报表工具对比选型系列用例——排名及跨行组统计
继《多源分片报表》后,我们继续考察这些报表工具对复杂报表的支持程度。
排名与跨行组运算也是典型的中国复杂报表形式,这类报表的源数据集通常比较简单,但在表格的单元格之间会有较随意的计算要求。在制作报表时,单元格还没有扩展出来,因而不能像 Excel 那样直接引用单元格名字,报表工具需要提供某种机制允许在表达式中引用还没有产生的单元格。
用例说明
报表式样
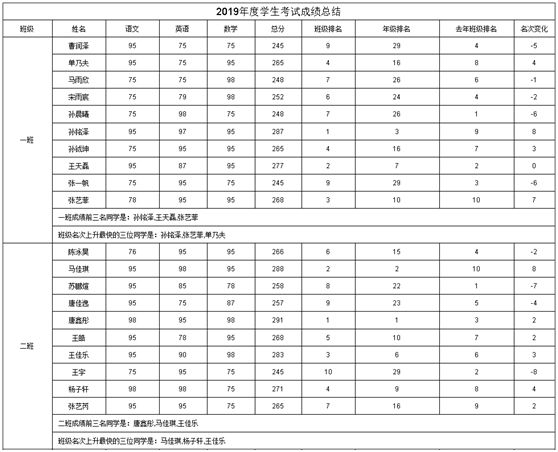
数据结构
[学生成绩表]
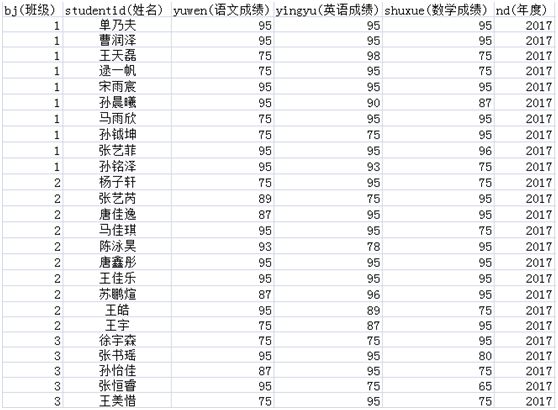
学生成绩表中存储各班级同学历年语文、数学、语文成绩信息
特点分析:
1、 报表中根据学生成绩既要做班级内排名,又要做年级内排名。
2、 报表中要列出去年班级内的名次,以用来展示该同学本学期较上学期的名次变化。
3、 要求统计出各班级内前三名的学号。
4、 要求统计出各班级内名次较上学期上升最快的三位同学的学号。
关于工作量的评估,我们仍假定使用者熟悉相应的报表工具,并只记录实际的制作和正常调试的时间,不包括查阅产品函数资料的时间。
润乾报表
制作过程:
1、 配置并连接数据源。
2、 设置参数及数据集
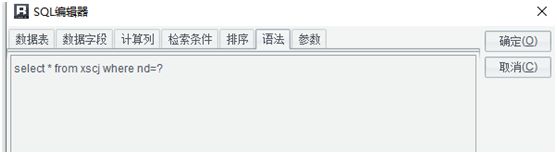
2.1 此报表要求查询出相应年度的学生成绩,所以需要通过传入参数控制具体展示哪年数据,报表中增加参数,参数名为 nd。
2.2 报表中既要统计所选年度数据,还需要和去年数据做比较,所以报表中要取出两年数据,这里为了方便制作和理解,建立两个数据集,分别取出两年数据,如:
ds1(取今年数据):
对应传入参数设置:
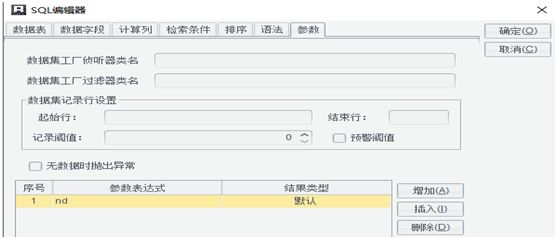
ds2(取去年数据)
数据集语法为 select * from xscj where nd=?
