如何使用Cloudera Manager启用HDFS的HA
1.文档编写目的
在HDFS集群中NameNode存在单点故障(SPOF),对于只有一个NameNode的集群,如果NameNode机器出现意外,将导致整个集群无法使用。为了解决NameNode单点故障的问题,Hadoop给出了HDFS的高可用HA方案,HDFS集群由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。
Active NameNode可对外提供服务,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便在Active NameNode失败时快速的进行切换。本篇文章主要讲述如何使用Cloudera Manager启用HDFS的HA。
- 内容概述
1.HDFS HA启用
2.更新Hive Metastore NameNode
3.HDFS HA功能可用性测试
4.Hive及Impala测试
测试环境
1.CM和CDH版本为5.13.0
- 前置条件
1.拥有Cloudera Manager的管理员账号
2.CDH集群已安装成功并正常使用
2.启用HDFS HA
1.使用管理员用户登录Cloudera Manager的Web管理界面,进入HDFS服务
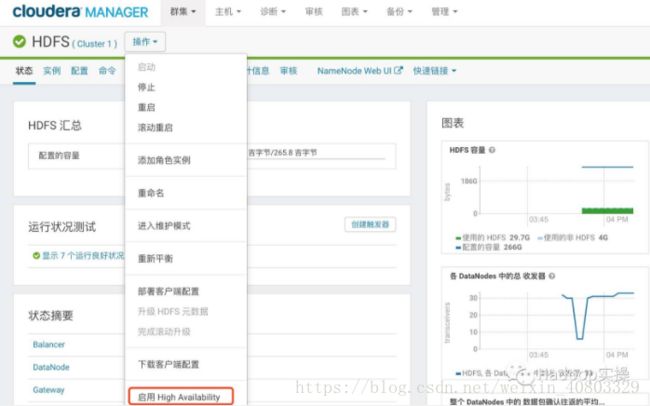
2.点击“启用High Avaiability”,设置NameService名称

3.点击“继续”,选择NameNode主机及JouralNode主机
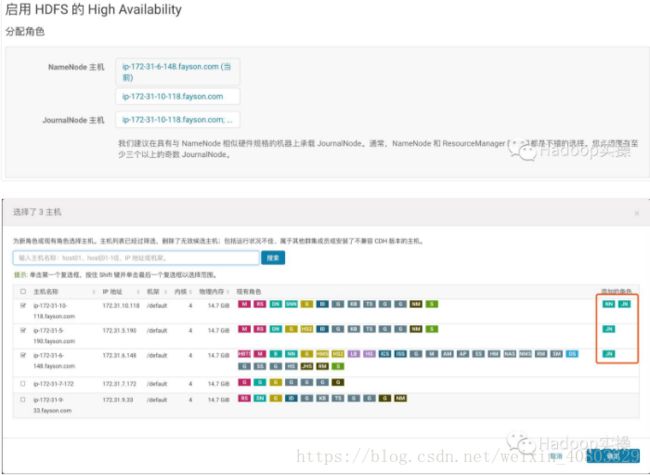
JouralNode主机选择,一般与Zookeeper节点一致即可(至少3个且为奇数)
4.点击“继续”,设置NameNode的数据目录和JouralNode的编辑目录
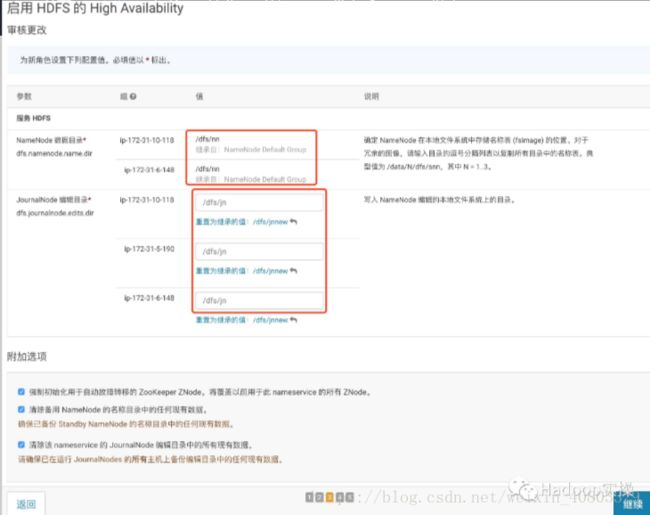
NameNode的数据目录默认继承已有NameNode数据目录。
5.点击“继续”,启用HDFS的High Availability,如果集群已有数据,格式化NameNode会报错,不用理。
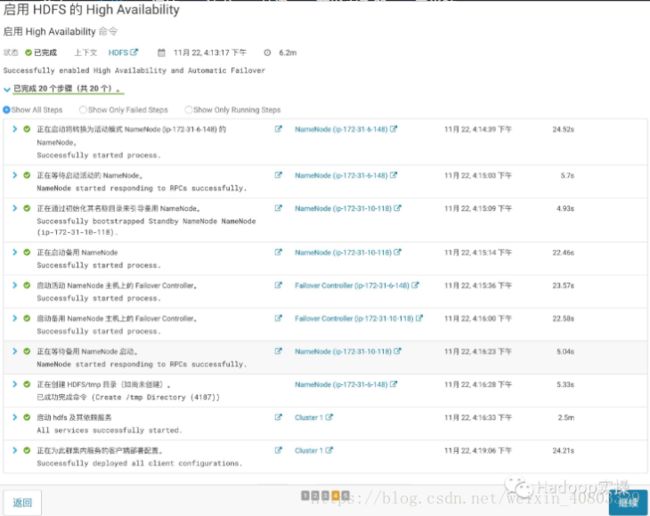
6.点击“继续”,完成HDFS的High Availability

7.HDFS实例查看
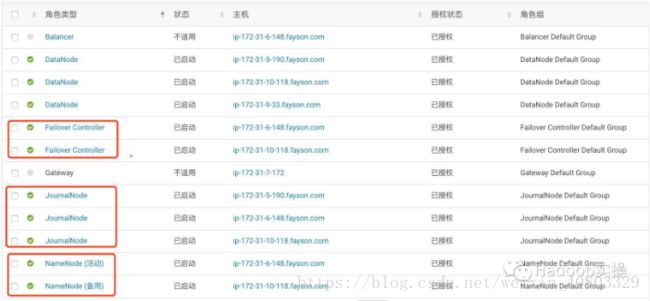
通过实例列表可以看到启用HDFS HA后增加了NameNode、Failover Controller及JouralNode服务并且服务都正常启动,至此已完成了HDFS HA的启用,接下来进行HDFS HA功能的可用性测试。
