【数据库】从mysql迁移到sqlserver
我用的工具是navicat premium
右键mysql的数据库选择数据传输
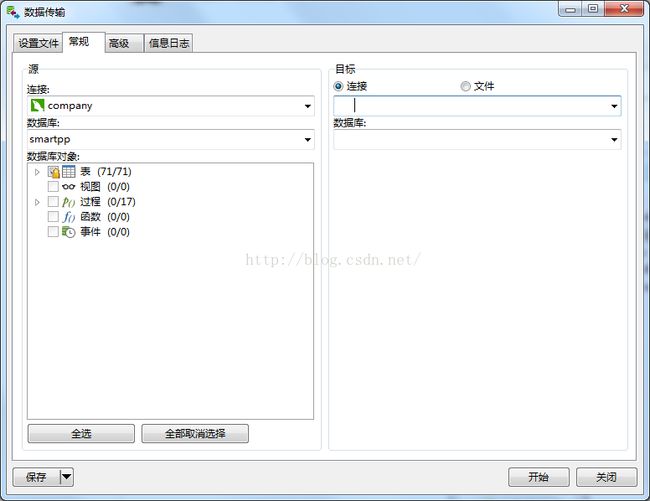
只能选择表,其他默认灰色不能选择(估计是某些函数或者类型不支持造成的)。
在高级选项卡里做进一步设置,确定没干扰的话可以去掉一些勾提升执行效率(如不使用事务)。
右边选择远程数据库后,点击开始。
第一次执行出错,有三张表传输失败,提示是类型不兼容。选择出错的表之后的表,继续执行,直到传输完毕。
剩下不兼容的三张表,只能手动导了。
出现问题:进入sqlserver数据库一看,发现新数据库的表的主键和自增都没了。
下面是修改表的公式,找找看,是否有修改为自增字段的方法。


persisted允许您对具有确定性、但不精确的计算列创建索引,建索引的时候用的
drop not for replication好像有用,测试下
alter table t_role alter column drop not for replication
报错,语法不对,好吧,用不来,跳过。
最后,去官网https://msdn.microsoft.com/zh-cn/library/ms187742.aspx中找了下标识列的资料:
IDENTITY
指定新列为标识列。 SQL Server 数据库引擎为该列提供唯一的增量值。 当您向现有表中添加标识符列时,还会将标识号添加到具有种子值和增量值的现有表行中。无法保证行的更新顺序。 也会为添加的任何新行生成标识号。
标识列通常与 PRIMARY KEY 约束一起用作表的唯一行标识符。 tinyint、smallint、int、bigint、decimal(p,0) 或 numeric(p,0) 列可以使用 IDENTITY 属性。 每个表只能创建一个标识列。 DEFAULT 关键字和绑定默认值不能用于标识列。 要么同时指定种子和增量,要么都不指定。 如果二者都未指定,则取默认值 (1,1)。
然后是最总要的一句
| |
|---|
| |
sqlserver的主键可以直接alter修改,而自增则不能,在sqlserver中自增被称为标识。
需要先删除字段约束,再删除字段,最后重新创建字段的形式修改为自增字段。
对于只修改一张表的某一列为标识列:
alter table t_syslog drop constraint PK__dma_repo__3213E83F1332DBDC;
alter table t_syslog drop column id;
alter table t_syslog add id int identity(1,1);
alter table t_syslog add constraint pk_dma_report_yearly primary key(id);
约束名PK__dma_repo__3213E83F1332DBDC是通过执行alter table t_syslog drop column id得到的错误信息中获取的。
或者
下面的例子是,拼接从sysobject表里查出的用户id为1,类型为约束的约束名
DECLARE
@c VARCHAR(1000)
SELECT @c=(SELECT STUFF(name, 1, 0, ',') from sysobjects a where uid=1 and xtype='PK' for xml path(''))
print @c
对于要批量修改多张表的列为标识列,只好写存储过程了:
下面的例子是删除所有表的约束,执行sql用execute/EXEC函数
DECLARE @tableName varchar(200)
DECLARE @pk varchar(200)
DECLARE a CURSOR for
SELECT a.name,b.name from sysobjects b right JOIN (SELECT name,parent_obj from sysobjects where uid=1 and xtype='PK') a on a.parent_obj=b.id
OPEN a
while @@fetch_status=0
BEGIN
FETCH NEXT from a into @pk,@tableName
PRINT @@fetch_status
if @@fetch_status!=0
RETURN
else
EXECUTE('alter table '+@tableName+' drop '+@pk)
print '丢弃表'+@tableName+'的约束'+@pk
END
CLOSE a
DEALLOCATE a
下面的例子是重建所有表的id字段为自增非空主键
DECLARE @tableName varchar(200)
DECLARE tablenames CURSOR for
SELECT name from sysobjects where uid=1 and xtype='U'
OPEN tablenames
while @@fetch_status=0
BEGIN
FETCH NEXT from tablenames into @tableName
if @@fetch_status!=0
RETURN
else
PRINT '正在设置表'+@tableName+'的字段id为非空自增主键'
EXECUTE('alter table '+@tableName+' drop COLUMN id')
EXECUTE('alter table '+@tableName+' add id int not null PRIMARY KEY IDENTITY')