对应传入参数为:nd-1
两个数据集 SQL 语句完全一样,用 ? 代替变量,然后在参数中设置 ? 具体传入值,润乾在传入参数这不仅可以直接写入参数,也可以写入表达式先进行计算。
3、 设计报表模板

这个报表从展现形式上来看是一个分组报表,按照年级分组,列出各班级同学的成绩、排名等信息,然后在每个班级下再增加对应的汇总信息,下面介绍下主要单元格设置情况:
3.1、 A 列到 F 列单元格,都是普通的分组、取数等,按照常规设置就行, 其中 A3 单元格中,数据库里存储的是 1,2,3,4 这种数字格式,显示值表达式中写入:chn(int(value()))+“班”,将数字转换成中文
3.2、 G3 格:=count(F3[A3]{F3>$F3})+1,取出班级内的排名,润乾提供了排名计算方法,统计当前班级内成绩大于当前这人成绩的人员个数,然后再加 1,就是当前这个人的排名。
3.3、 H3 格: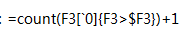 ,前边单元格统计了班级内排名,这个单元格中要统计整个年级的排名情况,表达式同 G3 类似,只不过 G3 中对 F3 计数时加了 [A3], 也就是表示取当年班级内的成绩排名,此处是 [`0],取所有成绩排名,这是润乾特有的层次坐标表示法,可以引用各个分组层次的单元格(及集合)。
,前边单元格统计了班级内排名,这个单元格中要统计整个年级的排名情况,表达式同 G3 类似,只不过 G3 中对 F3 计数时加了 [A3], 也就是表示取当年班级内的成绩排名,此处是 [`0],取所有成绩排名,这是润乾特有的层次坐标表示法,可以引用各个分组层次的单元格(及集合)。
3.4、 I3 格:=ds2.select(YUWEN+YINGYU+SHUXUE,bj==A3 && studentid==B3),因为报表中要列出去年的排名,所以这里要取出去年的总分情况,此列是辅助单元格,然后将这列隐藏掉就行。
3.5、 J3 格:=count(I3[A3]{I3>$I3})+1,去年成绩排名,一样的做法
3.6、 B4~K4,是个合并单元格,表达式:=disp(A3)+“成绩前三名同学是:”+B3{G3==1}+“,”+B3{G3==2}+“,”+B3{G3==3},A3 单元格在数据库中存储的是 1,2,3 这种形式,用 disp 函数取这个单元格的显示值,学号在 B3 单元格,在 G3 单元格中已经算出了排名,所以可以根据排名来获取对应的数据,B3{G3==1} 这个表达式表示取 G3 等于 1 的 B3 单元格的值,这样就取出了第一名的学号,后边两个同样的做法。
3.7、 B5~K5,合并单元格,表达式:=“班级名次上升最快的三位同学是:”+string(esproc(“?.m(?.ptop(-3))”,B3{},K3{})),这个单元格要求取出名次上升最快的三位同学,有多种做法,可以像排名那样,先对名次变化幅度做个排名,然后再根据幅度排名获取前三位,但是这种做法要增加辅助单元格。这里采用了另一做法,使用润乾内置函数 esproc,将 K3 单元格(名次变化幅度)传入,ptop(-3) 取最大的 3 位的位置,然后用 m() 函数根据位置取对应的姓名。esproc 函数允许在报表中引用润乾集算器的表达式,能组合出更为复杂丰富的运算 。
运行结果:
完成后点评
1、 用时 1 小时。报表主要难点排名、汇总统计等都用内置的函数或者特定的做法就行。
2、 函数功能强,像排名时用到的 count 函数,统计分析时的 esproc 函数等,只需要几个函数或者特定的语法就能够完成一些比较复杂的需求。
3、 底层模型强,润乾报表模型中提供了完善的层次坐标引用机制,对于排名计算中会涉及到跨行组之间的计算,直接用特定的语法就行,以及取班级前三名时,B3{G3==1},可以根据已有排名直接获取对应的数据。
4、 关联简单,比如这个报表要求取去年数据,为了简单起见,直接新建了个取去年数据的数据集,在报表中通过字段能直接将两个数据集数据关联在一起,这样制作起来比较方便,也比较易于理解。
帆软报表
制作过程:
1、 配置并连接数据源。
2、 设置参数及数据集
2.1、 参数设置,增加模板参数 p1, 参数类型为字符串,默认值为 2019.
