【Kaggle】导致患心脏病的因素分析
这篇文章根据已有的数据对一个人是否患有心脏病进行预测,并分析每个特征对预测结果的影响,以及对于每个病人而言,究竟是哪个特征的异常最终导致了他的患心脏病的概率大大增加了。
项目来源于Kaggle:https://www.kaggle.com/tentotheminus9/what-causes-heart-disease-explaining-the-model,感兴趣也可以clone他的kernel去玩一玩。如果时间有限的话,下文也整理了其中的关键技术和要点供你快速查看。
数据

原始数据一共有13个特征以及一个预测变量target,若target为1表示患心脏病,否则就没有。
部分实现细节
数据筛选——pandas自带的one-hot实现
dt = pd.get_dummies(dt, drop_first=True)
pandas中自带的one-hot方式实现,drop_first=True是为了减少数据冗余,因为对性别来说一个是1了之后,就可以去定是0的是另一种性别。对与3分类而言同样全0可以表示被删除的另一种情况。
可视化决策树方法
划分数据集与训练
X_train, X_test, y_train, y_test = train_test_split(dt.drop('target', 1), dt['target'], test_size = .2, random_state=10) #split the data
model = RandomForestClassifier(max_depth=5)
model.fit(X_train, y_train)
可视化决策树
estimator = model.estimators_[1]
feature_names = [i for i in X_train.columns]
y_train_str = y_train.astype('str')
y_train_str[y_train_str == '0'] = 'no disease'
y_train_str[y_train_str == '1'] = 'disease'
y_train_str = y_train_str.values
export_graphviz(estimator, out_file='tree.dot',
feature_names = feature_names,
class_names = y_train_str,
rounded = True, proportion = True,
label='root',
precision = 2, filled = True)
from subprocess import call
call(['dot', '-Tpng', 'tree.dot', '-o', 'tree.png', '-Gdpi=600'])
from IPython.display import Image
Image(filename = 'tree.png')

使用的包如下:
from sklearn.ensemble import RandomForestClassifier #for the model
from sklearn.tree import export_graphviz #plot tree
混淆矩阵
from sklearn.metrics import roc_curve, auc #for model evaluation
from sklearn.metrics import classification_report #for model evaluation
from sklearn.metrics import confusion_matrix #for model evaluation
confusion_matrix = confusion_matrix(y_test, y_pred_bin)
total=sum(sum(confusion_matrix))
sensitivity = confusion_matrix[0,0]/(confusion_matrix[0,0]+confusion_matrix[1,0])
print('Sensitivity : ', sensitivity )
specificity = confusion_matrix[1,1]/(confusion_matrix[1,1]+confusion_matrix[0,1])
print('Specificity : ', specificity)
结果:
array([[28, 7],
[ 3, 23]])
Sensitivity : 0.9032258064516129
Specificity : 0.7666666666666667
ROC曲线:
fpr, tpr, thresholds = roc_curve(y_test, y_pred_quant)
fig, ax = plt.subplots()
ax.plot(fpr, tpr)
ax.plot([0, 1], [0, 1], transform=ax.transAxes, ls="--", c=".3")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.rcParams['font.size'] = 12
plt.title('ROC curve for diabetes classifier')
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('True Positive Rate (Sensitivity)')
plt.grid(True)

auc(fpr, tpr)
#0.9131868131868132
结果解释
1.重要性贡献
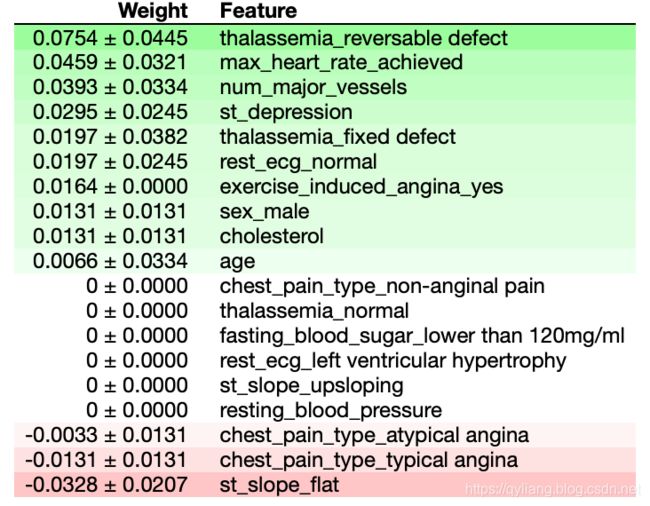
Permutation importance是理解机器学习模型的第一个工具,它对验证数据集中的各个变量进行打乱(在一个模型被拟合之后),并观察其对准确性的影响。
perm = PermutationImportance(model, random_state=1).fit(X_test, y_test)
eli5.show_weights(perm, feature_names = X_test.columns.tolist())
用到的包:
import eli5 #for purmutation importance
from eli5.sklearn import PermutationImportance
看起来,就排列而言,最重要的因素是“可逆转缺陷”导致的地中海贫血(halessemia result of ‘reversable defect’)。“max heart rate achieved”类型的重要性是有意义的,因为这是病人在检查时的直接的、主观的状态(相对于,比如说,年龄,这是一个更普遍的因素)。
2.单个变量变化对结果的影响
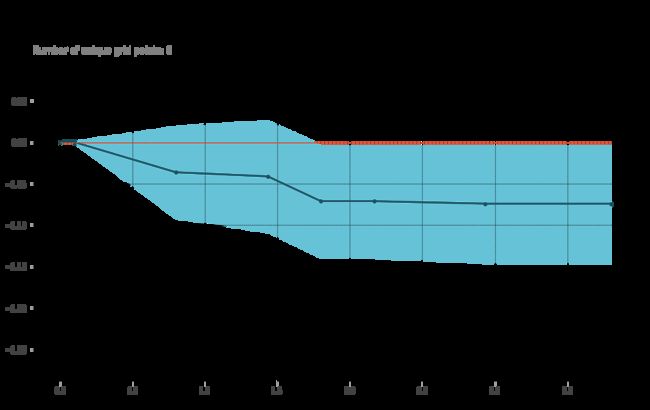
Partial Dependence Plot查看部分变量的改变对结果的影响。这些图在一个值范围内改变一行中的单个变量,并查看它对结果的影响。它对几行这样做,并绘制平均效果。让我们来看看’num_major_vessel '变量,它位于排列重要性列表的顶部。

