Postgresql-xl 调研
Postgresql-xl 调研
来历
这个项目的背后是一家叫做stormDB的公司。整个代买基于postgres-xc。开源版本应该是stormdb的一个分支。
In 2010, NTT's Open Source Software Center approached EnterpriseDB to
build off of NTT OSSC's experience with a project called RitaDB and
EnterpriseDB's experience with a project called GridSQL, and the
result was a new project, Postgres-XC.In 2012, a company called StormDB was formed with some of the original
key Postgres-XC developers. StormDB added enhancements, including MPP
parallelism for performance and multi-tenant security.In 2013, TransLattice acquired StormDB, and in 2014, open sourced it
as Postgres-XL.
个人观感
纯个人理解,不代表是正确的,如果理解有偏差,抱歉
- 代码的整体质量不错,大部分的改动都有注释,注释可读性也很好,个别注释时效性有问题,但不影响理解代码。所有在pg代码中的改动都用idef做了有效隔离。理论上跟上PG的升级问题不大
- postgresql xc修改了一些postgresql的代码,postgresql xl又把他们改了过来,然后又加了好多代码。注意区分#idef和#ifndef
- Postgresql-xc的原则是能下推到dataNode的就下推到dataNode,实在推不下去的就把所有的数据集中在在聚集节点做。而xl做了MPP。
分布式架构
Postgresql-xl的官方主页在。注意这个网站引用的googleapi的某些资源,所以有时候比较慢。注意OLAP是排在OLTP的前面。
Features
Fully ACID
Open Source
Cluster-wide Consistency
Multi-tenant Security
PostgreSQL-based
Workloads:
OLAP with MPP Parallelism
Online Transaction Processing
Mixed
Operational Data Store
Key-value including JSON
首先请仔细读官方overview,这篇review中概要地描述了整个系统的大概的状况。注意这个架构中dataNode和coordinators都可以部署多个,GTM(global Transcation Manager)只有一个,图中画了两个的原因是有一个是standby。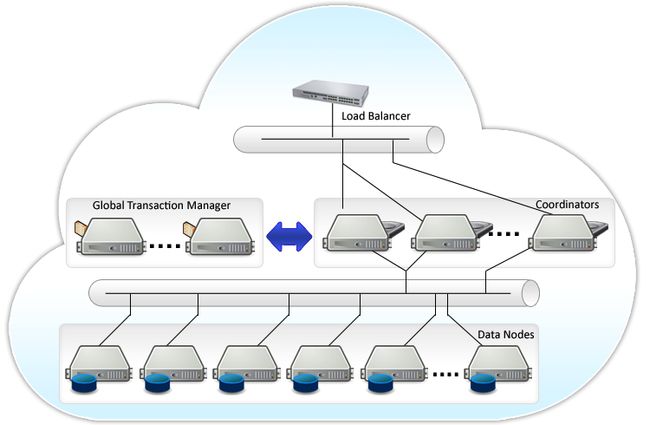
和Postgresql-xc的关系
这个问题官方的答案是
Q. How does Postgres-XL relate to Postgres-XC and Stado?
The project includes architects and developers who previously worked
on both Postgres-XC and Stado, and Postgres-XL contains code from
Postgres-XC. The Postgres-XL project has its own philosophy and
approach. Postgres-XL values stability, correctness and performance
over new functionality. The Postgres-XL project ultimately strives to
track and merge in code from PostgreSQL. Postgres-XL adds some
significant performance improvements like MPP parallelism and replan
avoidance on the data nodes that are not part of Postgres-XC.
Postgres-XC currently focuses on OLTP workloads. Postgres-XL is more
flexible in terms of the types of workloads it can handle including
Big Data processing thanks to its parallelism. Additionally,
Postgres-XL is more secure for multi-tenant environments. The
Postgres-XL community is also very open and welcoming to those who
wish to become more involved and contribute, whether on the mailing
lists, participating in developer meetings, or meeting in person.
Users will help drive development priorities and the project roadmap.
实际上在Postgresql-xl的src中包含的一个文件夹就叫pgxc。由于代码是基于pgxc的,所以大量的注释和代码都是pgxc的。
xl和xc最大的不同在于:xc的逻辑是如果SQL可以下推到datanode上做,那么就下推,否则把所有数据读到coordinator上面统一做。而xl则是真正意义上MPP。
代码改动方法和实现
相对于postgresql来说,在pgxl的基本逻辑是尽量少的修改代码,某些核心组件必须要做出调整,但是大部分保持一致,新增的文件都放在新的位置。
他们做的比较好的一点是,所有的改动地方都用ifdef处理过了。
#ifdef PGXC (PG-xc的改动)
#ifndef XCP(PG-xl基于xc的改动)
....
