flume设计性能优化
目录
业务场景:
过程1(单flume):
过程2(多个flume并行处理):
过程3(多路复用(路由)模式):
下面一个flume的配置,和selector.header的java代码介绍
业务场景:
每五分钟会新生成一个2.4G左右的gz压缩文件,大概1680万条数据, 现在需要通过flume做数据的清洗,处理,然后写入kafka。
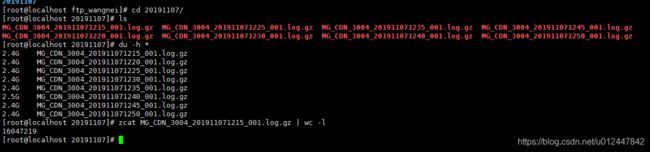
服务器环境: 1台 32核 125G内存的服务器。
考虑方案(费脑,疯狂测试)
代码思路:
自定义的source读取目录文件,消费数据解析,转换格式,写入channel,自定义source另外有一篇博客,这里暂不介绍。
自定义source有两种方式: PollableSource和EventDrivenSource。PollableSource自动轮询调用 process() 方法,从中取数据,EventDrivenSource是自己定义回调机制来捕获新数据并将其存储到 Channel 中
开始flume节点的思路:
过程1(单flume):
flume使用1个agent,1个source,1个channel,1个sink,消费数据
开始测试:
最开始channel使用的是file, 测试结果大概1秒几千, channel使用memory,测试性能大概是1秒2-3万的样子
太慢了,不行,需要优化-----------------------------------------------------------------
过程2(多个flume并行处理):
考虑开启多个flume来监控多个目录。这样就好并行处理,来来来开始上手
做法: 将压缩包解压,然后使用linux的split命令分隔成多个文件,然后放到多个目录中,这样就并行处理了,
缺点:但是解压时间长,解压之后2.4G的gz文件会变成10多G,会很占服务器的磁盘。
没磁盘呀,人也太懒,不想这么麻烦--------------------------------------------------
过程3(多路复用(路由)模式):
测试性能的时候,没有sink,只有source写入channel大概能用1秒5万,如果有sink写入kafka,这样1秒只有2万左右,所以并行量的瓶颈是sink写入kafka,
那么我考虑用多个sink消费一个source,这样就可以提升并发量。
开始疯狂百度,查看flume官网: http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html
找到了flume有一种机制, 多路复用(路由)模式,如下:

按照自己定义的方式可以将 一个source数据写入到不同的channel
最后长期测试大概1秒5-6万的数据量。
服务器的长期测试期间cpu和内存使用情况如下:


