论文笔记21 -- (细粒度识别)Destruction and Construction Learning for Fine-grained Image Recognition
《Destruction and Construction Learning for Fine-grained Image Recognition 》
论文:点这里
Yue Chen1∗, Yalong Bai2∗, Wei Zhang3, Tao Mei4
JD AI Research, Beijing, China
有代码依然是件很关键的事情~
有代码!!! 点这里
我是在解决某个xx任务的时候接触到这个工作的,所以这篇paper还是得读一读的。这是京东AI研究院在细粒度图像识别FGVC Challenge 2019 (The Sixth Workshop on Fine-Grained Visual Categorization in CVPR 2019) 中的方法,该方法取得了2项冠军、1项亚军:
- First Place in iMaterialist Challenge on Product Recognition.
- First Place in Fieldguide Challenge: Moths & Butterflies.
- Second Place in iFood - 2019 at FGVC6.
该方法的主要思想是对原始输入图像分块并打乱,进而“破坏”掉图像中的结构信息,然后让网络学习破坏重组后的图像,强迫神经网络抓住重点视觉区域,增强网络对具有判别性局部细节的特征学习能力。
Abstract
关于目标局部(part)的精细特征表示在细粒度识别(fine-grained recognition)中起着至关重要的作用。例如,专家甚至可以根据专业知识,仅依靠目标的局部特征来区分细微差别的目标。
本文提出了一种新颖的“破坏与构造学习”(Destruction and Construction Learning,DCL)方法,以提高细粒度识别的难度,并使用分类模型来获取专家知识。除了标准分类骨干网之外,还引入了另一个“破坏与构造”分支,去“破坏”然后“重建”输入图像,以学习具有判别性的区域特征。
具体来说,对于“破坏”部分,首先将输入图像划分为局部区域,然后通过区域混淆机制(Region Confusion Mechanism,RCM)将其打乱。为了正确识别这些被破坏的图像,分类网络必须更加关注具有判别性的区域来发现差异。为了补偿RCM引入的噪声,使用了能够区分开原始图像和已破坏图像的对抗损失,来抑制RCM引入的噪声分布。
对于“构造”部分,使用了一个区域对齐网络,对打乱的局部区域之间的语义相关性进行建模,用于恢复局部区域的原始空间分布。通过参数共享的联合训练,DCL为分类网络注入了更多具有判别性的局部细节。
实验表明,文章提出的框架在三个标准数据集上均实现了最先进的性能。此外,该方法在训练中不需要任何外部知识,并且在前向推理时,除了标准分类网络外,没有其它计算开销。
1. Introduction
在过去的十年中,通过大规模标注数据和复杂模型设计的努力,通用目标识别取得了稳步进展。但是,识别精目标类别(例如,鸟类,汽车类型和飞机)仍然是一项很具有挑战性的任务,也引起了广泛的研究关注。 尽管差异细微的目标在视觉上粗略一瞥是相似的,但是可以通过具有判别性的局部区域细节来正确地识别。
从具有判别性的目标局部学习判别性特征表示在细粒度图像识别中起着关键作用。现有的细粒度识别方法可以大致分为两类:如图1所示,一种(a)首先定位具有判别性的目标局部区域,然后根据这些判别区域进行分类,这种方法通常需要在目标或目标局部上添加额外的边界框标注,成本较高。 另一种(b)试图通过注意力机制以无监督的方式自动定位判别性区域,因此不需要额外的标注。但是,这类方法通常需要额外的网络结构(例如,注意力机制),因此为训练和推理阶段引入了额外的计算开销。
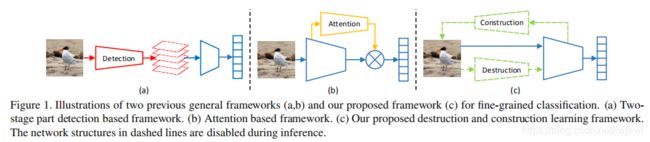
