mybatis面试题
Mybatis中的 ${} 和 #{}区别与用法
Mybatis 的Mapper.xml语句中parameterType向SQL语句传参有两种方式:#{}和${}
我们经常使用的是#{},一般解说是因为这种方式可以防止SQL注入,简单的说#{}这种方式SQL语句是经过预编译的,它是把#{}中间的参数转义成字符串,举个例子:
select * from student where student_name = #{name}
预编译后,会动态解析成一个参数标记符?:
select * from student where student_name = ?
而使用${}在动态解析时候,会传入参数字符串
select * from student where student_name = 'lyrics'
总结:#{} 这种取值是编译好SQL语句再取值
${} 这种是取值以后再去编译SQL语句
- #{}方式能够很大程度防止sql注入。
- $方式无法防止Sql注入。
- $方式一般用于传入数据库对象,例如传入表名.
- 一般能用#的就别用$.
当实体类中的属性名和表中的字段名不一样 ,怎么办 ?
32
33
34
35
上面的测试代码演示当实体类中的属性名和表中的字段名不一致时,使用MyBatis进行查询操作时无法查询出相应的结果的问题以及针对问题采用的两种办法:
解决办法一: 通过在查询的sql语句中定义字段名的别名,让字段名的别名和实体类的属性名一致,这样就可以表的字段名和实体类的属性名一一对应上了,这种方式是通过在sql语句中定义别名来解决字段名和属性名的映射关系的。
解决办法二: 通过
2、Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?
注:这道题是京东面试官面试我时问的。
答:还有很多其他的标签,
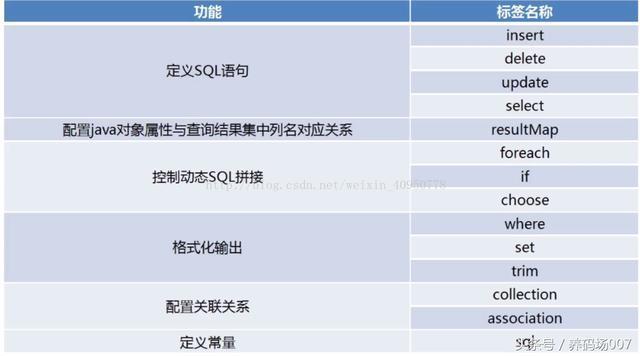
(1)resultMap 标签的使用
基本作用:建立SQL查询结果字段与实体属性的映射关系信息
查询的结果集转换为java对象,方便进一步操作
将结果集中的列与java对象中的属性对应起来并将值填充进去
3、 模糊查询like语句该怎么写?
第1种:在Java代码中添加sql通配符。
string wildcardname = “%smi%”;
list names = mapper.selectlike(wildcardname);
第2种:在sql语句中拼接通配符,会引起sql注入
string wildcardname = “smi”;
list names = mapper.selectlike(wildcardname);
4、通常一个Xml映射文件,都会写一个Dao接口与之对应,请问,这个Dao接口的工作原理是什么?Dao接口里的方法,参数不同时,方法能重载吗?
Dao接口,就是人们常说的Mapper接口,接口的全限名,就是映射文件中的namespace的值,接口的方法名,就是映射文件中MappedStatement的id值,接口方法内的参数,就是传递给sql的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到namespace为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在Mybatis中,每一个Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
6、Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
答:第一种是使用标签,逐一定义列名和对象属性名之间的映射关系。第二种是使用sql列的别名功能,将列别名书写为对象属性名,比如T_NAME AS NAME,对象属性名一般是name,小写,但是列名不区分大小写,Mybatis会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成T_NAME AS NaMe,Mybatis一样可以正常工作。
有了列名与属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
mybatis解决insert时候空值问题
mybatis在insert的时候,当对象里面有空值的时候,插入不成功,需要在SqlMapperConfig.xml中进行设置;
7、如何执行批量插入?