使用multiplexing方式就是,通过selector定义header, 比如数据的header中有一个State, 我将其值定义为AZ,则这个数据就会进入wangwu1Channel这个channel中;值为BZ,则这个数据就会进入wangwu3Channel这个channel中,如果不是AZ,BZ,CZ,最后会进入wangwu1Channel这个channel。
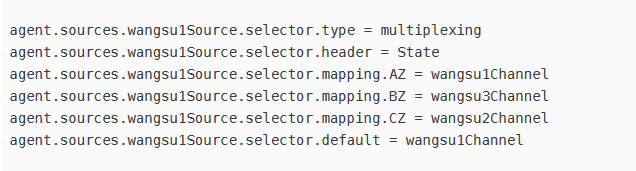
下面是一个flume的配置,和定义selector.header的java代码介绍
flume-conf.properties配置:
agent.sources = wangsu1Source
agent.sinks = wangsu1Sink wangsu2Sink wangsu3Sink
agent.channels = wangsu1Channel wangsu2Channel wangsu3Channel
agent.sources.wangsu1Source.type = com.mmtrix.source.MySource
agent.sources.wangsu1Source.channels = wangsu1Channel wangsu2Channel wangsu3Channel
agent.sources.wangsu1Source.check = /tigard/collector/apache-flume-1.6.0-bin/mvod/wangsu1log/checkpoint.conf
agent.sources.wangsu1Source.batchSize = 1048576
agent.sources.wangsu1Source.startTime = 2018041400
agent.sources.wangsu1Source.backupDir = /data1/wangnei
agent.sources.wangsu1Source.errorLog = /usr/local/errorLog.log
agent.sources.wangsu1Source.regex = (^MG_CDN_3004_)[0-9]{12}_(.+)(.log.gz$)
agent.sources.wangsu1Source.userId = 3004
agent.sources.wangsu1Source.logType = migu
agent.sources.wangsu1Source.resourceIds = 65
agent.sources.wangsu1Source.recordFileName = /tigard/collector/apache-flume-1.6.0-bin/mvod/wangsu1log/recordFileName.conf
agent.sources.wangsu1Source.selector.type = multiplexing
agent.sources.wangsu1Source.selector.header = State
agent.sources.wangsu1Source.selector.mapping.AZ = wangsu1Channel
agent.sources.wangsu1Source.selector.mapping.BZ = wangsu3Channel
agent.sources.wangsu1Source.selector.mapping.CZ = wangsu2Channel
agent.sources.wangsu1Source.selector.default = wangsu1Channel
agent.sinks.wangsu1Sink.type = com.mmtrix.sink.test2
agent.sinks.wangsu1Sink.channel = wangsu1Channel
agent.sinks.wangsu1Sink.topic = migulog_2_replica
agent.sinks.wangsu1Sink.requiredAcks = -1
agent.sinks.wangsu1Sink.batchSize = 10000
agent.sinks.wangsu1Sink.brokerList = mg001.mq.tigard.com:19092,mg002.mq.tigard.com:19092,mg003.mq.tigard.com:19092,mg004.mq.tigard.com:19092,mg005.mq.tigard.com:19092,mg006.mq.tigard.com:19092
agent.sinks.wangsu1Sink.kafka.compression.codec = snappy
agent.sinks.wangsu1Sink.kafka.producer.type = sync
agent.sinks.wangsu1Sink.serializer.class=kafka.serializer.StringEncoder
agent.channels.wangsu1Channel.type = memory
agent.channels.wangsu1Channel.capacity = 5000000
agent.channels.wangsu1Channel.transactionCapacity = 50000
agent.sinks.wangsu2Sink.type = com.mmtrix.sink.test2
agent.sinks.wangsu2Sink.channel = wangsu2Channel
agent.sinks.wangsu2Sink.topic = migulog_2_replica
agent.sinks.wangsu2Sink.requiredAcks = -1
agent.sinks.wangsu2Sink.batchSize = 10000
agent.sinks.wangsu2Sink.brokerList = mg001.mq.tigard.com:19092,mg002.mq.tigard.com:19092,mg003.mq.tigard.com:19092,mg004.mq.tigard.com:19092,mg005.mq.tigard.com:19092,mg006.mq.tigard.com:19092
agent.sinks.wangsu2Sink.kafka.compression.codec = snappy
agent.sinks.wangsu2Sink.kafka.producer.type = sync
agent.sinks.wangsu2Sink.serializer.class=kafka.serializer.StringEncoder
agent.channels.wangsu2Channel.type = memory
agent.channels.wangsu2Channel.capacity = 5000000
agent.channels.wangsu2Channel.transactionCapacity = 50000
agent.sinks.wangsu3Sink.type = com.mmtrix.sink.test2
agent.sinks.wangsu3Sink.channel = wangsu3Channel
agent.sinks.wangsu3Sink.topic = migulog_2_replica
agent.sinks.wangsu3Sink.requiredAcks = -1
agent.sinks.wangsu3Sink.batchSize = 10000
agent.sinks.wangsu3Sink.brokerList = mg001.mq.tigard.com:19092,mg002.mq.tigard.com:19092,mg003.mq.tigard.com:19092,mg004.mq.tigard.com:19092,mg005.mq.tigard.com:19092,mg006.mq.tigard.com:19092
agent.sinks.wangsu3Sink.kafka.compression.codec = snappy
agent.sinks.wangsu3Sink.kafka.producer.type = sync
agent.sinks.wangsu3Sink.serializer.class=kafka.serializer.StringEncoder
agent.channels.wangsu3Channel.type = memory
agent.channels.wangsu3Channel.capacity = 5000000
agent.channels.wangsu3Channel.transactionCapacity = 50000
按照自己定义的方式将一个source数据写入多个channel,我是使用随机的方式写入三个channel。

private List ChannelSelector = Arrays.asList("AZ", "BZ", "CZ");
// 随机选择
String selector = this.ChannelSelector.get((int) (Math.random() * this.ChannelSelector.size()));
logger.info("selector: " + selector);
for (byte[] value : mess) {
if (value.length != 0) {
logger.debug(value);
Event event = EventBuilder.withBody(value);
Map map = new HashMap();
map.put("State", selector);
event.setHeaders(map);
events.add(event);
}
}
System.out.println("==============" + String.valueOf(System.currentTimeMillis()/1000) + "===========read: " + events.size());
// 循环处理失败的批次,可能失败的原因是channel满了,写不进去
boolean loop = true;
while(loop) {
try {
getChannelProcessor().processEventBatch(events);
} catch(Exception e) {
logger.error("processEventBatch err:" + e.getMessage() + " sleeping 10s...");
try {
Thread.sleep(10000L);
} catch(Exception e1) {
logger.error(e1);
} finally {
continue;
}
}
loop = false;
}
mess.clear();
mess = null;
events.clear();