文中提出了一种新颖的细粒度图像识别框架,称为“破坏与构造学习”(DCL),如图1(c)所示。除了标准分类骨干网络,还引入了DCL分支来自动学习判别性区域。首先破坏输入图像以强调具有判别性的局部细节,然后对局部区域之间的语义相关性进行建模来重建图像。一方面,DCL会自动定位判别性区域,因此在训练时不需要额外的标注。另一方面,DCL结构仅在训练阶段采用,因此在推理时不会引入任何额外的计算开销。
对于“破坏”部分,提出了一种区域混淆机制(RCM)将输入图像划分为局部块然后洗牌,来故意“混淆”全局结构(图3)。细粒度识别中,局部细节比全局结构起着更重要的作用,因为来自不同细粒度类别的图像通常具有相同的全局结构或形状,仅在局部细节上不同。丢弃全局结构并保留局部细节可以迫使网络去关注具有判别性的局部区域。
洗牌也被使用在自然语言处理中,以使神经网络专注于判别词。类似地,如果图像中的局部区域( local regions)被“洗牌”,则对于细粒度识别的无关区域将被忽略,并且网络将被迫基于具有判别性的局部细节对图像进行分类。使用RCM,图像的视觉外观已发生实质性改变。如图3的底部所示,尽管识别起来变得更加困难,但鸟类专家仍然可以轻松地发现差异。汽车爱好者仅通过考察汽车部件就可以区分汽车类型。类似地,神经网络也需要学习专家知识以对破坏的图像进行分类。

需要注意的是,“破坏”并不总是有益的。RCM也引入了几种视觉噪声,如图3所示。为了抵消这种负面影响,采用对抗性损失来区分原始图像和被破坏图像。 结果是可以最小化噪声的影响,仅保留有益的局部细节。从概念上讲,对抗和分类损失是以对抗的方式工作,以从“破坏”中更细致的学习。
对于“构造”,引入了区域对齐网络(region alignment network)以恢复原始的区域分布,这与RCM的作用相反。通过学习恢复原始布局,网络需要理解每个区域的语义,包括那些具有判别性的区域。通过“构造”,可以对不同局部区域之间的相关性进行建模。
主要贡献概述如下:
- 提出了一种新颖的“破坏与构造学习(DCL)”框架,用于细粒度的识别。 对于破坏,区域混淆机制(RCM)迫使分类网络从判别性区域中学习,而对抗性损失则防止了过度拟合RCM导致的噪声模式。对于构造,区域对齐网络通过对区域之间的语义相关性进行建模来恢复原始区域布局。
- 在三个标准基准数据集上实现了最先进的性能,在这些数据集上DCL始终优于现有方法。
- 与现有方法相比,DCL不需要额外的部件/目标标注,并且在推理时不会引入任何计算开销。
2. Related works
细粒度图像识别任务的研究主要有两个方向。一种是直接从原始图像中学习更好的视觉表示,另一种是使用基于部件/注意力的方法来获取图像中的判别性区域并学习基于这些区域的特征表示。
…
3. Proposed Method
在本节中,介绍了破坏与构造学习(DCL)方法。 如图2所示,整个框架由四个部分组成。 请注意,推理时只需要“分类网络”。

3.1. Destruction Learning(破坏学习)
细节决定成败。对于细粒度图像识别,局部细节比全局结构重要得多。在大多数情况下,不同的细粒度类别通常具有相似的全局结构,且仅在某些局部细节上有所不同。本文工作通过打乱局部区域来小心地破坏全局结构,以更好地识别判别性区域并学习判别特征(第3.1.1节)。为了防止网络学习受到破坏全局结构而引入的噪声模式,提出了对抗性损失(第3.1.2节),以抑制RCM引入的噪声模式。
3.1.1 Region Confusion Mechanism(区域混乱机制)
与自然语言处理类似,将句子中的单词混排会迫使神经网络专注于判别性单词,而忽略无关单词。同样,如果图像中的局部区域被“洗牌”,则神经网络将被迫从具有判别性的区域细节中学习。
如图3所示,RCM旨在破坏图像局部区域的空间分布。给定输入图像 I \ I I,首先将图像均匀地划分为 N × N \ N×N N×N个子区域,每个子区域由 R i , j \ R_{i,j} Ri,j 表示,其中 i , j \ i, j i,j 分别是水平和垂直索引, 1 ≤ i , j ≤ N \ 1≤i, j≤N 1≤i,j≤N。RCM将这些分块的局部区域在它们的2D邻域中进行了洗牌。对于 R \ R R的第 j \ j j行,将生成一个长度为 N \ N N的随机向量 q j \ q_j qj,其中第 i \ i i个元素 q j , i = i + r \ q_{j,i}=i+r qj,i=i+r, 其中 r 〜 U ( − k , k ) \ r〜U(-k,k) r〜U(−k,k)是在 [ − k , k ] \ [-k,k] [−k,k]范围内遵循均匀分布的随机变量。这里 k \ k k是定义邻域范围的可调参数 ( 1 ≤ k < N ) \ (1≤k
