Scikit-learn:模型选择Model selection之pipline和交叉验证
http://blog.csdn.net/pipisorry/article/details/52250983
选择合适的estimator
通常机器学习最难的一部分是选择合适的estimator,不同的estimator适用于不同的数据集和问题。
sklearn官方文档提供了一个图[flowchart],可以快速地根据你的数据和问题选择合适的estimator,单击相应的区域还可以获得更具体的内容。
代码中我一般这么写
def gen_estimators():
'''
List of the different estimators.
'''
estimators = [
# ('Lasso regression', linear_model.Lasso(alpha=0.1), True),
('Ridge regression', linear_model.Ridge(alpha=0.1), True),
# ('Hinge regression', linear_model.Hinge(), True),
# ('LassoLars regression', linear_model.LassoLars(alpha=0.1), True),
('OrthogonalMatchingPursuitCV regression', linear_model.OrthogonalMatchingPursuitCV(), True),
('BayesianRidge regression', linear_model.BayesianRidge(), True),
('PassiveAggressiveRegressor regression', linear_model.PassiveAggressiveRegressor(), True),
('HuberRegressor regression', linear_model.HuberRegressor(), True),
# ('LogisticRegression regression', linear_model.LogisticRegression(), True),
]
return estimators然后如下遍历算法
def cross_validate():
for name, clf, flag in gen_estimators():
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.4, random_state=0)
clf.fit(x_train, y_train)
print(name, '\n', clf.coef_)
# scores = cross_val_score(clf, x, y, cv=5, scoring='roc_auc')
y_score = clf.predict(x_test)
y_score = np.select([y_score < 0.0, y_score > 1.0, True], [0.0, 1.0, y_score])
scores = metrics.roc_auc_score(y_true=[1.0 if _ > 0.0 else 0.0 for _ in y_test], y_score=y_score)
print(scores)自己写的模型也可以,但是写的estimator类必须有的方法是有:get_params, set_params(**params), fit(x,y), predict(new_samples), score(x, y_true)。其中有的可以直接从from sklearn.base import BaseEstimator中继承。如:
class DriveRiskEstimator(BaseEstimator):
def __init__(self):
pass
def get_params(self, deep=True):
return {}
def set_params(self, **params):
return self
def fit(self, x, y):
'''
模型训练
'''
return self
def predict(self, new_samples):
'''
模型预测
'''
result = np.zeros(len(new_samples))
return result
def score(self, x, y_true):
y_pred = self.predict(x)
score = metrics.***(y_true, y_pred)
return score[Scikit-learn:模型选择之调参grid search]
皮皮blog
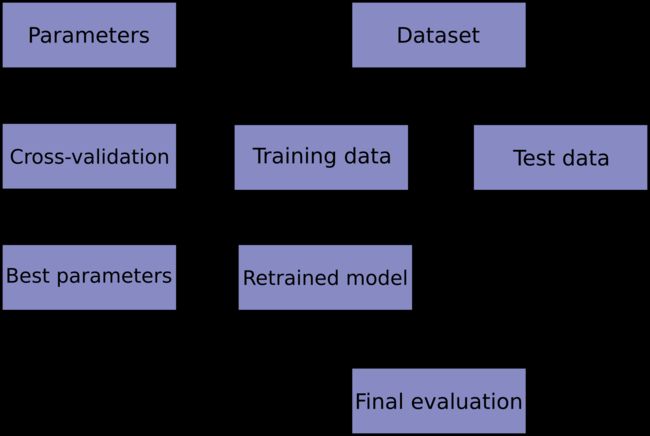
scikit-klean交叉验证
hold测试:训练集和测试集分割
直接对dataframe分割,如果df存在头部,则分割后的每个部分都会自带头部:
data_df = readCsv(path_train)
train_data, test_data = model_selection.train_test_split(data_df, test_size=0.3)也可以对x\y分开分割:
X_train, X_test, y_train, y_test = model_selection.train_test_split(x, y, test_size=0.4, random_state=0)
X_train.shape, y_train.shape
((90, 4), (90,))
X_test.shape, y_test.shape
((60, 4), (60,))
clf = svm.SVC(kernel='linear', C=1).fit(X_train, y_train)
clf.score(X_test, y_test)
0.96...
sklearn交叉验证
scores = cross_val_score(clf, x, y, cv=10, scoring=rocAucScorer)也可以不指定scoring函数,此时自动调用定义的Estimator类中的score函数score(self, x, y_true):
estimator = Estimator().fit(x, y)
scores = cross_val_score(estimator, x, y, cv=cv)自定义CV策略
(cv是整数的话默认使用KFold):
>>> n_samples = iris.data.shape[0]
>>> cv = cross_validation.ShuffleSplit(n_samples, n_iter=3, test_size=0.3, random_state=0)
>>> cross_validation.cross_val_score(clf, iris.data, iris.target, cv=cv)
array([ 0.97..., 0.97..., 1. ])另一个接口cross_val_predict ,可以返回每个元素作为test set时的确切预测值(只有在CV的条件下数据集中每个元素都有唯一预测值时才不会出现异常),进而评估estimator:
>>> predicted = cross_validation.cross_val_predict(clf, iris.data, iris.target, cv=10)
>>> metrics.accuracy_score(iris.target, predicted)
0.966...
[scikit-klean交叉验证]
皮皮blog
from: http://blog.csdn.net/pipisorry/article/details/52250983
ref: [scikit-learn User Guide]
[Model selection and evaluation]
[3.1. Cross-validation: evaluating estimator performance]*
[3.4. Model persistence]
[Sample pipeline for text feature extraction and evaluation*]