CM上HDFS HA的使用,可以通过界面进行手动切换
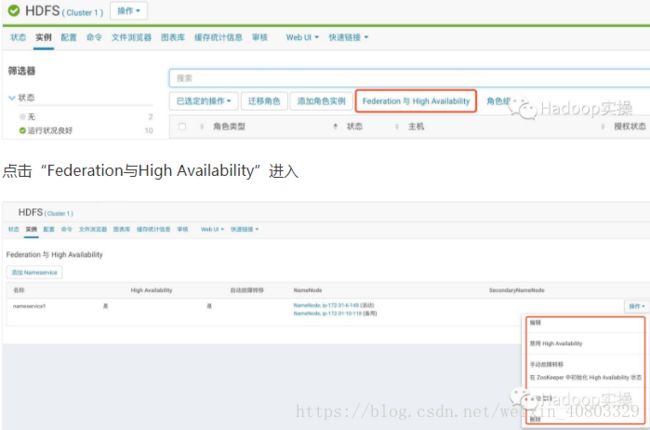
可以进行手动故障转移
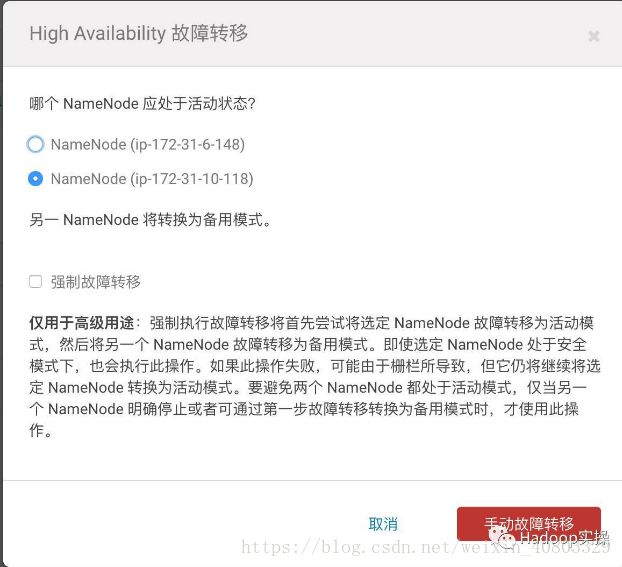
故障转移成功

![]()
3.更新Hive MetaStore NameNode
1.进入Hive服务并停止Hive的所有服务

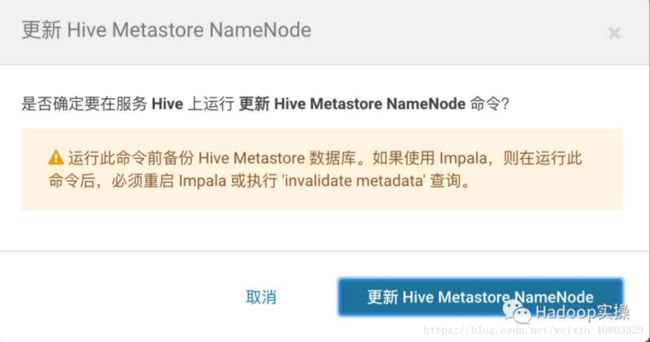
2.确认Hive服务停止后,点击“更新Hive Metastore NameNode”
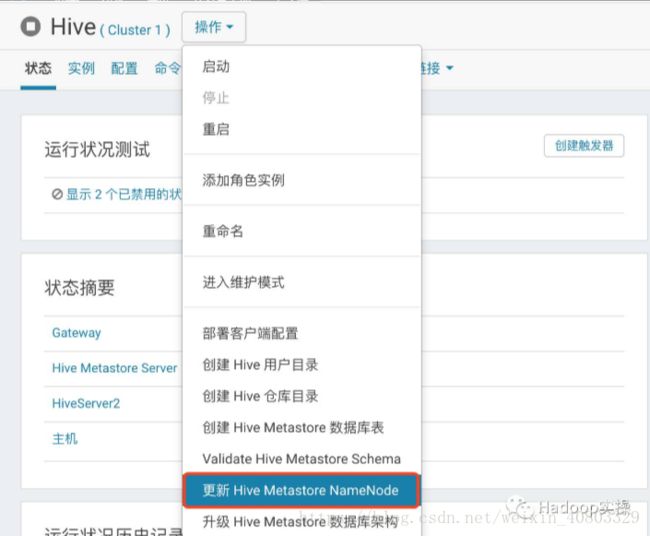
3.更新Hive Metastore NameNode
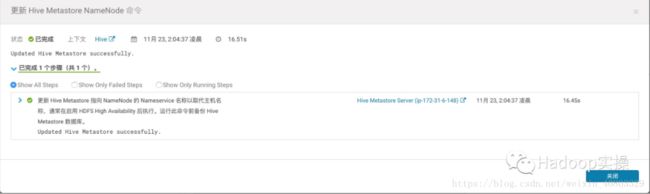
4.更新成功
5.启动Hive服务

完成HiveMetastore NameNode更新。
4.HDFS HA功能可用性测试
1.向集群目录put一个数据文件
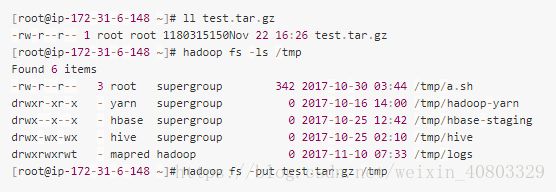
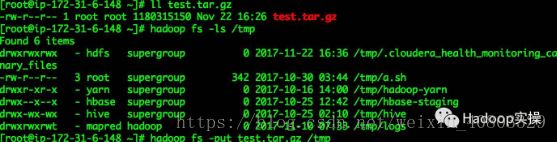
2.put文件的同时将Active NameNode服务停止,Put数据报错,但其实put任务没有终止。
[root@ip-172-31-6-148 ~]# hadoop fs -put test.tar.gz /tmp 17/11/22 16:38:18 WARN ipc.Client: Failed to connect to server: ip-172-31-10-118.fayson.com/172.31.10.118:8020: try once and fail. java.net.ConnectException: Connection refused at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method) at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:739) at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:530) at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:494) at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:648) at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:744) at