∀ i ∈ { 1 , . . . , N } , ∣ σ j r o w ( i ) − i ∣ < 2 k , ( 1 ) \ ∀i∈\{1,...,N\},|σ_j^{row}(i)-i|<2k, (1) ∀i∈{ 1,...,N},∣σjrow(i)−i∣<2k,(1)
同理,可以在列上运用 σ i c o l \ σ^{col}_i σicol来对区域重新排列:
∀ j ∈ { 1 , . . . , N } , ∣ σ i c o l ( j ) − j ∣ < 2 k , ( 2 ) \ ∀j∈\{1,...,N\},|σ_i^{col}(j)-j|<2k, (2) ∀j∈{ 1,...,N},∣σicol(j)−j∣<2k,(2)
这样,就把原图中的区域坐标由 ( i , j ) \ (i,j) (i,j)转换到了 σ ( i , j ) \ σ(i,j) σ(i,j):
σ ( i , j ) = ( σ j r o w ( i ) , σ i c o l ( j ) ) , ( 3 ) \ σ(i,j)=(σ_j^{row}(i),σ_i^{col}(j)), (3) σ(i,j)=(σjrow(i),σicol(j)),(3)
这种洗牌方法破坏全局结构的同时能确保局部区域在其邻域内以可调整的大小随机变动。
- NOTE
也就是把原图切成NxN(N=7)的小图,每个小图和它周围上下左右距离k(k=2)范围内的小图随机交换位置。
原始图像 I \ I I,其破坏形式 ϕ ( I ) \ \phi(I) ϕ(I)和表示细粒度类别的ground truth一对多标签(one-vs-all label) l \ l l,这三个在训练时被组合在一起为 [ I , ϕ ( I ) , l \ [I,\phi(I),l [I,ϕ(I),l]。分类网络将输入图像映射到概率分布向量 C ( I , θ c l s ) \ C(I,θ_{cls}) C(I,θcls),其中 θ c l s \ θ_{cls} θcls是分类网络中所有层的可学习参数。分类网络的损失函数 L c l s \ L_{cls} Lcls可以写成:
L c l s = − ∑ I ∈ Γ l ⋅ l o g [ C ( I ) C ( ϕ ( I ) ) ] , ( 4 ) \ L_{cls}=-\sum_{I∈\Gamma}l \cdot log[C(I)C(\phi(I))], (4) Lcls=−I∈Γ∑l⋅log[C(I)C(ϕ(I))],(4)
其中, Γ \ \Gamma Γ是所有训练集。
由于全局结构已被破坏,为了识别这些随机打乱的图像,分类网络必须找到判别区域并学习类别之间的细微差异。
- NOTE
(1)网络输入图片的标签(one-vs-all label) l \ l l的值为1则图片属于该类,为0则图片不属于该类,即要么是这一类,要么就是其他类。
(2)通过分类损失 L c l s \ L_{cls} Lcls的定义可以看到,要想损失很小,则需要 C ( I ) \ C(I) C(I)和 C ( ϕ ( I ) ) \ C(\phi(I)) C(ϕ(I))的值都接近1。当都接近1,即损失很小时,原始图片产生的 C ( I ) \ C(I) C(I)可以保证网络学习到了关于原始输入图片正确的特征表达,但 C ( ϕ ( I ) ) \ C(\phi(I)) C(ϕ(I))就不一定了,这时并不能保证能够通过“被破坏的图片”学习到正确的特征表达,由于RCM引入了噪声,网络在学习中有可能把某些噪声分布当作对该类的描述,这将导致出现网络对噪声模式的过拟合。
3.1.2 Adversarial Learning(对抗学习)
