深度学习CTR模型粗略记录
深度学习CTR模型粗略记录
- RoadMap
- FM:Factorization Machines
- DNN:Embedding+MLP
- WND:Wide & Deep Learning for Recommender Systems
- NFM:Neural Factorization Machines for Sparse Predictive Analytics
- AFM: Attentional Factorization Machine
- IAFM: Interaction-aware Factorization Machines
- DeepFM:A Factorization-Machine based Neural Network for CTR Prediction
- DCN:Deep & Cross Network for Ad Click Predictions
- xDeepFM:Combining Explicit and Implicit Feature Interactions for Recommender Systems
- AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
- 模型比较
- 参数对比
- 模型联系
- 模型总结
这段时间整理了一点深度学习在CTR中的应用,便有了一点中间产物,弃之可惜,就贴出来了,表述不当之处,供参考。
flag就不乱立了,立了我也不会做到,有空就补充和修改,嗯。
以下是不正经的正文
RoadMap
在计算广告和推荐系统中,点击率预估(Click Through Rate,简称CTR)是一个热点研究问题。CTR任务是根据用户特征、广告特征和其他可获取信息来预测一个用户是否会点击这条广告。传统的CTR通过大量的特征工程来提高预测效果,这样的工作费时费力,且构造过程不具有通用性。近年来深度学习在图像、NLP、广告等领域大放异彩,因其能够构造高阶特征,深度学习在点击率预估任务也开始崭露头角。 典型的四段式深度学习CTR模型结构为:输入模块、嵌入模块、特征提取模块、输出模块。
-
输入模块
输入通常是一个包含特征ID(如用户ID、内容特征ID)和对应特征值的序列。
输出是从特征提取模块提取到的信息经过一系列变换(求和、降维)并经过Sigmoid函数得到范围在(0,1)的实数,该实数表示点击的概率大小。 -
嵌入模块
在CTR任务中数据特征呈现高维、稀疏的特点,如用户ID、商品(广告)ID。
假设特征数为n,直接将这些特征进行One-Hot Encoding会产生巨大的参数数量( O ( n 2 ) , n O(n^2),n O(n2),n是特征数)。
Embedding通过矩阵乘法将1×n的离散特征向量通过维度为n×k的参数矩阵W压缩成1×k的低维度稠密向量,通常k≪n,特征数从 n 2 n^2 n2降到n×k,Embedding可以减小模型复杂度。
此外CTR任务涉及的特征通常是具有领域信息的离散特征,如用户性别、职业、广告(商品)类型等等。
实际应用中通常考虑领域特征的先验知识,将同领域的特征嵌入向量求和(或求平均)作为该领域的嵌入向量,再与其他领域的嵌入向量进行两两组合。
这种分领域嵌入方式得到的分组嵌入向量拼接起来作为后续神经网络的输入, 可以达到降维的目的。 -
特征提取模块
特征提取模块是模型的核心,不同模型特征交互(组合)形式不同。
CTR中经过特征工程得到的有效特征通常包含叉乘特征。
假设特征 x 1 = ( e 1 , e 2 , e 3 ) x_1=(e_1,e_2,e_3) x1=(e1,e2,e3),特征 x 2 = ( e 4 , e 5 , e 6 ) x_2=(e_4,e_5,e_6) x2=(e4,e5,e6),特征 x 1 x_1 x1、 x 2 x_2 x2的叉乘组合特征向量为 ( e 1 × e 4 , e 2 × e 5 , e 3 × e 6 ) (e_1×e_4,e_2×e_5,e_3×e_6) (e1×e4,e2×e5,e3×e6)。
从叉乘特征出发可以将特征交互形式分为
(1)显式特征交互、隐式特征交互
给定的CTR模型,特征经过一系列变化后可以得到诸如 e 1 × e 4 、 e 2 × e 5 、 e 3 × e 6 e_1×e_4、e_2×e_5、e_3×e_6 e1×e4、e2×e5、e3×e6形式,则认为该模型存在显式特征交互过程,否则只具有隐式特征交互过程.
(2)element-wise级特征交互、vector-wise特征交互
将embedding vector中的每个元素称为一个element。
特征经过一系列变化后可以得到诸如 w × ( e 1 × e 4 , e 2 × e 5 , e 3 × e 6 ) = ( w × e 1 × e 4 , w × e 2 × e 5 , w × e 3 × e 6 ) w×(e_1×e_4,e_2×e_5,e_3×e_6 )=(w×e_1×e_4,w×e_2×e_5,w×e_3×e_6 ) w×(e1×e4,e2×e5,e3×e6)=(w×e1×e4,w×e2×e5,w×e3×e6)形式,则认为该模型存在vector-wise交互过程.
若得到 ( w 1 × e 1 × e 4 , w 2 × e 2 × e 5 , w 3 × e 3 × e 6 ) (w_1×e_1×e_4,w_2×e_2×e_5,w_3×e_3×e_6 ) (w1×e1×e4,w2×e2×e5,w3×e3×e6),其中 w 1 ≠ w 2 ≠ w 3 w_1 \neq w_2\neq w_3 w1=w2=w3,则认为该模型只存在element-wise级特征交互过程。
备注:笔者觉得叉乘特征不合适,虽然大家都这么叫,待修改;xdeepfm论文里面是bit-wise不合适,改成element-wise。
FM:Factorization Machines
设计思路
引入二阶交叉特征来提高线性回归模型的泛化表达能力。
模型理解
通过穷举所有的二阶特征(一阶特征两两组合)并结合特征的有效性(特征权重)来预测点击结果。
实现细节
FM的二阶特征组合过程可拆分成Embedding和内积两个步骤。