org.apache.hadoop.ipc.Client$Connection.access$3000(Client.java:396) at org.apache.hadoop.ipc.Client.getConnection(Client.java:1557) at org.apache.hadoop.ipc.Client.call(Client.java:1480) at org.apache.hadoop.ipc.Client.call(Client.java:1441) at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:230) at com.sun.proxy.$Proxy16.getFileInfo(Unknown Source)
3.NameNode状态
![]()
4.查看数据是否put到HDFS

test.tar.gz数据文件已成功put到HDFS的/tmp目录,说明在put过程中Active状态的NameNode停止后,会自动将Standby状态的NameNode切换为Active状态,未造成HDFS任务终止。
5.Hive测试
1.使用hive命令登录,查看test_table建表语句
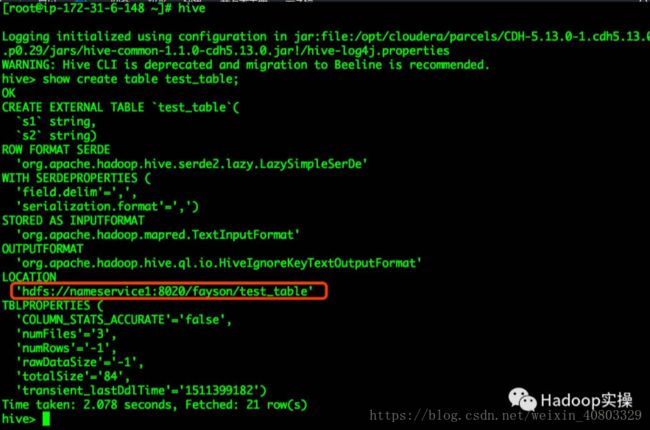
可以看到Hive表的LOCATION已经被修改为HDFS的NameService名称。
2.执行Select操作
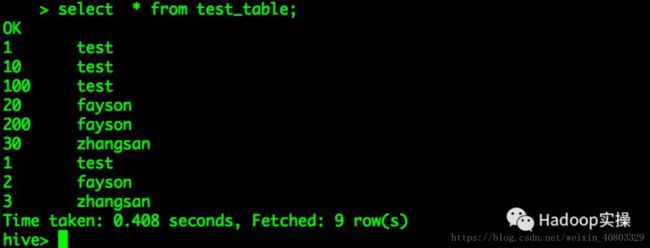
3.执行Count操作
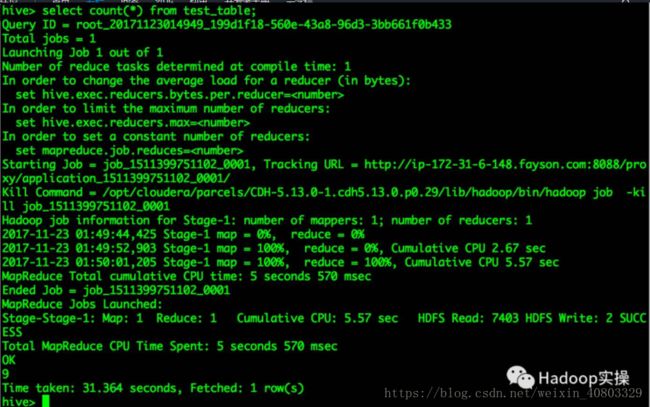
6.Impalac测试
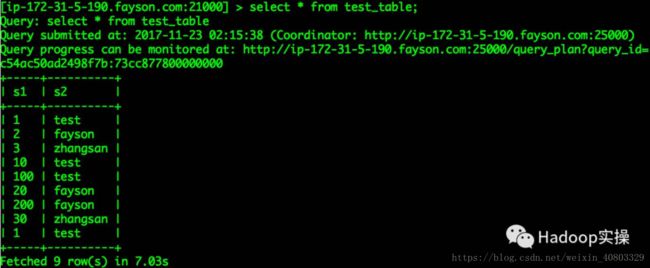
1.在mpala-shell命令行进行操作
[root@ip-172-31-5-190 ~]# impala-shell [ip-172-31-5-190.fayson.com:21000] > select * from test_table; ... +-----+----------+ | s1 | s2 | +-----+----------+ | 1 | test | | 2 | fayson | | 3 | zhangsan | | 10 | test | | 100 | test | | 