使用RCM破坏图像并不总是有益的。例如,在图3中,RCM在对局部区域进行洗牌时也引入了噪声视觉模式。从这些噪声视觉模式中学习特征对分类任务是有害的。为此,作者提出了另一个对抗性损失 L A d v \ L_{Adv} LAdv,以防止过拟合RCM引起的噪声模式进入特征空间。
将原始图像和被破坏图像视为两个域,对抗性损失和分类损失以对抗的方式工作:
- 1)保持域不变模式
- 2)抑制 C ( I ) \ C(I) C(I)和 C ( ϕ ( I ) ) \ C(\phi(I)) C(ϕ(I))之间的特定域模式
给每个图片打上one-hot标签向量 d ∈ { 0 , 1 } 2 \ \mathbf{d}\in \{ 0,1 \}^2 d∈{ 0,1}2,指示图片是(0)否(1)被“破坏”过。这样可以在DCL框架中添加判别器(discriminator)作为新分支,通过以下方式判断图像 I \ I I是否被破坏过:
D ( I , θ a d v ) = s o f t m a x ( θ a d v C ( I , θ c l s [ 1 , m ] ) , ( 5 ) \ D(I,\theta_{adv})=softmax(\theta_{adv}C(I,\theta_{cls}^{[1,m]}), (5) D(I,θadv)=softmax(θadvC(I,θcls[1,m]),(5)
其中, C ( I , θ c l s [ 1 , m ] ) \ C(I,\theta_{cls}^{[1,m]}) C(I,θcls[1,m])是从主干分类网络的第 m \ m m层输出的特征向量, θ c l s [ 1 , m ] \ \theta_{cls}^{[1,m]} θcls[1,m]是分类网络的从第1层到第 m \ m m层的可学习参数, θ a d v ∈ R d × 2 \ \theta _{adv}\in\mathbb{R}^{d\times 2} θadv∈Rd×2是一个线性映射。判别器网络的损失 L a d v \ L_{adv} Ladv计算方式为:
L a d v = − ∑ I ∈ Γ d ⋅ l o g [ D ( I ) + ( 1 − d ) ⋅ l o g [ D ( ϕ ( I ) ) ] , ( 6 ) \ L_{adv}=-\sum_{I∈\Gamma}d \cdot log[D(I)+(1-d)\cdot log[D(\phi(I))], (6) Ladv=−I∈Γ∑d⋅log[D(I)+(1−d)⋅log[D(ϕ(I))],(6)
- NOTE
这里的判别器可以看做是GAN里面的判别器,这里是用来判别被破坏图像和原始图像(通过特征图),然后计算损失。
(1)输入:特征向量(不清楚是来自原始图还是被破坏图);
(2)输出:判别结果;
(3)送入特征(来自原始图),判别器能够判断出特征向量来自原始图片;
(4)如果网络从被破坏图学到很多噪声特征,那特征和从原始图学到的肯定是不同的,判别器就会判断出特征向量是来自被破坏图;
(5)我们真正想要的是判别器无法分辨出特征是来自原始图还是被破坏图,当无法分辨时,就意味着来自原始图和被破坏图的特征向量是非常接近的,也就意味着网络学习时排除了噪声的干扰;
(6)由损失 L a d v \ L_{adv} Ladv可知,让对抗性损失的值最小,就需要 I \ I I和 ϕ ( I ) \ \phi(I) ϕ(I)的特征判别结果 D ( I ) \ D(I) D(I)和 D ( ϕ ( I ) ) \ D(\phi(I)) D(ϕ(I))两个都接近于1。对抗性损失和分类损失对抗的过程中,就会迫使网络既要学到判别性的特征同时又不能去学习噪声特征。
Justification. 为了更好地理解对抗性损失是如何调整特征学习的,作者进一步可视化了有无对抗损失时主干网络ResNet-50的特征。给定输入图像 I \ I I,用 F m k ( I ) \ F_m^{k}(I) Fmk(I)表示第m层的第k个特征图。对于ResNet-50,取最后一个全连接层前面的层的输出特征来进行对抗性学习(we extract feature from the outputs of the convolutional layer with average pooling next to the last fully-connect layer for adversarial learning.) 