2.2、 数据集设置,拖拽数据库表生成基础 sql, 添加 where 条件,其中数据集中引用参数使用 参数名,ds1:SELECT∗FROMDEMO.XSCJwherend=参数名,ds1:SELECT∗FROMDEMO.XSCJwherend={p1}, 算出参数对应年份的成绩信息。
2.3、 ds2:SELECT bj,studentid,yuwen+shuxue+yingyu zf,nd FROM DEMO.XSCJ where nd=${p1}-1,算出参数对应去年的成绩。
3、 设计报表模板

3.1 A3 单元格显示班级名称,数据库表该字段值是 1,2,3,4 这样的数据,需要设置公式形态 NUMTO(TOINTEGER($$$),true)+"班" 来达到效果。
3.2 G3 单元格的公式为:=count(F3[!0;!0]{A3 = A3 && F3 >A3 && F3 >F3}) + 1。
3.3 H3 单元格计算年级排名,单元格的公式为 =count(F3[!0;!0]{F3 >= $F3}) + 1。
3.4 在 I3 单元格中通过另一个数据集 ds2 取到对应去年的成绩,在高级中增加关联条件:(列名:BJ) 等于 ‘A3’ and (列名:STUDENGID) 等于 ‘B3’。
3.5 在 J3 单元格根据 I3 的去年成绩进行排名,公式为:=count(I3[!0;!0]{A3 = A3 && I3 >A3 && I3 >I3}) + 1。
3.6 在 B4 单元格里要动态显示对应每个班级的名称,帆软中没找到引用其他格子显示值的方法,所以在 B3 单元格表达式中为了得到 1 对应的大写一,表达式中又写了遍 NUMTO(TOINTEGER(A3,true))+“班成绩前三名同学学号是:”+B3{G3==1}+“,”+B3{G3==2}+“,”+B3{G3==3}。
3.7 为了能在 C5 格子得到名次上升最快的三位同学学号,增加了辅助列 L3,L3 的单元格表达式为:=count(K3[!0;!0]{A3 = A3 && K3 >A3 && K3 >K3}) + 1,先对每班的名次变化排了个名,然后对应取到排名为 1,2,3 的学生学号,C5 的单元格表达式为:NUMTO(TOINTEGER(A3,true))+“班班级名次上升最快的三位同学学号是:”+B3{L3==1}+“,”+B3{L3==2}+“,”+B3{L3==3}。
报表结果
完成后点评
1、 用时 1 小时左右。
2、 设计思路、操作过程、工具使用等大多数方法和润乾基本一致,这里就不一一细说了。
3、 帆软没有类似润乾 esproc 的函数,做名次上升最快的统计时,就需要通过增加辅助隐藏列来计算名次变化,增加了额外资源的耗用和开发工作量,当然本例单元格不多,影响不大。
4、 姓名列排序默认是按照 ASCII 排序,并不是按照常规的首字母方式,要按首字母排序要用 StringPinyin() 函数转换下,而且发现一般最后两个人的排序颠倒了,前两个文字的相同,最后一个帆(fan)应该在菲(fei)前边,这个暂时没找到原因。
Smartbi
制作过程
1、 配置并连接数据源。
2、 设置参数及数据集
2.1、 增加‘’年度”参数,参数名为 nianfen。
2.2、 准备数据集