首先,创建一个简单的insert语句:
insert into names (name) values (#{value})
然后在java代码中像下面这样执行批处理插入:
list names = new arraylist();
names.add(“fred”);
names.add(“barney”);
names.add(“betty”);
names.add(“wilma”);
// 注意这里 executortype.batch
sqlsession sqlsession = sqlsessionfactory.opensession(executortype.batch);
try {
namemapper mapper = sqlsession.getmapper(namemapper.class);
for (string name : names) {
mapper.insertname(name);
}
sqlsession.commit();
} finally {
sqlsession.close();
} 8、如何获取自动生成的(主)键值?
insert into user (username,password,age) values (#{username},#{password},#{age})
SELECT LAST_INSERT_ID() AS id
insert into names (name) values (#{name})
name name = new name();
name.setname(“fred”);
int rows = mapper.insertname(name);
// 完成后,id已经被设置到对象中
system.out.println(“rows inserted = ” + rows);
system.out.println(“generated key value = ” + name.getid());9、在mapper中如何传递多个参数?
第一种方案
DAO层的函数方法
Public User selectUser(String name,String area);对应的Mapper.xml
其中,#{0}代表接收的是dao层中的第一个参数,#{1}代表dao层中第二参数,更多参数一致往后加即可。
第二种方案
此方法采用Map传多参数.
Dao层的函数方法
Public User selectUser(Map paramMap);对应的Mapper.xml
Service层调用
Private User xxxSelectUser(){
Map paramMap=new hashMap();
paramMap.put(“userName”,”对应具体的参数值”);
paramMap.put(“userArea”,”对应具体的参数值”);
User user=xxx. selectUser(paramMap);}个人认为此方法不够直观,见到接口方法不能直接的知道要传的参数是什么。
第三种方案
Dao层的函数方法
Public User selectUser(@param(“userName”)Stringname,@param(“userArea”)String area);对应的Mapper.xml
个人觉得这种方法比较好,能让开发者看到dao层方法就知道该传什么样的参数,比较直观,个人推荐用此种方案。
10、Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能。
Mybatis提供了9种动态sql标签:trim|where|set|foreach|if|choose|when|otherwise|bind。
其执行原理为,使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能。
11、Mybatis的Xml映射文件中,不同的Xml映射文件,id是否可以重复?
在mybatis中,映射文件中的namespace是用于绑定Dao接口的,即面向接口编程。
当你的namespace绑定接口后,你可以不用写接口实现类,mybatis会通过该绑定自动不同的Xml映射文件,如果配置了namespace,那么id可以重复;如果没有配置namespace,那么id不能重复;毕竟namespace不是必须的,只是最佳实践而已。
原因就是namespace+id是作为Map的key使用的,如果没有namespace,就剩下id,那么,id重复会导致数据互相覆盖。有了namespace,自然id就可以重复,namespace不同,namespace+id自然也就不同。
12、为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里?
Hibernate属于全自动ORM映射工具,使用Hibernate查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而Mybatis在查询关联对象或关联集合对象时,需要手动编写sql来完成,所以,称之为半自动ORM映射工具。
13、 一对一、一对多的关联查询 ?
说说不同点吧,resultType 和restltMap
restulyType:
1.对应的是java对象中的属性,大小写不敏感,
2.如果放的是java.lang.Map,key是查询语句的列名,value是查询的值,大小写敏感
3.resultMap:指的是定义好了的id的,是定义好的resyltType的引用
注意:用resultType的时候,要保证结果集的列名与java对象的属性相同,而resultMap则不用,而且resultMap可以用typeHander转换
4.type:java 对象对应的类,id:在本文件要唯一column :数据库的列名或别名,property:对应java对象的属性,jdbcType:java.sql.Types
查询语句中,resultMap属性指向上面那个属性的标签的id
parameterType:参数类型,只能传一个参数,如果有多个参数要封装,如封装成一个类,要写包名加类名,基本数据类型则可以省略
5.一对1、一对多时,若有表的字段相同必须写别名,不然查询结果无法正常映射,出现某属性为空或者返回的结果与想象中的不同,而这往往是没有报错的。
6.若有意外中的错误,反复检查以上几点,和认真核查自己的sql语句,mapper.xml文件是否配置正确。
4、Mybatis是如何进行分页的?分页插件的原理是什么?