因此,最后一个卷积层的第 k \ k k个卷积核对应真实类别 c \ c c的响应为: r k ( I , c ) = F ˉ m k ( I ) × θ c l s [ m + 1 ] [ k , c ] \ r^k(I,c)=\bar{F}_{m}^{k}(I)×θ_{cls}^{[m + 1]}[k,c] rk(I,c)=Fˉmk(I)×θcls[m+1][k,c],其中 θ c l s [ m + 1 ] [ k , c ] \ θ_{cls}^{[m +1]}[k,c] θcls[m+1][k,c]是第 k \ k k个特征图与第 c \ c c个输出类别之间的权重。
- NOTE
F m k ( I ) \ F_{m}^{k}(I) Fmk(I)为第 k \ k k个卷积核对应的特征图, θ c l s [ m + 1 ] [ k , c ] \ θ_{cls}^{[m +1]}[k,c] θcls[m+1][k,c]即为全连接层对应第 c \ c c个的权重。这块以此来衡量卷积核能否把输入图像映射到 c \ c c,响应越大表明映射的置信度越高。
作者比较了不同卷积核对原始图像和破坏版图像的响应,如图4所示,其中每个具有正响应的卷积核在散点图中都映射到数据点 ( r ( I , c ) , r ( ϕ ( I ) , c ) ) \ (r(I,c),r(\phi(I),c)) (r(I,c),r(ϕ(I),c))。可以发现,由 L c l s \ L_{cls} Lcls训练的特征图的分布比 L c l s + L a d v \ L_{cls}+L_{adv} Lcls+Ladv训练的特征图更紧凑,这意味着卷积核对RCM引入的噪声模式有较大的响应,对原始图像也可能有较大的响应(A,B和C的可视化中,有很多卷积核对缘型视觉模式或RCM引入的不相关的模式有响应),这些卷积核可能会误导对原始输入图像的预测。
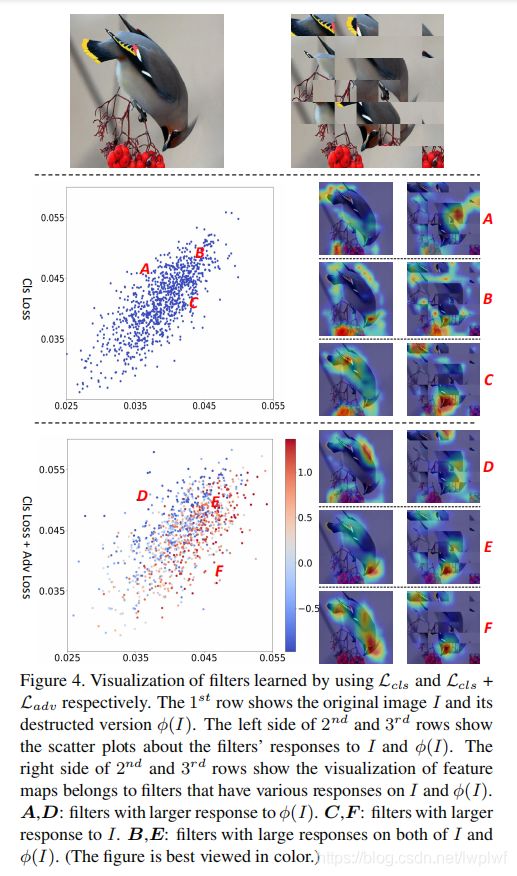
作者还根据 L c l s + L a d v \ L_{cls}+L_{adv} Lcls+Ladv的值对散点图中 L c l s + L a d v \ L_{cls}+L_{adv} Lcls+Ladv训练的主干网络相关的点进行上色,
δ k = F ˉ m k ( I ) × θ a d v [ k , 1 ] − F ˉ m k m ( ϕ ( I ) ) × θ a d v [ k , 2 ] , ( 7 ) \ δk = \bar{F}_m^k(I)×θ_{adv}[k, 1]-\bar{F}_m^km(\phi(I))×θ_{adv}[k,2], (7) δk=Fˉmk(I)×θadv[k,1]−Fˉmkm(ϕ(I))×θadv[k,2],(7)
其中 θ a d v [ k , 1 ] \ θ_{adv}[k,1] θadv[k,1]是连接特征图 F m k ( ⋅ ) \ F_m^k(·) Fmk(⋅)和代表原始图像标签的权重,而 θ a d v [ k , 2 ] \ θ_{adv}[k,2] θadv[k,2]是连接特征图 F m k ( ⋅ ) \ F_m^k(·) Fmk(⋅)和代表被破坏图像标签的权重。 δ k \ δ_k δk评估第 k \ k k个卷积核是否倾向于成为原始图像中的视觉模式(值越大,表明越倾向于原图)。 可以看到,通过使用对抗损失,可以区分出卷积核对噪声视觉模式的响应(D VS. F)。 图中的点可以分为三部分。D:倾向于对噪声模式做出响应的卷积核(RCM引入的图像特征);F:倾向于响应图像整体结构(原始图像特定的图像特征)的卷积核;E:绝大多数过滤器与 L c l s \ L_{cls} Lcls所增强的局部细节区域有关,是原始图像和被破坏图像之间的共同特征。
L c l s \ L_{cls} Lcls和 L a d v \ L_{adv} Ladv共同为“破坏”学习做出贡献,其中仅增强了具有判别性的局部细节,并滤除了不相关的特征。
3.2. Construction Learning(构造学习)