因此,我们可以看到,随着主要血管的数量增加,心脏病的概率降低。这是有道理的,因为这意味着更多的血液可以进入心脏。
再来看看“st_depression”对最终结果的影响:
from pdpbox import pdp, info_plots #for partial plots
pdp_dist = pdp.pdp_isolate(model=model, dataset=X_test, model_features=base_features, feature=feat_name)
pdp.pdp_plot(pdp_dist, feat_name)
plt.show()
有趣的是,这个变量的升高之后患心脏病的概率也降低了。
这到底是什么?在谷歌上搜索后,我发现了以下的描述,“心电图(ECG)测量心脏的电活动。出现在它上面的波被标记为P、QRS和T,每一个对应心跳的不同部分。ST段表示右心室和左心室收缩后心脏的电活动,将血液输送到肺和身体其他部分。经过这一巨大的努力,心室肌细胞放松,为下一次收缩做好准备。在此期间,很少或没有电流,所以ST段与基线持平,有时略高于基线。心电图中心跳越快,所有的波就越短。ST段的形状和方向远比它的长度重要。向上或向下的变化可以表示减少流向心脏的血液从有多种原因,包括心脏病、冠状动脉痉挛在一个或多个(Prinzmetal心绞痛),感染心脏内壁(心包炎)或心肌本身(心肌炎),血液中过多的钾,心脏节律的问题,或血凝块的肺(肺栓塞)。“

因此,这个变量被描述为“运动相对于休息引起的ST抑郁”,似乎表明值越高,患心脏病的可能性越高,但上面的图显示的是相反的。也许重要的不仅仅是下压量,而是与坡度类型的相互作用?我们用2D PDP检查一下,
inter1 = pdp.pdp_interact(model=model, dataset=X_test, model_features=base_features, features=['st_slope_upsloping', 'st_depression'])
pdp.pdp_interact_plot(pdp_interact_out=inter1, feature_names=['st_slope_upsloping', 'st_depression'], plot_type='contour')
plt.show()
inter1 = pdp.pdp_interact(model=model, dataset=X_test, model_features=base_features, features=['st_slope_flat', 'st_depression'])
pdp.pdp_interact_plot(pdp_interact_out=inter1, feature_names=['st_slope_flat', 'st_depression'], plot_type='contour')
plt.show()


看起来“st_depression”比较低的时候在这两种情况下都是不好的。奇怪。
3.使用SHAP值查看每一行数据变量值的影响
基本思想:计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,取均值,即某该特征的SHAP baseline value。
例如:A单独工作产生的价值为v{A},加入B后共同产生价值v{A,B},那么B的累加贡献是v{A,B}-v{A}.
对于所有能够形成的全局N的序列,求其中关于元素xi的累加贡献,然后取均值即可得到xi的shapley
下面使用SHAP值来显示单个行中每个变量的值与它们的基线值(了解更多信息)的影响.
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
shap.summary_plot(shap_values[1], X_test, plot_type="bar")