模型特点
和LR模型相比增加了显式二阶特征,但本质上还是线性模型,无法构造更高阶的特征.
模型延伸
通过预训练FM初始化Embedding值的深度学习模型在一些任务上能够达到快速收敛的效果,
例如FNN基于Embedding+MLP的模型框架,利用预训练FM来初始化Embedding层参数,后面不断堆叠全连接层得到预测的点击率.
DNN:Embedding+MLP
设计思路:
MLP网络结构具有学习高阶特征的能力.
网络结构:

模型特点
能够隐式方式学习到高阶特征,缺乏更有意义的特征交互.
WND:Wide & Deep Learning for Recommender Systems
设计思路
同时考虑低阶特征和高阶特征.
模型理解
Wide部分用LR模型学习样本中的高频部分.
Deep部分用plain-DNN 模型增强模型的泛化能力.网络结构:
网络结构:

实现细节:
Wide部分需要特征工程提取低阶特征再送入LR模型中.
模型特点:
能够同时训练一阶特征和隐式高阶特征,缺乏更有意义的特征交互.
模型延伸:
WND可以看成是LR模型和plain-DNN模型的并联结构.
NFM:Neural Factorization Machines for Sparse Predictive Analytics
设计思路
结合FM和DNN的特点,利用FM二阶特征信息构造高阶特征。
网络结构(Deep部分)
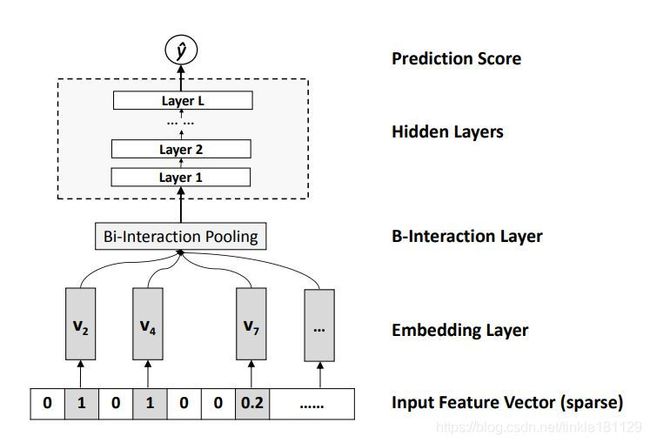
实现细节
BI-Interaction Pooling层主要工作是对特征Embedding两两进行pair-wise product操作。
形成同维度的向量后输入到MLP中(即Hidden Layer)。
Inner Product操作等价于BI-Interaction层后面叠加一个维度为k×1、值为1的全连接层。
模型特点
Deep部分引入二阶特征交互信息。
与WND相比,MLP层输入维度从f×k降为k,具有潜在的信息损失风险。
模型延伸
NFM可以看成是FM(二阶部分)和MLP的串连结构,MLP只有一层且参数固定为1时,NFM退化为FM。
与WND相比,NFM在Embedding层和MLP层中多添加了BI-Interaction Pooling Layer。
AFM: Attentional Factorization Machine
设计思路
通过FM构造出的二阶交叉特征重要性不同。
网络结构

实现细节
利用Attention机制计算二阶交叉特征的重要性。
AFM比FM更容易过拟合,需要用Dropout和L2正则。
模型特点
AFM比FM更容易过拟合。
模型延伸
AFM可以看成是带权的FM.
IAFM: Interaction-aware Factorization Machines
设计思路
二阶交叉特征重要性不仅与二阶特征有关,还与原一阶特征所在特征组有关。
网络结构