#endif
#endifGTM
GTM stands for Global Transaction Manager. It provides global
transaction ID and snapshot to each transaction in Postgres-XL
database cluster. It also provide several global value such as
sequence and global timestamp.GTM itself can be configured as a backup of other GTM as GTM-Standby
so that GTM can continue to run even if main GTM fails. You may want
to install GTM-Standby to separate server.
从代码(src/gtm)上看,这部分主要功能就是提供global的事务管理,给出global_txn_id和timestamp等等,考虑到这是一个单点,standby的相关代码也在这一部分。
snapshot
/*
* Get snapshot for the given transactions. If this is the first call in the
* transaction, a fresh snapshot is taken and returned back. For a serializable
* transaction, repeated calls to the function will return the same snapshot.
* For a read-committed transaction, fresh snapshot is taken every time and
* returned to the caller.
*
* The returned snapshot includes xmin (lowest still-running xact ID),
* xmax (highest completed xact ID + 1), and a list of running xact IDs
* in the range xmin <= xid < xmax. It is used as follows:
* All xact IDs < xmin are considered finished.
* All xact IDs >= xmax are considered still running.
* For an xact ID xmin <= xid < xmax, consult list to see whether
* it is considered running or not.
* This ensures that the set of transactions seen as "running" by the
* current xact will not change after it takes the snapshot.
*
* All running top-level XIDs are included in the snapshot.
*
* We also update the following global variables:
* RecentGlobalXmin: the global xmin (oldest TransactionXmin across all
* running transactions
*
* Note: this function should probably not be called with an argument that's
* not statically allocated (see xip allocation below).
*/
GTM_Snapshot
GTM_GetTransactionSnapshot(GTM_TransactionHandle handle[], int txn_count, int *status)snapshot的重要功能就是,在各个节点之间同步事务的提交状态。
GTM-Proxy
Because GTM has to take care of each transaction, it has to read and write enormous amount of messages which may restrict Postgres-XL scalability. GTM-Proxy is a proxy of GTM feature which groups requests and response to reduce network read/write by GTM. Distributing one snapshot to multiple transactions also contributes to reduce GTM network workload.
Coordinator
The Coordinator is an entry point to Postgres-XL from applications.
You can run more than one Coordinator simultaneously in the cluster.
Each Coordinator behaves just as a PostgreSQL database server, while
all the Coordinators handles transactions in harmonized way so that
any transaction coming into one Coordinator is protected against any
other transactions coming into others. Updates by a transaction is
visible immediately to others running in other Coordinators. To
simplify the load balance of Coordinators and Datanodes, as mentioned
below, it is highly advised to install same number of Coordinator and
Datanode in a server.
代码基本在 src/backend/pgxc。
Datanode
The Datanode is very close to PostgreSQL itself because it just handles incoming statements locally.
The Coordinator and Datanode shares the same binary but their behavior is a little different. The Coordinator decomposes incoming statements into those handled by Datanodes. If necessary, the Coordinator materializes response from Datanodes to calculate final response to applications.
实现查询优化的方法
DDL的处理
增加了一个叫做STORM_CATALOG_NAMESPACE的namespace,新增的系统表什么的都在这个namespace里。对于DDL语句来说,基本上就是发命令转发到所有的DataNode和Coodinator上面去,具体的代码,具体逻辑参见函数
/*
* Execute utility statement on multiple Datanodes
* It does approximately the same as
*
* RemoteQueryState *state = ExecInitRemoteQuery(plan, estate, flags);
* Assert(TupIsNull(ExecRemoteQuery(state));
* ExecEndRemoteQuery(state)
*
* But does not need an Estate instance and does not do some unnecessary work,
* like allocating tuple slots.
*/
void
ExecRemoteUtility(RemoteQuery *node)directStmt
所谓directStmt是这样的stmt:
Synopsis
EXECUTE DIRECT ON ( nodename [, ... ] )
query
Examples
Select some data in a given table tenk1 on remote Datanode named dn1:
EXECUTE DIRECT ON NODE dn1 'SELECT * FROM tenk1 WHERE col_char = ''foo''';
Select local timestamp of a remote node named coord2:
EXECUTE DIRECT ON coord2 'select clock_timestamp()';
Select list of tables of a remote node named dn50:
EXECUTE DIRECT ON dn50 'select tablename from pg_tables'; 详细说明见:http://files.postgres-xl.org/documentation/sql-executedirect.html
实际上在standard_planner(Query *parse, int cursorOptions, ParamListInfo boundParams)中对directStmt是这么判断的:
/*
* pgxc_direct_planner
* The routine tries to see if the statement can be completely evaluated on the
* datanodes. In such cases coordinator is not needed to evaluate the statement,
* and just acts as a proxy. A statement can be completely shipped to the remote
* node if every row of the result can be evaluated on a single datanode.