查看总体值的分布:
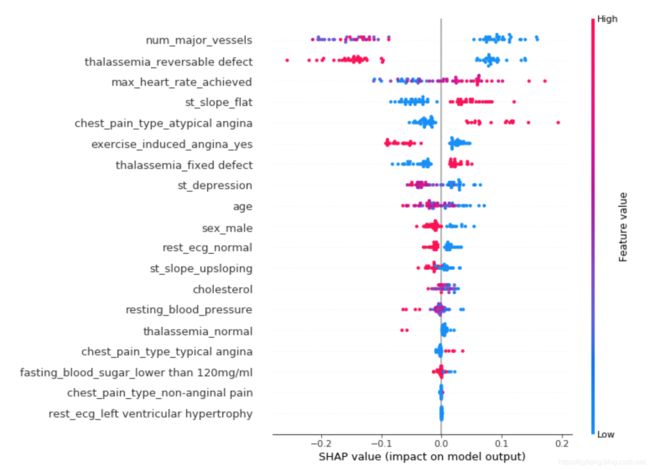
大血管的数量划分很清楚,它说低的数值是不好的(右边的蓝色)。thalassemia“可逆转缺陷”的划分非常清楚(yes = red = good, no = blue = bad)。
你可以在许多其他变量中看到一些明显的分离。运动诱发的心绞痛有一个明确的分离,虽然不像预期的那样,因为“不”(蓝色)增加的可能性。另一个明显的是st_slope。当它是平的时候,这是一个不好的信号(右边的红色)。
同样奇怪的是,在这个模型中,男性(红色)患心脏病的几率降低了。这是为什么呢?领域知识告诉我们,男性有更大的机会。
接下来,让我们挑出个别病人,看看不同的变量是如何影响他们的结果的,
def heart_disease_risk_factors(model, patient):
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(patient)
shap.initjs()
return shap.force_plot(explainer.expected_value[1], shap_values[1], patient)
data_for_prediction = X_test.iloc[1,:].astype(float)
heart_disease_risk_factors(model, data_for_prediction)

对于这个人,他们的预测是36%(而基线是58.4%)。许多事情都对他们有利,包括有一个大血管,一个可逆的地中海贫血缺陷,以及没有一个平坦的st_slope。
另一个人的情况:
data_for_prediction = X_test.iloc[3,:].astype(float)
heart_disease_risk_factors(model, data_for_prediction)

对于这个人,他们的预测是70%(而基线是58.4%)。没有大血管、st_slope平坦、没有可逆的thalassemia缺陷等因素对他们不利。
我们还可以绘制所谓的“SHAP依赖贡献图”,这在SHAP值的上下文中是非常不言自明的,
ax2 = fig.add_subplot(224)
shap.dependence_plot('num_major_vessels', shap_values[1], X_test, interaction_index="st_depression")
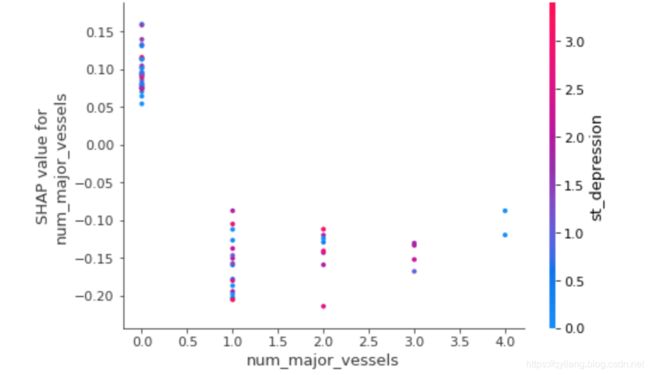
你可以看到主血管数量上的明显变化,但是从st_depression颜色上看似乎并没有太多变化。
最后的图是最有效的图节之一。它显示了对许多患者(本例为50例)的预测和影响因素。它也是互动性的。 从中可以看出每个人为什么最后不是红色(疾病预测)就是蓝色(无疾病预测),
shap_values = explainer.shap_values(X_train.iloc[:50])
shap.force_plot(explainer.expected_value[1], shap_values[1], X_test.iloc[:50])
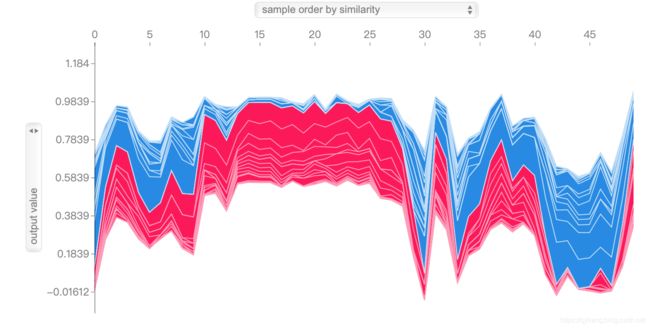
小结
以今天的标准来看,这个数据集又老又小。然而,它允许我们创建一个简单的模型,然后使用各种机器学习可解释工具和技术来窥视内部。一开始,我假设,使用(谷歌)领域知识,如胆固醇和年龄等因素将是模型中的主要因素。这个数据集没有显示出来。相反,影响心电图结果的主要因素和方面占主导地位。我真的觉得我学到了一些关于心脏病的知识!
1,数据的特征是什么?基于此特征为什么要用这种算法模型?
此数据为典型的二分类问题,而且数据中多定性的类型数据,所以理所应当的想到决策树,而决策树Bagging到一起就形成了随机森林,随机森林也是这个模型中采用的算法。
2,在实现过程中有哪些不常见,或者重要的细节?以及在对结果的解释有什么亮点?
Partial Dependence Plot查看部分变量的改变对结果的影响
使用SHAP值查看每一行数据变量值的影响,分析每一个样本中每个特征的边际贡献。
