Hibernate学习(一)
Hibernate学习(一)
目录:
1、Hibernate对于MySQL数据库主键生成的支持:
2、复合主键Could not get constructor for org.hibernate.persister.entity.SingleTableEntityPersister报错处理:
3、hbm2ddl.auto属性值的含义及作用:
4、报错:Caused by: org.hibernate.hql.internal.ast.QuerySyntaxException: customer is not mapped from customer at处理:
5、原生SQL查询、更新字段:
6、配置文件的细节:
7、报错There is insufficient memory for the Java Runtime Environment to continue.处理:
1、Hibernate对于MySQL数据库主键生成的支持:
(1)native:hibernate会根据数据库类别,使用其原生的主键生成方式。

图1.1 截图1
测试样例:

图1.2 截图2
运行两次,在数据库中得到如下结果:

图1.3 截图3
对于MySQL数据库,指定native则会使用MySQL数据库原生auto_increment的主键生成机制。
(2)hilo:hibernate使用high/low算法来生成主键。Hibernate本身会维护一个默认名为hibernate_unique_key的表,用来生成主键,

图1.4 截图4
hibernate_hilo:指定保存hi值的表名
next_hi:指定保存hi值的列名
100:指定低位的最大值
max_lo若不设,则默认值为32767
将测试样例重新运行两次,在数据库中得到如下结果:

图1.5 截图5

图1.6 截图6
high/low算法核心思想:
①获得hi值:读取并记录数据库的hibernate_unique_key表中next_hi字段的值,数据库中此字段值加1保存。
②获得low值:从0到max_lo循环取值,差值为1,当值为max_lo值时,重新获取hi值,然后low值继续从0到max_lo循环。
③根据公式 hi * (max_lo + 1) + lo计算生成主键值。
注意:当hi值是0的时候,那么第一个值不是0*(max_lo+1)+0=0,而是lo跳过0从1开始,直接是1、2、3……
所以next_hi的初始值默认为0,所以第一次运行得到主键值1,2,3。第二次运行1*(100+1)+0=101,1*(100+1)+1=102,1*(100+1)+2=103。
(3)uuid.hex:该方式会根据网址、当时的时间戳(timestamp)等条件,生成一个32位的主键。适用于跨数据库的应用,即应用系统存在两个以上的数据库,并且需要共享全局性的标识符。
首先将Customer的id属性由Long类型转换为String类型,再运行测试程序两次,结果如下:

图1.7 截图7
(4)identity:使用数据库自增(auto_increment)的主键生成方式。
首先将Customer的id属性由String类型转换回Long类型,运行测试程序两次,得到如下结果:

图1.8 截图8
(5)assigned:主键的生成方式完全由应用程序控制(生成和赋值)。这种方法应该尽量避免。
2、复合主键Could not get constructor for org.hibernate.persister.entity.SingleTableEntityPersister报错处理:

图2.1 截图9
Could not get constructor for org.hibernate.persister.entity.SingleTableEntityPersister
解决方式:Entity中的属性名,
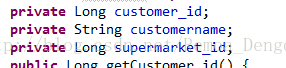
图2.2 截图10
配置文件中的属性名:

图2.3 截图11
二者命名更正相同后,再次运行,报错如下:

图2.4 截图12
A different object with the same identifier value was already associated with the session :
因为hibernate要求实体类的复合主键重写equals和hashCode方法,以作为不同数据间的识别标志。
在pom.xml文件中加入依赖包。
然后在实体类中重写hashCode和equals方法,
@Override
public int hashCode() {
return new HashCodeBuilder(-528253723, -475504089).appendSuper(super.hashCode()).append(this.supermarket_id).append(this.customer_id).toHashCode();
}
@Override
public boolean equals(Object obj){
if(!(obj instanceof Customer)){
return false;
}
Customer customer = (Customer)obj;
return new EqualsBuilder().appendSuper(super.equals(obj)).append(this.customer_id, customer.customer_id).append(this.supermarket_id, customer.supermarket_id).isEquals();
}
同时也要求复合主键不能相同,以及复合主键的任一主键的值不能为空。
![]()
图2.5 截图13
修改完错误后,运行测试代码:

图2.6 截图14
运行结果如图:

图2.7 截图15
问题解决。
3、hbm2ddl.auto属性值的含义及作用:
①create:每次加载hibernate时都会删除上一次生成的表,然后根据实体类再重新生成新表,哪怕两次没有任何改变也要这样执行。
②create-drop:每次加载hibernate时根据实体类生成表,但sessionFactory一关闭,表就自动删除。
③update:第一次加载hibernate时会根据实体类自动建立起表的结构,以后加载hibernate时根据实体类自动更新表结构,但即使表结构改变了但表中的行仍然存在不会删除以前的行。
④validate:每次加载hibernate时,验证创建数据库表结构,如果不一致就抛异常。只会和数据库中的表进行比较,不会创建新表,但会插入新值。
4、报错:Caused by: org.hibernate.hql.internal.ast.QuerySyntaxException: customer is not mapped from customer at处理:
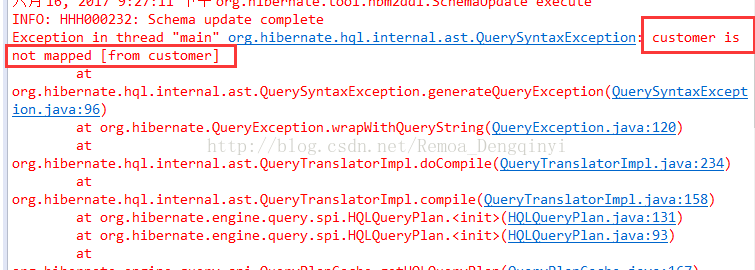
图4.1 截图16
定位到源代码以及xml文件
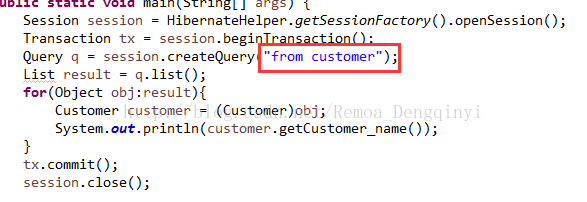
图4.2 截图17
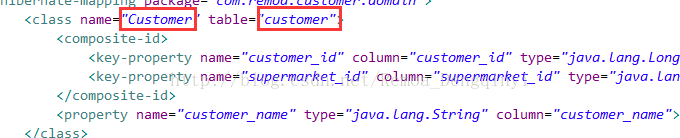
图4.3 截图18
应该与class中的name名大写Customer匹配,而不是与表名小写customer匹配。
修改后运行结果如下:

图4.4 截图19
问题解决。
5、原生SQL查询、更新字段:
(1)执行SQL查询步骤如下:
①获取Hibernate Session对象
②编写SQL语句
③通过Session的createSQLQuery方法创建查询对象
④调用SQLQuery对象的addScalar()或addEntity()方法将选出的结果与标量值或实体进行关联,分别用于进行标量查询或实体查询
⑤如果SQL语句包含参数,调用Query的setXxxx方法为参数赋值
⑥调用Query的list方法返回查询的结果集
(2)查询部分字段第一种方式:

图5.1 截图20
addScalar:仅仅需要选出某个字段的值,而不需要明确指定该字段的数据类型时,可以用addScalar(String columnAlias)
运行结果如下:

图5.2 截图21
(2)查询部分字段第二种方式:

图5.3 截图22
Transformers.aliasToBean(target) //把结果通过setter方法注入到指定的对象属性中
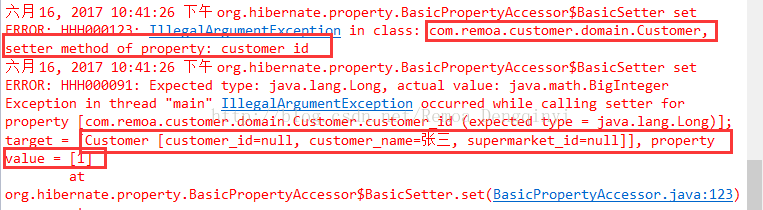
图5.4 截图23
报错是由于数据库定义为bigInt类型,而实体定义为Long类型,利用hibernate进行实体映射报错。需要将实体类的Long类型改为BigInteger类型。
(3)使用原生SQL语句进行查询:
①session.createSQLQuery(sql).addEntity(XXX.class).addScalar(“列名”);必须用select * from customer或者select {a.*},{b.*} from a,b where的形式查询
②session.createSQLQuery(sql).setResultTransformer(Transformers.aliasToBean(XXX.class);支持查任意的列
(4)原生SQL语句进行更新:

图5.5 截图24
运行结果如下:

图5.6 截图25
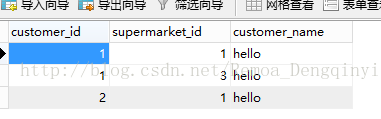
图5.7 截图26
6、配置文件的细节:
(1)自动添加包名:

图6.1 截图27
(2)设置只读:
①在class中声明mutable=”false” 或 @Immutable
这意味着对该类的更新将会被忽略,不过不会抛出异常,只允许有增加和删除操作。
在class中声明mutable=”false”:insert=允许,delete=允许,update=不允许
②在集合中声明mutable=”false” 或 @Immutable
这意味着在这个集合中插入记录或删除孤行是不允许的,否则会抛出异常。只允许更新操作。不过,如果启用级联删除的话,当父类被删除时,其所有子类也将被删除,即使它是mutable的。
在集合中声明mutable=”false”:insert=不允许,单行删除=不允许,delete=允许,update=允许
(3)运行期动态生成SQL:
生成的SQL仅包含真正需要变动的字段
生成的SQL仅包含真正需要新增以及更新的字段。
7、报错There is insufficient memory for the Java Runtime Environment to continue.处理:

图7.1 截图28
内存不足,连jre都运行不动了
图7.2 截图29
真尴尬,QQ都被挤退了。
图7.3 截图30
个人PC可能比较老了,给电脑减减负喘口气后eclipse就能够继续运行了。