因为要同时查去年成绩作对比,所以这里准备两个数据集(当年成绩、去年成绩、班级转换字典表)。
采用原生 SQL 数据集
当年成绩:
去年成绩:
班级在数据库中存储的是 1,2,3,4 这种,想显示成中文班级需要创建一个中文字典表数据集,数据结构如下:

数据集中直接用 SQL 语句:select * from bj 。
3、 设计报表模板

报表的设计在 excel 内完成,借助丰富的 excel 函数,smartbi 解决这种格间运算也不是太麻烦。如几个关键计算:
3.1 A5 单元格借助“转换规则”将 A5 中的班级通过班级的中文字典表转换成中文的班级名字。
3.2 班级排名(组内排序)G5:=RANK(F5,SSR_GetSubCells(F5,A5)) ,excel 的 RANK 函数和 smartbi 自身函数结合。
3.3 年级排名(组外或总排序)I5:=RANK(F5,(SSR_GetSubCells(F5)))
3.4 去年班级排名(组内排序)J5:与 G5 同理,只不过去年总分不需要显示,H 列为隐藏列
3.5 另外是班级前三及进步最快的学生,这个也可以实现,方法都是 excel 函数与 smartbi 函数的结合,不过写起来有点长。班级前三(B6):=A5&“成绩前三名同学学号是:”&INDEX(SSR_GetSubCells(B5,A5),MATCH(1,SSR_GetSubCells(G5,A5),0))&“,”&INDEX(SSR_GetSubCells(B5,A5),MATCH(2,SSR_GetSubCells(G5,A5),0))&“,”&INDEX(SSR_GetSubCells(B5,A5),MATCH(3,SSR_GetSubCells(G5,A5),0))
3.6 进步前三(B7):=“班级名次上升最快的三位同学学号是:”&INDEX(SSR_GetSubCells(B5,A5),MATCH(LARGE(SSR_GetSubCells(K5,A5),1),SSR_GetSubCells(K5,A5),0))&“,”&INDEX(SSR_GetSubCells(B5,A5),MATCH(LARGE(SSR_GetSubCells(K5,A5),2),SSR_GetSubCells(K5,A5),0))&“,”&INDEX(SSR_GetSubCells(B5,A5),MATCH(LARGE(SSR_GetSubCells(K5,A5),3),SSR_GetSubCells(K5,A5),0))
运行结果
完成后点评:
1、 用时:两小时左右,Smartbi 在 excel 中进行报表开发,比较符合常规使用习惯。
2、 完全在 excel 中操作,容易上手,操作起来比较方便。excel 函数丰富,这个报表主要是其查找类函数的使用。
3、 没有真实值和显示值的分类,在处理数据表的 bj(班级,数据为 1、2 等数值)字段以“一班”等形式呈现的时候,需要借助“转换规则”,先建转换规则,然后给业务数据集的字段选择规则,然后单元格属性勾选“使用显示值”这个东西是系统配置,也就是需要系统功能配合才能做到 ID 反显名称。
4、 提供有按层次访问单元格集合的机制,但层次坐标体系没有润乾和帆软做得简单,可以引用指定位置的单元格,但很麻烦,导致在做前三名统计时,表达式有点复杂。
