在hadoopHA节点上部署kafka集群组件
文章目录
-
-
-
- 前言
- 1、Kafka的基本介绍
-
- 1.1 什么是kafka
- 1.2 kafka 应用场景
- 1.3 kafka相关术语
- 2、kafka 单点部署与测试
-
- 2.1 配置文件
- 2.2 启动kafka进程
- 2.3 测试topic
- 3、kafka集群部署与测试
-
- 3.1 配置server.properties
- 3.2 集群测试
- 3.3 在zk上查看集群情况
- 4、 小结
-
-
前言
在前面的文章中《在hadoopHA节点上部署flume高可用组件 》已经介绍了flume实时收集acces.log,同时给出flume是如何实现数据流向的高可用环境测试。在后面的文章中会给出实时大数据项目的开发,实时数据源由flume sink到kafka的topic里,而不是前面提到的hdfs,目的是利用kafka强大的分布式消息组件用于分发来自flume的实时数据流。
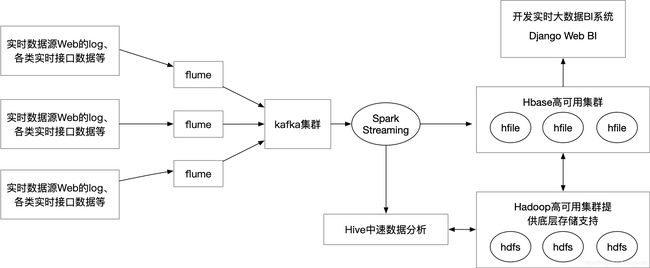
kafka集群在Hadoop实时大数据项目的位置,如下图所示:
1、Kafka的基本介绍
1.1 什么是kafka
Kafka 是一种分布式的,基于发布/订阅的消息系统(redis也可以实现该功能),主要设计目标如下:
以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。
支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
同时支持离线数据处理和实时数据处理。
Scale out:支持在线水平扩展。
1.2 kafka 应用场景
- 日志收集:可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer。不过在本文中,flume用于收集数据日志,kafka组件用于接受来自flume的event
- 流式处理:spark streaming,在上面的架构图也可以清楚看到kafka组件的下游为spark streaming,它消费来自kafka topic的实时数据消息。
- 消息系统:解耦生产者和消费者、缓存消息等。
- 用户活动跟踪:kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后消费者通过订阅这些topic来做实时的监控分析,亦可保存到hbase、mangodb等数据库。
- 运营指标:kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,
- 生产各种操作的集中反馈,比如报警和报告。
可以看出kafka在大数据实时处理以及互联网产品方面应用最为突出。
1.3 kafka相关术语
-
producer : 生产者,生产message发送到topic,例如flume sink就是生产者
-
consumer : 消费者,订阅topic并消费message, consumer作为一个线程来消费,例如实时处理的spark streaming。
-
Broker:Kafka节点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群,在大数据项目中,直接利用已有的hadoop节点服务器配置成kafka集群。整个 Kafka 集群架构会有一个 zookeeper集群,通过 zookeeper 管理集群配置,选举 kafka Leader,以及在 Consumer Group 发生变化时进行 Rebalance。
-
topic:一类消息,消息存放的目录即主题,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发
-
massage: Kafka中最基本的传递对象。
-
partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的segment以及index:partition在物理上已一个文件夹的形式存在,由多个segment文件组成和多个index文件,它们是很对出现,每个Segment存着message信息,每个index存放着message的offset
-
replica:partition 的副本,保障 partition 的高可用。个人建议写成replica partition–副本分区
-
leader:这里的leader要理解为某个partition 作为主分区,也即称为leader partition,要注意该partition所在的服务器不能称为leader,否认会被误认为是kafka集群的master服务器(Kafka把master服务器称为controller)。 producer 和 consumer 只跟 leader petition交互。
-
replicas:leader 角色的partition加上replica角色的partition,一起成为replicas,也就是该topic总共有多少个副本数,副本数包含一个主分区副本和其余的副本分区。
-
controller:为了避免更leader这个词混淆,开发者将kafka 集群中的其中一台服务器称为controller,用于对每个topic的partition leader选举以及实现对partition的failover。
-
consumer Group:消费者组,一个Consumer Group包含多个consumer
-
offset:偏移量,理解为消息partition中的索引
2、kafka 单点部署与测试
2.1 配置文件
目前官方kafka最新稳定版本为2.3.1
按官方建议以下建议,项目用到scala2.1.3,kafka用了官方的建议版本2.1.2
We build for multiple versions of Scala. This only matters if you are using Scala and you want a version built for the same Scala version you use. Otherwise any version should work (2.12 is recommended).