20 | fayson | | 200 | fayson | | 30 | zhangsan | | 1 | test | +-----+----------+ Fetched 9 row(s) in 7.03s [ip-172-31-5-190.fayson.com:21000] > [ip-172-31-5-190.fayson.com:21000] > select count(*) from test_table; +----------+ | count(*) | +----------+ | 9 | +----------+ Fetched 1 row(s) in 0.16s [ip-172-31-5-190.fayson.com:21000] >
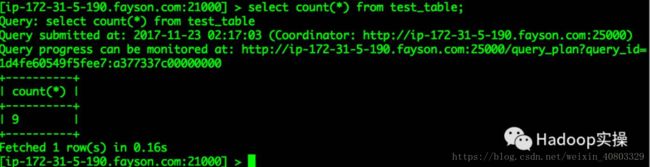
注意:如果在更新Hive Metastore NameNode时未重启Impala服务,则需要在命令行执行“invalidate metadata”
7.常见问题
1.查询Hive表报错“SemanticException Unable todetermine…”
hive> select * from test_table; FAILED: SemanticException Unable to determine if hdfs://ip-172-31-10-118.fayson.com:8020/fayson/test_table is encrypted: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.StandbyException): Operation category READ is not supported in state standby. Visit https://s.apache.org/sbnn-error at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:88) at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1835) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1505) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getServerDefaults(FSNamesystem.java:1847) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