考虑到图像中相关区域的组合构成了复杂多样的视觉模式,作者提出了另一种对局部区域之间的相关性进行建模的学习方法。具体来说,提出了一种区域对齐网络( region alignment network),该网络采用区域构造损失 L l o c \ L_{loc} Lloc,可以测量图像中不同区域的位置精度,以引导主干网络通过端到端训练对区域之间的语义相关性进行建模。
给定图像 I \ I I及其对应的破坏版图像 ϕ ( I ) \ \phi(I) ϕ(I),位于图像 I \ I I中位置 ( i , j ) \ (i,j) (i,j)处的区域 R i , j \ R_{i,j} Ri,j与图像 ϕ ( I ) \ \phi(I) ϕ(I)中的区域 R σ ( i , j ) \ R_{σ(i,j)} Rσ(i,j)一致。区域对齐网络作用于分类网络 C ( ⋅ , θ c l s [ 1 , n ] ) \ C(·,θ_{cls}^{[1,n]}) C(⋅,θcls[1,n])第 n \ n n个卷积层的输出特征图,经过 1 × 1 \ 1×1 1×1卷积处理,得到具有两个通道的输出。然后,通过ReLU和平均池化处理,得到一个大小为 2 × N × N \ 2×N×N 2×N×N的特征图。区域对齐网络的输出可以写成:
M ( I ) = h ( C ( I , θ c l s [ 1 , n ] ) , θ l o c ) , ( 8 ) \ M(I)=h(C(I,θ_{cls}^{[1,n]}),θ_{loc}), (8) M(I)=h(C(I,θcls[1,n]),θloc),(8)
其中, M ( I ) \ M(I) M(I)中的两个通道分别对应行和列的位置坐标,其中 h \ h h是区域对齐网络, θ l o c \ θ_{loc} θloc是区域对齐网络中的参数。
- NOTE
(1)这块文章说用的ReLU,但开源的代码中却用的是torch.tanh;
// DCL code segment from "LoadMoel.py".
if self.use_dcl:
mask = self.Convmask(x)
mask = self.avgpool2(mask)
mask = torch.tanh(mask)
mask = mask.view(mask.size(0), -1)
- NOTE
(2)输出的 2 × N × N \ 2×N×N 2×N×N特征图的每个空间位置点预测一个区域位置,每个空间位置点有两个值分别预测区域的横纵坐标,一共有 N × N \ N×N N×N个子区域。
将 R σ ( i , j ) \ R_{σ(i,j)} Rσ(i,j)在 I \ I I中的预测位置表示为 M σ ( i , j ) ( ϕ ( I ) ) \ M_{σ(i,j)}(\phi(I)) Mσ(i,j)(ϕ(I)),将 R i , j \ R_{i,j} Ri,j在 I \ I I中的预测位置表示为 M i , j ( I , i , j ) \ M_{i,j}(I,i,j) Mi,j(I,i,j)。 M σ ( i , j ) ( ϕ ( I ) ) \ M_{σ(i,j)}(\phi(I)) Mσ(i,j)(ϕ(I))和 M i , j ( I ) \ M_{i,j}(I) Mi,j(I)的ground truth都是 ( i , j ) \ (i,j) (i,j)。区域对齐损失(region alignment loss) L l o c \ L_{loc} Lloc定义为预测坐标和原始坐标之间的 L 1 \ L1 L1距离:
L l o c = ∑ I ∈ Γ ∑ i = 1 N ∑ j = 1 N ∣ M σ ( i , j ) ( ϕ ( I ) ) − [ i j ] ∣ 1 + ∣ M i , j ( I ) − [ i j ] ∣ 1 , ( 9 ) \ L_{loc}=\sum_{I∈\Gamma}\sum_{i=1}^N\sum_{j=1}^N\mid M_{σ(i,j)}(\phi(I))-\begin{bmatrix}i\\j\end{bmatrix}\mid_1+\mid M_{i,j}(I)-\begin{bmatrix}i\\j\end{bmatrix}\mid_1, (9) Lloc=I∈Γ∑i=1∑Nj=1∑N∣Mσ(i,j)(ϕ(I))−[ij]∣1+∣Mi,j(I)−[ij]∣1,(9)