注:我出的。
答:Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10
1.JDBC编程有哪些不足之处,MyBatis是如何解决这些问题的?
① 数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
解决:在SqlMapConfig.xml中配置数据链接池,使用连接池管理数据库链接。
② Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
③ 向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
解决: Mybatis自动将java对象映射至sql语句。
④ 对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
解决:Mybatis自动将sql执行结果映射至java对象。
2.MyBatis编程步骤是什么样的?
① 创建SqlSessionFactory
② 通过SqlSessionFactory创建SqlSession
③ 通过sqlsession执行数据库操作
④ 调用session.commit()提交事务
⑤ 调用session.close()关闭会话
3.MyBatis与Hibernate有哪些不同?
Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句,不过mybatis可以通过XML或注解方式灵活配置要运行的sql语句,并将java对象和sql语句映射生成最终执行的sql,最后将sql执行的结果再映射生成java对象。
Mybatis学习门槛低,简单易学,程序员直接编写原生态sql,可严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁,一但需求变化要求成果输出迅速。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件则需要自定义多套sql映射文件,工作量大。
Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件(例如需求固定的定制化软件)如果用hibernate开发可以节省很多代码,提高效率。但是Hibernate的缺点是学习门槛高,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡,以及怎样用好Hibernate需要具有很强的经验和能力才行。
总之,按照用户的需求在有限的资源环境下只要能做出维护性、扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。
4.使用MyBatis的mapper接口调用时有哪些要求?
① Mapper接口方法名和mapper.xml中定义的每个sql的id相同
② Mapper接口方法的输入参数类型和mapper.xml中定义的每个sql 的parameterType的类型相同
③ Mapper接口方法的输出参数类型和mapper.xml中定义的每个sql的resultType的类型相同
④ Mapper.xml文件中的namespace即是mapper接口的类路径。
5.SqlMapConfig.xml中配置有哪些内容?
SqlMapConfig.xml中配置的内容和顺序如下:
properties(属性)
settings(配置)
typeAliases(类型别名)
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境集合属性对象)
environment(环境子属性对象)
transactionManager(事务管理)
dataSource(数据源)
mappers(映射器)
6.简单的说一下MyBatis的一级缓存和二级缓存?
Mybatis首先去缓存中查询结果集,如果没有则查询数据库,如果有则从缓存取出返回结果集就不走数据库。Mybatis内部存储缓存使用一个HashMap,key为hashCode+sqlId+Sql语句。value为从查询出来映射生成的java对象
Mybatis的二级缓存即查询缓存,它的作用域是一个mapper的namespace,即在同一个namespace中查询sql可以从缓存中获取数据。二级缓存是可以跨SqlSession的。
7.Mapper编写有哪几种方式?
①接口实现类继承SqlSessionDaoSupport
使用此种方法需要编写mapper接口,mapper接口实现类、mapper.xml文件
1、在sqlMapConfig.xml中配置mapper.xml的位置
2、定义mapper接口
3、实现类集成SqlSessionDaoSupport
mapper方法中可以this.getSqlSession()进行数据增删改查。
4、spring 配置
②使用org.mybatis.spring.mapper.MapperFactoryBean
1、在sqlMapConfig.xml中配置mapper.xml的位置
如果mapper.xml和mappre接口的名称相同且在同一个目录,这里可以不用配置
2、定义mapper接口
注意
1、mapper.xml中的namespace为mapper接口的地址
2、mapper接口中的方法名和mapper.xml中的定义的statement的id保持一致
3、 Spring中定义
③使用mapper扫描器
1、mapper.xml文件编写,
注意:
mapper.xml中的namespace为mapper接口的地址
mapper接口中的方法名和mapper.xml中的定义的statement的id保持一致
如果将mapper.xml和mapper接口的名称保持一致则不用在sqlMapConfig.xml中进行配置
2、定义mapper接口
注意mapper.xml的文件名和mapper的接口名称保持一致,且放在同一个目录
3、配置mapper扫描器
4、使用扫描器后从spring容器中获取mapper的实现对象
扫描器将接口通过代理方法生成实现对象,要spring容器中自动注册,名称为mapper 接口的名称