kafka组件同样被放置在/opt目录下,该目录放置所有Hadoop及其组件,便于统一管理
[root@nn opt]# ls
flume-1.9.0 hbase-2.1.7 kafka-2.12 scala-2.13.1
flume_log hive-3.1.2 mariadb-10.4.8 spark-2.4.4-bin-hadoop2.7 zookeeper-3.4.14
hadoop-3.1.2 jdk1.8.0_161 xcall.sh
配置server.properties。
[root@nn config]# vi server.properties
[root@nn config]# pwd
/opt/kafka-2.12/config
# The id of the broker. This must be set to a unique integer for each broker.
# 如果是kafka集群,需配置全局id
broker.id=10
############################# Socket Server Settings #############################
# 可以不设置,kafka自动获取hostname
listeners=PLAINTEXT://nn:9092
advertised.listeners=PLAINTEXT://nn:9092
############################# Log Basics #############################
# 最终存放消息的路径,建议放在kafka组件目录下,方便管理
log.dirs=/opt/kafka-2.12/kafka-logs
num.partitions=3
############################# Zookeeper #############################
zookeeper.connect=nn:2181,dn1:2181,dn2:2181/kafka-zk
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
已更新配置:zookeeper.connect=nn:2181,dn1:2181,dn2:2181
考虑到后面项目中,对kafka在zk上方便更为管理,用了新的配置:zookeeper.connect=nn:2181,dn1:2181,dn2:2181/kafka-zk
因为kafka默认在zk的根路径下创建多个节点路径,当需要去zk查看kafka相关的元数据时显得有点混乱,因此这里要求kafka将它要创建的所有znode都统一放在/kafka-zk这个路径下,方便集中查看和管理kafka的元数据,如下所示:
[zk: localhost:2181(CONNECTED) 0] ls /kafka-zk
[cluster, controller_epoch, controller, brokers, admin, isr_change_notification, consumers, log_dir_event_notification, latest_producer_id_block, config]
本文后面内容所有kafka命令中,若有--zookeeper nn:2181 这样启动参数,都需要改为--zookeeper nn:2181/kafka-zk
2.2 启动kafka进程
[root@nn kafka-2.12]# bin/kafka-server-start.sh config/server.properties
启动后提示内存不足
“There is insufficient memory ”
因为kafka的启动脚本为最大堆申请1G内存,由于使用虚拟机跑项目,资源有限,将 kafka-server-start.sh的export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"修改为export KAFKA_HEAP_OPTS="-Xmx256M -Xms128M",最大堆空间为256M,初始堆空间为128M。
使用后台进程方式启动kafka服务
[root@nn kafka-2.12]# bin/kafka-server-start.sh -daemon config/server.properties
# 通过jps也可以看到kafka进程
[root@nn kafka-2.12]# jps
4609 QuorumPeerMain
14436 JournalNode
2454 HMaster
2552 Jps
14185 DataNode
15017 NodeManager
2365 Kafka
13983 NameNode
14879 ResourceManager
2.3 测试topic
创建无备份的topic,名称为hadoop,分区数1
[root@nn kafka-2.12]#bin/kafka-topics.sh --create --zookeeper nn:2181 --replication-factor 1 --partitions 1 --topic hadoop
Created topic hadoop.