区域构造损失(region construction loss)有助于定位图像中的主要目标,并倾向于找到子区域之间的相关性。通过端到端训练,区域构造损失可以帮助分类主干网络建立对目标的深层理解,并对目标的形状和目标各部分之间的语义相关性等结构信息进行建模。
3.3. Destruction and Construction Learning(破坏与构造学习)
在DCL框架中,以端到端的方式训练(分类损失、对抗性损失和区域对齐损失),其中网络可以利用增强的局部细节和精心建模的目标局部之间的相关性来进行细粒度识别。具体来说,要最小化以下目标:
L = α L c l s + β L a d v + γ L l o c . ( 10 ) \ L=αL_{cls}+βL_{adv}+γL_{loc}. (10) L=αLcls+βLadv+γLloc.(10)
图2是DCL框架的体系结构。破坏性学习主要帮助从判别性区域中进行学习,而构造学习则根据区域之间的语义相关性帮助重新排列学习到的局部细节。因此,DCL基于来自判别性区域的结构良好的细节特征,生成了一组复杂而多样的视觉表示。
注意,仅 f ( ⋅ , θ c l s [ 1 , l ] ) \ f(·,θ_{cls}^{[1,l]}) f(⋅,θcls[1,l])用于预测给定图像的类别标签。因此,除了用于推断的主干分类网络之外,没有额外计算开销。
4. Experiments
作者在CUB-200-2011(CUB)、Stanford Cars(CAR)和FGVC-Aircraft(AIR)三个标准细粒度识别数据集上评估了DCL的性能,所有实验中均未使用任何边界框/局部标注。
4.1. Implementation Details(实现细节)
- (1)标签: 训练标签只有训练图片的类别;
- (2)基础网络: 作者分别在ResNet-50和VGG-16这两个主干网络上对DCL做了评估,并使用在ImageNet上的预训练模型;
- (3)数据增强: 输入图像resize为512×512,然后随机裁剪为448×448,还用了随机旋转和随机水平翻转;
- (4)基础网络修改: 为了在不进行二次采样的情况下识别VGG-16上的高分辨率图像,将VGG-16中的前两个完全连接的层分别转换为两个卷积层;
- (5)DCL实现细节1: 本文所有实验,主干网络最后一个卷积层输出的特征图送入区域对齐网络,最后一个卷积层+平均池化得到的特征向量送入对抗性学习网络;
- (6)DCL实现细节2: RCM中区域划分为NxN,N取值与主干网络和输入图像尺寸有关,每个区域的高和宽需要能被32整除(VGG和Resnet的网络步长)。为了保证区域对齐的可行性,输入图像的宽和高必须能被N整除,N设为7,后面有实验验证(7x64=448);
- (7)DCL实现细节3: 每次训练跑180个epoch,学习率每 60 个epoch降低为原来的十分之一;现在我某个任务的训练中,大概22万数据,不到1000类,跑到40个epoch时就已经收敛的差不多了。。。看来我针对自己的任务还得再调一调。
- (8)DCL实现细节4: 测试时,先resize到512,再CenterCrop到448,这里不再和训练时一样用RandomCrop。
// DCL code segment from "config.py".
'test_totensor': transforms.Compose([
transforms.Resize((resize_reso, resize_reso)),
transforms.CenterCrop((crop_reso, crop_reso)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]),
- (9)我的经验: 我在做Person ReID时积累额调参经验吧,就是在训练部分的RandomCrop前加上一圈pad,亲测在DCL上也涨点,拿走不谢!
// DCL code segment from "config.py".