实现细节
特征层面,利用Attention机制计算二阶交叉特征的重要性。
特征组层面,通过网络学习特征所在特征组之间的重要性向量。将组合特征的embedding与重要性向量按位相乘,再和组合特征的注意力分数加权求和作为Attention Net部分的输出。
模型特点
和IAFM相同。
模型延伸
没有特征组层面,IAFM退化为AFM。
DeepFM:A Factorization-Machine based Neural Network for CTR Prediction
设计思路
用FM替代WND中的LR,同时学习低阶组合特征和高阶组合特征。
网络结构
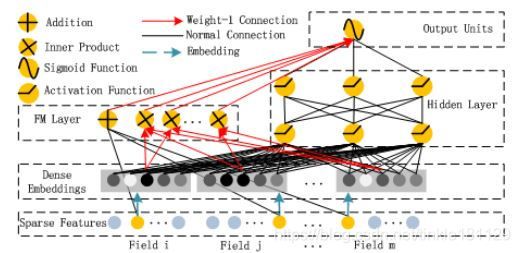
实现细节
FM的二阶部分和Deep部分共享Embedding。
模型特点
同时学习低阶组合特征(二阶)和高阶组合特征.
模型延伸
DeepFM是FM和plain-DNN的并联结构
和WND的区别在于Wide部分WND是人工特征+LR,DeepFM是网络联合训练的FM.
DCN:Deep & Cross Network for Ad Click Predictions
设计思路
借鉴FM构造显式特征过程,构造显式的高阶特征。
网络结构

模型理解
FM模型是特征f_1和f_2进行pair-wise product构建出显式二阶交叉特征.
在Cross Network中将特征f_1和f_2拼接在一起形成一个向量x_0,
通过x_0 x_0^T做笛卡尔积以获得显式二阶特征信息.
实现细节
Cross network的每一层的输出的构建过程为
先叉乘:维度为d的x_0与第l层输入x_l做笛卡尔积,构造出l+1阶的特征叉乘组合(d×d矩阵);
后投影:将d×d特征叉乘矩阵通过d×1的列向量w投影成一个d×1的列向量,这个过程将d×d的参数个数降低到d,实现叉乘特征之间的参数共享。
再加输入信息:受残差网络的影响,每层函数拟合的是x_(l+1)-x_l的残差,且通过将输入加到输出结果中保留了上一层的特征信息,即第l层的输出特征信息包括一阶至l+1阶特征。
模型特点
能够构造显式特征交互.
Cross Layer表达能力有限.
xDeepFM:Combining Explicit and Implicit Feature Interactions for Recommender Systems
设计思路
实现自动学习显式的高阶特征交互,同时使得交互发生在向量级上。
网络结构

实现细节

模型特点
能够挖掘vector-wise显式特征。
模型效率不佳。
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
设计思路
通过Multi-head注意力机制将特征投射到多个子空间中,在不同的子空间中捕获不同的特征交互。
网络结构
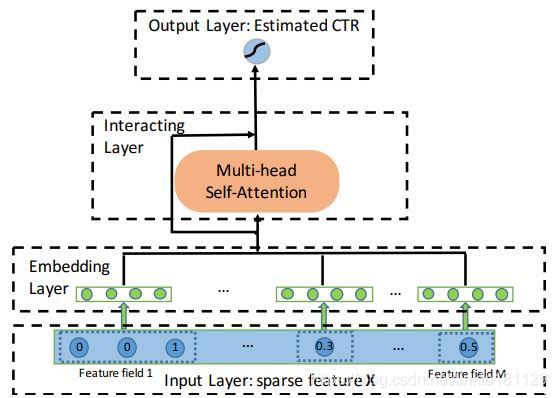
模型比较
参数对比

模型联系

模型总结
| 模型 | 特征形式 | 特征组合方式 |
|---|---|---|
| LR | 显式一阶 | - |
| FM | 显式一阶+显式二阶 | vector-wise |
| AFM | 显式一阶+显式二阶 | vector-wise |
| IAFM | 显式一阶+显式二阶 | element-wise |
| WND | 显式一阶+隐式高阶 | element-wise |
| NFM | 显式一阶+隐式高阶 | element-wise |
| DeepFM | 显式一阶+显式二阶+隐式高阶 | vector-wise、element-wise |
| DeepAFM | 显式一阶+显式二阶+隐式高阶 | vector-wise、element-wise |
| DeepIAFM | 显式一阶+显式二阶+隐式高阶 | vector-wise、element-wise |
| DCN | 显式高阶+隐式高阶 | element-wise |
| xDeepFM | 显式一阶+显式高阶+隐式高阶 | vector-wise、element-wise |
| AutoInt | 显式高阶 | vector-wise |
备注:模型总结这边还没想好,可能有错,或者说xdeepfm里的wise分类方法本身有点问题,实际上AutoInt也是考虑特征组的信息,以特征向量的形式去构造新的特征的。
通过对比实验,可以得到以下四个方面的体会
(1) 构造vector-wise级的显式特征可以逼近CTR特征工程中特征组合的操作,挖掘该类特征能够放大神经网络的预测能力
(2) 低阶和高阶特征的联合训练方式能够提升模型性能
(3) 考虑特征之间的关联性进行特征组合能够提升模型性能
(4) 模型选取也要因数据而异,不存在一种模型在所有数据集上表现最优
over