永洪 BI
制作过程:
1、 配置并连接数据源。
2、 设置参数及数据集
2.1 增加参数“年度”
2.2 本例中要取上年,实际上也是个简单的多源关联报表,在之前制作多源关联报表时,永洪单元格内的多源关联有些问题,所以这里还是在数据集阶段进行处理,这里创建三个数据集:
数据集 1:学生成绩:用 SQL 语句取数,条件中加了个 nd=?{年度},年度是数据定义的传入参数,根据这个参数做数据过滤。并且根据三科成绩新增字段“总分”,班级字段在数据库中存的是数字,这里新增字段做值映射。
数据集 2:上学期成绩:因为要根据传入参数取上学期数据,所以此处增加条件:nd+1=?{年度}
数据集 3:学生成绩统计,新增“组合数据集”,将上述两个数据集通过班级和学号关联在一起:
3、 设计报表模板
3.1 班级列:按照班级进行分组,并且设置纵向三个单元格合并。
3.2 姓名列:取 studentid 字段的值扩展,设置父单元格为班级列
3.3 语文、英语、数学、总分四列,将相应字段按照“总和”方式拖拽到对应位置,注意,这里一定要是总和,否则后边排名会有问题。
3.4 班级排名:将总分字段按照求和方式拖拽到对应单元格,设置动态计算方式为“排名计算”,计算依据设置成“沿平面纵向”,并且设置“纵向父单元格”为 studentid 所在位置
3.5 年级排名:按照班级排名方式进行设置,最后设置计算依据为:“格子”。
3.6 上学期排名:按照班级排名操作,将上学期总分拖拽到对应单元格,并进行设置,数据集中通过组合数据集已经将上学期数据关联在一起。
3.7 名次变化:将单元格类型设置成“格间计算”,设置公式为:cell(ridx,8)-cell(ridx,6),永洪中没有 Excel 单元格概念,所以要用自己内部的一些语法,cell 函数可以根据行列号获取对应单元格的值,ridx 表示当前行号,8 表示报表中的第 9 列
3.8 成绩前三名统计:该单元格类型设置成“格间计算”,里边公式为:cell(ridx-10,0)+“成绩前三名同学是:”,此处做了个字符串拼接,cell(ridx-10,0),这个取对应的班级名称,ridx 是当前行号,现在每个班级都是 10 个人,所以此处减去 10,如果每个班级不同,那么还需要找单元格算出对应的数量才能获取。
3.9 前三名取法:设置单元格类型为“格间计算”,里边公式写入:
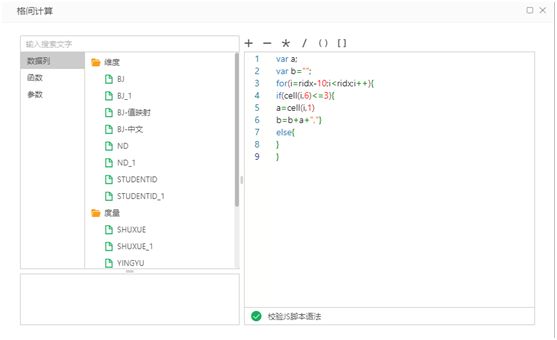
此处通过 js 的语法,对班级列做行列循环,然后获取名次 <=3 的行号,从而获取对应的学号,这里只是返回前三名,但是前三名的学号并不是第一的排最前边,如果要按照顺序,这个 js 脚本要写的比较复杂,这里就不做过多设置。
名次进步最快的三个同学,也是用格间计算 JavaScript 脚本方式,可以做出来,但是需要比较多的脚本来支持了,更多的是考验报表开发人员的变成能力了,这里就不做验证了。
注:这两行总结行虽说前边班级分组做了合并单元格,这里也要手动设置下纵向父单元格,否则无法做到跟随扩展。
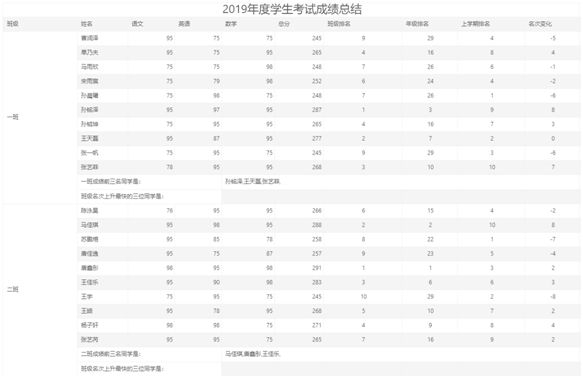
运行结果
完成后点评
1、 用时约四小时,格间计算那几个单元格处理时间较长,比较考验开发能力,如果加上名次上升最快三位,需要更长时间。