查看新建的topic
[root@nn bin]# kafka-topics.sh --list --zookeeper nn:2181
hadoop
# 查看kafka在zookeeper上创建的topic znode上可以看到 hadoop这个topic
[zk: localhost:2181(CONNECTED) 2] ls /brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics
[hadoop]
启动producer进程,这是一个console,可以命令式发送message
[root@nn kafka-2.12]# bin/kafka-console-producer.sh --broker-list nn:9092 --topic hadoop
>hello kafka
>spark
新打开一个shell用于启动consumer进程,订阅hadoop这个topic,该进程会持续监听9092端口,一旦上面producer的console写入信息,这边consumer就会立刻打印同样信息。
[root@nn kafka-2.12]# bin/kafka-console-consumer.sh --bootstrap-server nn:9092 --topic hadoop
hello kafka
spark
查看hadoop这个topic的所在的物理文件
# 这里的hadoop-0就是hadoop topic的parition
[root@nn hadoop-0]# pwd
/opt/kafka-2.12/kafka-logs/hadoop-0
[root@nn hadoop-0]# ls
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex leader-epoch-checkpoint
有index、log文件,新版本的kafka还多了timeindex时间索引。至此完成kafka单节点的配置和测试。
3、kafka集群部署与测试
3.1 配置server.properties
kafka集群部署要求所在节点上已经运行zookeeper集群。
[root@nn config]# vi server.properties
# 每个节点id需唯一nn设10,dn1设11,dn2设12
broker.id=10
ip和端口这里可以不配置,kafka自动读取,也方便把整个kafka目录分发到其他节点上
#listeners=PLAINTEXT://:9092
# 存放的日志,kafka自动创建
log.dirs=/opt/kafka-2.12/kafka-logs
# 配置zk集群
zookeeper.connect=nn:2181,dn1:2181,dn2:2181
其他属性项基本是调优项目,这里不再一一给出,后面用单独一篇文章给出讨论。
将kafka-2.12目录拷贝到dn1和dn2节点上,修改对应的broker.id即可
3.2 集群测试
分布在三个节点上启动kafka服务
[root@nn kafka-2.12]# bin/kafka-server-start.sh -daemon config/server.properties
[root@dn1 kafka-2.12]# bin/kafka-server-start.sh -daemon config/server.properties
[root@dn2 kafka-2.12]# bin/kafka-server-start.sh -daemon config/server.properties
# jps可以看到每个节点上都已经有kafka进程
[root@nn opt]# sh xcall.sh jps |grep ka
10569 Kafka
12836 Kafka
28243 Kafka
创建一个新的topic:sparkapp,3份拷贝,3分区
[root@nn kafka-2.12]# bin/kafka-topics.sh --create --zookeeper nn:2181,dn1:2181,dn2:2181 --replication-factor 3 --partitions 3 --topic sparkapp
# 查看sparkapp主分区及其副本分区的情况
[root@nn kafka-2.12]# bin/kafka-topics.sh --describe --zookeeper nn:2181 --topic sparkapp
Topic:sparkapp PartitionCount:3 ReplicationFactor:3 Configs:
Topic: sparkapp Partition: 0 Leader: 10 Replicas: 10,11,12 Isr: 10,11,12
Topic: sparkapp Partition: 1 Leader: 11 Replicas: 11,12,10 Isr: 11,12,10
Topic: sparkapp Partition: 2 Leader: 12 Replicas: 12,10,11 Isr: 12,10,11
该命令其实就是读取/brokers/topics/sparkapp/partitions/**/state 所有分区的state节点值
[zk: localhost:2181(CONNECTED) 9] get /brokers/topics/sparkapp/partitions/0/state
{"controller_epoch":22,"leader":10,"version":1,"leader_epoch":0,"isr":[10,11,12]}