getServerDefaults(NameNodeRpcServer.java:582) at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.getServerDefaults(AuthorizationProviderProxyClientProtocol.java:100) at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getServerDefaults(ClientNamenodeProtocolServerSideTranslatorPB.java:394) at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2226) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2222) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2220) hive>
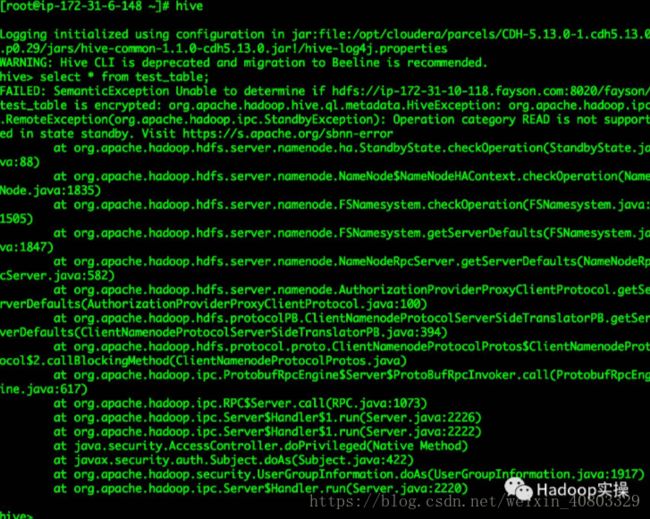
问题原因:查询报错由于HDFS启用HA,Hive表的LOCATION需要配置为NameServer的名称如hdfs://nameservice1/user/hive/warehouse/xxxx
查看建表语句,可以看到Hive的LOCATION地址使用的是未启用高可用时的HDFS地址。
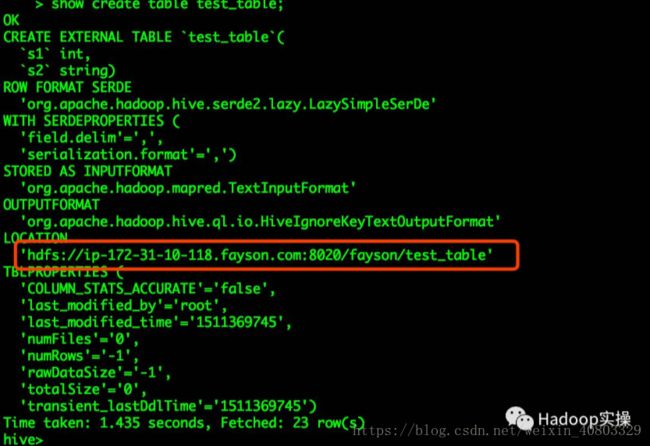
解决方法:参考更新Hive MetaStore NameNode章节
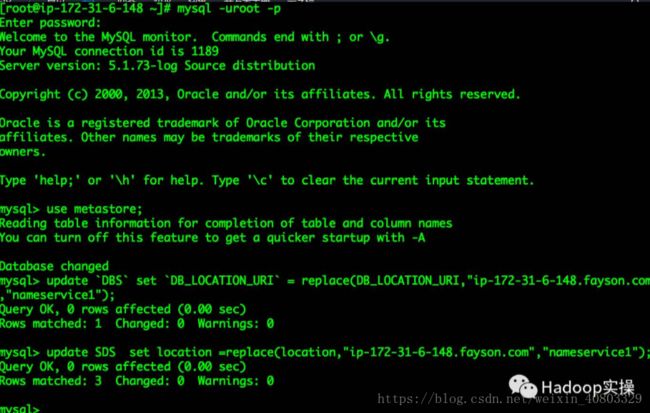
2.使用“更新Hive Metastore NameNode”功能,如果Hive表的LOCATION路径修改不成功,则可以通过直接修改hive的元数据库信息来完成。
[root@ip-172-31-6-148 ~]# mysql -uroot -p mysql> use metastore; mysql> update `DBS` set `DB_LOCATION_URI` = replace(DB_LOCATION_URI,"ip-172-31-6-148.fayson.com","nameservice1"); mysql> update SDS set location =replace(location,"ip-172-31-6-148.fayson.com","nameservice1");