2、 内置统计模型丰富,比如这里做排名,直接用内置方法排名计算就行,除了排名外还有其他方法供使用。
3、 组合数据集设置比较方便,这样可以将当年和上期数据在数据集阶段可以合成一个,可以不用再报表中关联。
4、 中文字典显示和排序不方便,比如班级在数据库中存的数字,想显示中文的话现在是在数据集里新增了键值映射,或者要通过字典表关联。报表单元格里要想显示中文,必须用中文字段,但是排序就会按照中文排序,要手动去调整,如果班级不固定,比较难调。
5、 单元格间计算不方便,比如和上学期的名次变化,在类 Excel 的开发工具中,直接引用单元格名称就可以一,但永洪只能用格间计算,并且里边要用自己的坐标方式,使用起来不太方便。
6、 做一些单元格汇总时,只能写格间计算,里边写入 javascript 脚本,虽说很灵活,但是难度较高,复杂的需要较多代码,开发周期长,多报表开发人员的技术水平要求更高
亿信
制作过程
1、 配置并链接数据源
2、 设置参数及数据集
2.1、 增加参数“nd”。
2.2、 在数据集中添加主题表,亿信报表计算时会根据报表单元格的设置生成 SQL 从主题表中取数,本例要取今年和去年数据,所以数据集中要取两年数据,直接用 SQL:select * from xscj where nd=<#=@nd#> or nd+1=<#=@nd#>
3、 设计报表模板

核心设置:
3.1 班级内部排名:=F3.rank
3.2 年级间排名:=F3$$.rank(F3),本例中只有两层排名,班级排名是最内层排名,年级排名是最外层排名,两个排名使用 rank 函数就行,如果中间还有其他层级需要排名,就不能这么做了,需要增加辅助单元格,下面通过一个省、市、县三级来看下多层级排名的使用。
县排名和省排名,一个是最内层一个是最外层,所以表达式就是之前提到的,而市级排名需要增加辅助行,第三行,首先将 A2 和 A3 合并,这个就相当于其他工具的左主格设定,然后在 E3 单元格中写入表达式:=GRID1.E2$.join(“,”),取当前省内对应的 E2 的值拼成一个字符串,然后在市排名的 G2 单元格中写入表达式:=asstr(GRID1.E3).split(“,”).rank(E2),取 E3 的值按逗号分割后排序回填到对应位置。**
3.3 报表中要取当前学期和上学期的数据,在《多源关联分片》测试中看到,亿信多源关联会有些限制,所以本例中并没有采用润乾或者帆软那种多数据集形式,而是在数据集中取出了两年的数据,然后在报表单元格里加指标限定条件,比如上学期数据配置指标的过滤条件: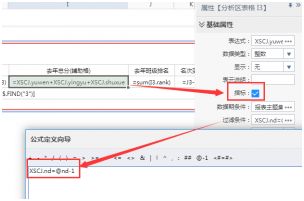
3.4 获取成绩前三名同学学号:=B3[G3[G3.FIND(“1”)]+“,”+B3[G3[G3.FIND(“2”)]+“,”+B3[G3[G3.FIND(“3”)],B3[G3[G3.FIND(“1”)] 表达式含义:班级是个合并格,G3.FIND(“1”)表示取出当前班级内的G3等于1的值所在的位置,然后B3.FIND(“1”)表示取出当前班级内的G3等于1的值所在的位置,然后B3[] 根据这个位置取到对应 B3 的值,也就是取到排名第一的人的姓名,其余类似。