'common_aug': transforms.Compose([
transforms.Resize((resize_reso, resize_reso)),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(degrees=25),
transforms.pad(10),
transforms.RandomCrop((crop_reso,crop_reso)),
]),
4.2. Performance Comparison(性能比较)
表1列出了作者在CUB-200-2011,Stanford Cars和FGVC-Aircraft上的实验结果。考虑到一些比较方法使用图像级标签或边界框注释,额外注释的信息也显示在括号中,以便直接比较。DCL的单模型和单一裁剪表现达到了最先进的水平,在所有三个数据集上都没有额外的标注。
本文所有实验设置 α = β = 1 \ α=β=1 α=β=1。对于诸如CUB-200-2011之类的非刚性物体识别任务,不同区域之间的相关性对于深入理解目标非常重要。因此,设置 γ = 1 \ γ=1 γ=1。而对于刚性物体识别任务,如Stanford Cars 和 FGVC-Aircraft,目标局部是具有判别性并互补的,因此,刚性物体识别任务设置 γ = 0.01 \ γ=0.01 γ=0.01,以突出破坏学习在学习来自判别区域的细节视觉表示中的作用。与鸟类和汽车等其它细粒度类别不同,飞机的结构会随着其设计而发生显著变化。例如,机翼,起落架,每个起落架的车轮,发动机等的数量各不相同。因此,表1中作者将FGVC-Aircraft上N设置为2,以在一定程度上保留结构信息。
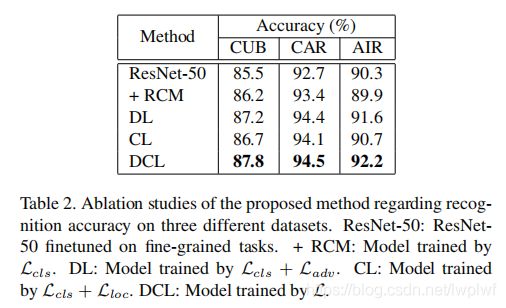
表1、2表明,ResNet-50基准已经非常具有竞争力。DCL仍然可以在所有三个任务上以较大的幅度(例如,平均提高2.3%)以优异的表现胜过强大的基线。

4.3. Ablation Studies(消融实验)
使用ResNet-50作为主干网络,在三个数据集中设计了不同的运行方式,结果见表2。结果表明,DCL可以显著提高性能。破坏学习(destruction learning,DL)引起的性能改进证明,区分噪声的视觉模式、局部细节视觉模式和全局视觉模式的结构良好的视觉特征空间有利于细粒度识别任务。同样,通过构造学习(construction learning,CL)建模的目标对象的形状和结构信息可以进一步提高细粒度类模型的性能。此外,对抗性学习和区域构造是高度互补的。
4.4. Discussions
(1)Partition Granularity (N):讨论了N取值不同带来的影响
当N增加时,识别准确度先增加然后减小。

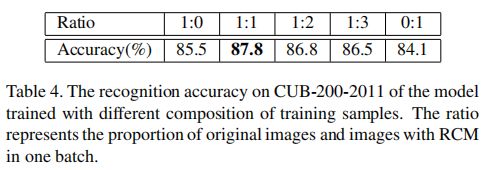
(2)Ratio of Destructed Images in a Min-batch:讨论了被破坏图像在一个mini-batch中所占比例的影响
mini-batch中原始图像和被破坏图像的默认比例设为1:1。表4为CUB-200-2011比例范围设为1:0到0:1的识别精度。如图所示,当比例设置为0:1时,由于训练数据中没有全局上下文信息,性能会大幅降低。
(3)Feature Visualization:可视化最后一个卷积层特征
比较基础模型和DCL的特征图,可以发现DCL的特征图热点更集中在判别性区域。通过不同的洗牌,基于DCL的模型一致地突出显示判别区域,这证明了DCL方法的鲁棒性。

(4)Object Localization:目标定位
作者还使用SPN在VOC2007数据集上的弱监督目标定位任务上测试了DCL。选择指向定位精度(PLAcc)作为评价指标,该指标衡量网络是否可以定位目标的正确区域。实验结果见表5。可以发现,应用DCL后,PLAcc从87.5%提高到88.7%,这再次证明了DCL有助于学习正确的区域。

(5)Destruction Hyperparameter (k):讨论了破坏学习时的超参数k的影响
结论:k=2时效果最好,但k的影响不大。

(7)Model Complexity:模型复杂度
在训练时,DCL仅需要一个简单的操作(RCM)和两个轻量级的网络结构(对抗性学习网络和区域对齐网络)。对于ResNet-50+DCL,DCL引入了8,192个新参数,这些参数仅比基线ResNet-50多0.034%。由于DCL中只有很少的附加参数,因此网络训练效率很高。此外,训练到收敛所需的迭代次数与基线相同。
在测试时,仅使用基础分类网络。与ResNet-50相比,DCL在相同的推理时间消耗下,得到了明显更好的结果(+2.3%),这增加了DCL的实用价值。
5. Conclusion
在本文中,作者提出了一种用于细粒度图像识别的新型DCL框架。DCL中的破坏学习增加了识别的难度,可以指导网络学习专家知识以进行细粒度的识别。 而构造学习可以对目标各部分之间的语义相关关系进行建模。该方法不需要额外的监督信息,并且可以端到端的训练。针对最新技术的广泛实验显示了该方法在各种细粒度识别任务上的优越性能。而且,该方法轻量化,易于训练,推理快并且具有良好的实用价值。