在nn节点启动producer进程,连接broker分别为nn自己、dn1节点和dn2节点,都能正常连接,同理,dn1、dn2的producer进程使用dn1、dn2、nn节点都能正常连接
[root@nn kafka-2.12]# bin/kafka-console-producer.sh --broker-list nn:9092 --topic sparkapp
>sparkapp
[root@nn kafka-2.12]# bin/kafka-console-producer.sh --broker-list dn1:9092 --topic sparkapp
>sparkapp
[root@nn kafka-2.12]# bin/kafka-console-producer.sh --broker-list dn2:9092 --topic sparkapp
>sparkapp
在nn节点启动producer进程,然后在dn1节点、dn2节点以及nn新shell分别启动consumer,看看一个producer生产msg,其他三个节点能否同时收到
[root@dn1 kafka-2.12]# bin/kafka-console-consumer.sh --bootstrap-server nn:9092 --topic sparkapp
[root@dn2 kafka-2.12]# bin/kafka-console-consumer.sh --bootstrap-server nn:9092 --topic sparkapp
[root@nn kafka-2.12]# bin/kafka-console-consumer.sh --bootstrap-server nn:9092 --topic sparkapp
查看kafka-cluster这个topic的partition在物理文件上的分布
[root@nn kafka-logs]# ls sparkapp-
sparkapp-0/ sparkapp-1/ sparkapp-2/
[root@nn kafka-logs]# ls sparkapp-0/
00000000000000000000.index 00000000000000000000.timeindex
00000000000000000000.log leader-epoch-checkpoint
可以看到三个分区对于三个文件目录,每个目录有索引文件和数据文件
3.3 在zk上查看集群情况
kafka在zk上的数据存储结构:
brokers列表:ls /brokers/ids
某个broker信息:get /brokers/ids/10
topic信息:get /brokers/topics/sparkapp
partition信息:get /brokers/topics/sparkapp/partitions/0/state
controller中心节点变更次数:get /controller_epoch
conrtoller信息:get /controller
[zk: localhost:2181(CONNECTED) 2] get /controller
{“version”:1,“brokerid”:10,“timestamp”:"***"},可以看到当前kafka集群的controller节点为nn服务器brokerid为10.
# 集群的brokers信息在/brokers持久节点下,ids节点用于存放上线的brokers id号,topics:集群上所有的topces都放在在节点下
[zk: localhost:2181(CONNECTED) 20] ls /brokers
[ids, topics, seqid]
# brokers在持久ids节点下注册临时节点,节点名称就是broker自己的id号,这里说明为何在server.properties里面的broker.id要设为唯一,因为利用zookeeper的临时节点以及保证节点命名唯一。
[zk: localhost:2181(CONNECTED) 19] ls /brokers/ids
[10,11,12]
# 获取其中一个broker id节点的信息,例如dn2这个broker
[zk: localhost:2181(CONNECTED) 24] get /brokers/ids/12
{
"listener_security_protocol_map":{
"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://dn2:9092"],"jmx_port":-1,"host":"dn2","timestamp":"*****","port":9092,"version":4}
# 查看sparkapp这个topics的分区数量
[zk: localhost:2181(CONNECTED) 8] ls /brokers/topics/sparkapp/partitions
[0, 1, 2]
# 查看当前kafka集群的leader状态,通过在topic的分区的state节点可以看到当前leader是节点dn1,对应的broker id为1
[zk: localhost:2181(CONNECTED) 36] get /brokers/topics/sparkapp/partitions/1/state
{
"controller_epoch":6,"leader":10,"version":1,"leader_epoch":2,"isr":[11,12,10]}
至此,完成Kafka的集群配置和测试
4、 小结
为hadoop环境配置kafka组件的过程相对简单,鉴于Kafka这个中间件具有非常不错应用价值,本blog继续用1到2篇文章深入探讨有关Kafka核心内容。此外还用另外一篇文章用于给出flume和kafka两者的整合——《flume集群高可用连接kafka集群》。