Driver message (Error) eglQue
ryDeviceAttribEXT: Bad attribute.
Here is some important text you want to retrieve!
A button to click!
可以看出,我们爬取到了正确结果,但是在正确的文本信息前面出现了许多错误提示。
问题2 gl_surface_egl.cc(699)] EGL Driver message (Error) eglQueryDeviceAttribEXT: Bad attribute.错误信息的消除
通过在网上搜索相关的解决方案,stackoverflow网站上的帖子有解决方案,遂用之,增加一行代码chrome_options.add_argument('--disable-gpu'),如下:
# ScrapeJavaScript.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(
executable_path='chromedriver',
options=chrome_options)
driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html')
time.sleep(3)
print(driver.find_element_by_id('content').text)
driver.close()
cmd上的运行结果如下:
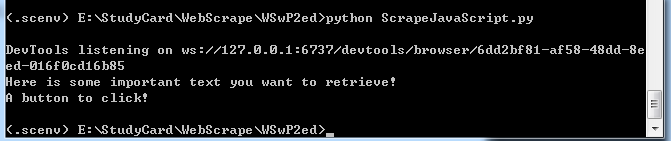
但此时会自动弹出chrome浏览器的运行界面,这样会延长时间。那么如何在headless模式得到正确的爬虫结果呢?
问题3 如何在headless模式得到正确的爬虫结果
经过分析,上述代码中的等待时间太短,我将等待时间改为5秒时,得不到正确结果。然后改为等待时间8秒,最终得到正确的爬虫结果。因为浏览器执行JavaScript时,需要一定的时间,若等待的时间不够,则页面仍然是预加载前的页面,当然得不到正确的结果。在headless模式下,能得到正确爬虫结果的代码如下:
# ScrapeJavaScript.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
chrome_options.add_argument("--headless")
#chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument('--disable-gpu')
driver = webdriver.Chrome(
executable_path='chromedriver',
options=chrome_options)
driver.get('http://pythonscraping.com/pages/javascript/ajaxDemo.html')
time.sleep(8)
print(driver.find_element_by_id('content').text)
driver.close()
cmd中的运行结果为:
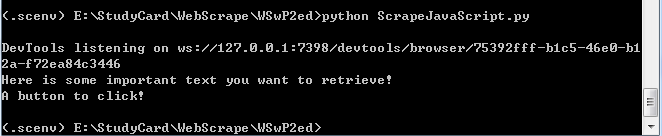
此时,Chrome浏览器也没自动化弹出、运行和关闭。
总结
爬虫技术牵涉的问题很多,在学习的时候要多思考。我们解决问题的时候,可能会引出另一个问题,这就需要我们保持一个渴望求知的状态,将出现的问题一个一个攻克,最终方能加深对问题的理解。
Ryan Mitchell. Web Scraping with Python: Collecting more data from the Modern Web. 2ed, O’Reilly, 2018. ↩︎ ↩︎