3.5 班级名次上升最快的三位同学学号:=K3$.sort().mid(0,3).select(true,@.leftcell(9).txt).join(“,”),其中,.sort 是将 K3 浮动出来的数据降序排序,mid(0,3) 是取排序后的前三项(即前三名),select 的作用的取这前三名对应的 B2 表元的值(字号列),join 是把前面返回的结果用逗号隔开转成字符串
运行结果
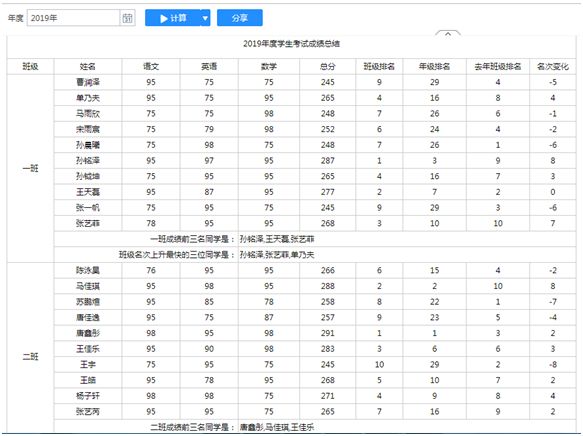
完成后点评:
1、 制作用时:1.5 小时
2、 内置排名函数比较丰富,可以直接使用实现排名计算;求前 N 条最大值等操作
3、 各个指标(科目成绩)之间可以划定不同的条件范围,可以直接取出来去年的数据。
4、 ID 转 NAME 时只能通过维表设置,也就是必须在数据库中额外添加一个码表,显示值配置不简便灵活;
5、 rank 函数只支持重复排名,_rk 虽然可以实现不重复排名,但是会改变数据的结果顺序,而且只支持指标字段,不支持具体的单元格 / 表元;
6、 本例取两个学期的数据对比,可以制作两个数据集通过关联字段关联在一起,也可以直接在数据集中取出两学期数据,然后在报表单元格通过年度参数进行数据过滤,亿信这里采用的是后者,在单元格中加条件来限定是取今年成绩还是去年成绩,当然这个其他工具也都支持,就是一个单元格过滤。
7、 没有层次坐标体系。两级排名还可以用相对固定的方法,比如最内层:=F3.rank,最外层:=F3$$.rank(F3)。如果还有更多层,那么需要增加辅助单元格取这个层级下需要排名的数值,比如数值在 E2 单元格中,那么需要在辅助单元格中(比如 E3)写入:=GRID1.E2$.join(“,”)****,这个是获取到当前层级下的 E2 的值用逗号做为分割符拼接在一起,然后在需要显示的排名的地方写入:=asstr(GRID1.E3).split(“,”).rank(E2),这样才能生成排名,如果层级还增多的话,那么需要大量的辅助单元格,操作上会相当繁琐。
总结
本例大体还是能延续上一例《多源分片报表》的结论:
-
这个例子也是各家产品都能实现,基本的排名运算都没有问题。
-
对于本例中重点考查的跨行组运算,润乾与帆软都提供了较完善的层次坐标机制,对付这种格间运算毫无压力。Smartbi 也有类似的概念,但语法体系设计得很烦琐,写起来复杂度要高很多。而永洪就没有层次坐标体系了,应对这种跨行组的格间运算比较吃力,需要写出有过程的 js 代码,可以说对格间运算基本就没有像样的支持,和前面三款产品的差距相当大。亿信看起来实现比较简单,但其实也没有层次坐标体系来应对通用的跨行组运算模型,只是凑巧有这样几个内置函数,深究下来,和永洪是一个档次的,只是因为有内置函数而略微胜出。也就是说,润乾和帆软在这方面属于成熟产品,Smartbi 基本算是及格,而永洪和亿信都不能算及格了,永洪更弱一点。
-
润乾和帆软相比,报表扩展与引用模型区别不大,但计算模型却有差距。润乾增加了特有的计算引擎,对于更复杂的运算情况就会有明显优势了(本例中的 esproc 函数)。帆软复制了润乾报表模型大部分内容,但计算引擎是润乾后加的,而且内容非常丰富,就没有那么容易复制过去了。
相关链接
报表工具对比选型系列用例——多源分片报表