END
CLOSE tablenames
DEALLOCATE tablenames
小记:
1.grant 权限名(All,execute) on 数据库名 to 用户名
2.ROWGUIDCOL指定该列是一个行全局唯一标识符列。 ROWGUIDCOL 只能分配给 uniqueidentifier 列,并且每个表中只有一个 uniqueidentifier 列可以被指定为 ROWGUIDCOL 列。 不能为用户定义数据类型分配 ROWGUIDCOL。
3.查询所有的存储过程
SELECT * from SYS.sql_modules
4.查看单个存储过程
SELECT OBJECT_DEFINITION(存储过程ID)
5.创建索引:
create [修饰符] index 索引名 on 表名(字段名 排序) with 其他修饰
6.游标状态@@fetch_status,0表示上次读取正常,-1,-2表示失败
7.set IDENTITY_INSERT 数据库名或者表名 on/off 开启关闭手动插入自增字段值
8.sqlserver没有group_concat函数,代替方案:
for xml path关键字
select * from t_user for xml path
输出(类型为字符串,注意不是表):
path指定根元素,默认为row,也可以取消根元素通过for xml path('')获得
实现group_concat相同功能:
select stuff((select ','+name from t_user where id=a.id for xml path('')),1,1,'') from t_user a group by id
输出:张三,李四,王五
注意点:
1.stuff函数:替换部分字符串的函数,作用是去除第一个逗号(有点像replace,只不过replace是全局替换)
stuff(被替换的字符串,位置起始位置(1开始),替换长度,替换内容)
2.for xml path('') 函数:path后的括号中必须填入空字符串参数,表示不用root标签,另外','+name这样的字符串拼接会去掉节点标签,得到纯内容的拼接
拼接时,注意必须为字符串类型,数字类型用cast函数转换
3.子句中的where从句的条件一般是子表的字段对应主表的对应字段,如id=a.id,子句中的表和主表为同一张表。
9.正则表达式匹配
patindex函数
patindex(正则表达式,字符串)
10.用distinct代替group by
现在要查出所有用户的编号角色和用户名,我们首先会想到根据编号分组,再把角色根据
至此,id全部设置完毕,迁移完毕。
然后检测一下,是不是能连上。
public static void main(String[] args) {
try {
Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver");
Connection connection = DriverManager.getConnection("jdbc:sqlserver://ip;databseName=example","username","password");
System.out.println(connection.getCatalog());
System.out.println(connection.getSchema());
Statement st = connection.createStatement();
ResultSet re = st.executeQuery("SELECT name from t_user where id=1");
System.out.println(re.next());
System.out.println(re.getString(1));
} catch (Exception e) {
e.printStackTrace();
}
}
测试要用普通账号,因为表空间的问题。
第一次测试用的sa账户(超级管理员),默认登录到系统数据库master,即使在url中指定了数据库也不行,找不到表。
要用普通账户登录,创建普通账户,赋予登录查询等权限。
连接查询成功。
映射结果时报错No Dialect mapping for JDBC type: -9
说明驱动不支持类型-9,即nvarchar类型,这个可以在Types类源代码中找。
自己写个类,继承SQLServerDialect ,然后在配置文件中引用
public class SqlServerCompatibleDialect extends SQLServerDialect {
public SqlServerCompatibleDialect() {
super();
registerHibernateType(Types.CHAR, Hibernate.STRING.getName());
registerHibernateType(Types.NVARCHAR, Hibernate.STRING.getName());
registerHibernateType(Types.LONGNVARCHAR, Hibernate.STRING.getName());
registerHibernateType(Types.DECIMAL, Hibernate.DOUBLE.getName());
}
}
建议有问题可以去官网上搜搜https://msdn.microsoft.com/zh-cn/library/ms188927.aspx