* For example:
*
* Only EXECUTE DIRECT statements are sent directly as of now
*/
#ifdef XCP
if (IS_PGXC_COORDINATOR && !IsConnFromCoord() && parse->utilityStmt &&
IsA(parse->utilityStmt, RemoteQuery))
return pgxc_direct_planner(parse, cursorOptions, boundParams);
#endif简单说就是直接发SQL发到指定的节点。
非directStmt
对于不是directStmt的查询来说,情况会变得比较复杂,可能每个节点只完成一部分的运算,而这次预算的结果又是另外一个或多个节点运算的输入。
- 有效的划分子查询。主要是生产plan时的工作。
- 下发子查询,子查询完成后把结果分发给需要的节点。主要是执行阶段的工作。
Parse/resolve
在这个阶段,最重要的事情发生在preprocess_targetlist(PlannerInfo *root, List *tlist)当中,中间用#ifdef XCP包围的代码就是表示xl需要data node分布的代码,这里面会写两个关键的变量distribution->nodes(这个表涉及到的节点)和distribution->restrictNodes(在insert和update中可以根据主键过滤掉部分节点)
生成plan
下面的函数会生成一个RemoteSubPlan,它和PG原有的plan是一样的,只不过它在执行的时候是读取从网络(而不是内存或磁盘)得到的中间结果。在makeplan的时候,需要计算源分布,结果分布和排序。
对于不同的操作join,scan,group by都有着不同的分布方式。不过得到的plan是一致的。
/*
* make_remotesubplan
* Create a RemoteSubplan node to execute subplan on remote nodes.
* leftree - the subplan which we want to push down to remote node.
* resultDistribution - the distribution of the remote result. May be NULL -
* results are coming to the invoking node
* execDistribution - determines how source data of the subplan are
* distributed, where we should send the subplan and how combine results.
* pathkeys - the remote subplan is sorted according to these keys, executor
* should perform merge sort of incoming tuples
*/
RemoteSubplan *
make_remotesubplan(PlannerInfo *root,
Plan *lefttree,
Distribution *resultDistribution,
Distribution *execDistribution,
List *pathkeys)重分布数据
/*
* Set a RemoteSubPath on top of the specified node and set specified
* distribution to it
*/
static Path *
redistribute_path(Path *subpath, char distributionType,
Bitmapset *nodes, Bitmapset *restrictNodes,
Node* distributionExpr)SCAN
/*
* set_scanpath_distribution
* Assign distribution to the path which is a base relation scan.
*/
static void
set_scanpath_distribution(PlannerInfo *root, RelOptInfo *rel, Path *pathnode)JOIN
在create_xxxjoin_path中都会调用set_joinpath_distribution来生成join的分布方式。
/*
* Analyze join parameters and set distribution of the join node.
* If there are possible alternate distributions the respective pathes are
* returned as a list so caller can cost all of them and choose cheapest to
* continue.
*/
static List *
set_joinpath_distribution(PlannerInfo *root, JoinPath *pathnode)
下面这些情况是可以不重分布数据搞定的:
/*
* If both subpaths are distributed by replication, the resulting
* distribution will be replicated on smallest common set of nodes.
* Catalog tables are the same on all nodes, so treat them as replicated
* on all nodes.
*/
/*
* Check if we have inner replicated
* The "both replicated" case is already checked, so if innerd
* is replicated, then outerd is not replicated and it is not NULL.
* This case is not acceptable for some join types. If outer relation is
* nullable data nodes will produce joined rows with NULLs for cases when
* matching row exists, but on other data node.
*/
/*
* Check if we have outer replicated
* The "both replicated" case is already checked, so if outerd
* is replicated, then innerd is not replicated and it is not NULL.
* This case is not acceptable for some join types. If inner relation is
* nullable data nodes will produce joined rows with NULLs for cases when
* matching row exists, but on other data node.
*/
/*
* This join is still allowed if inner and outer paths have
* equivalent distribution and joined along the distribution keys.
*/
/*
* Build cartesian product, if no hasheable restrictions is found.
* Perform coordinator join in such cases. If this join would be a part of
* larger join, it will be handled as replicated.
* To do that leave join distribution NULL and place a RemoteSubPath node on
* top of each subpath to provide access to joined result sets.
* Do not redistribute pathes that already have NULL distribution, this is
* possible if performing outer join on a coordinator and a datanode
* relations.
*/GROUP BY
和join,group by的做法类似
/*
* Grouping preserves distribution if distribution key is the
* first grouping key or if distribution is replicated.
* In these cases aggregation is fully pushed down to nodes.
* Otherwise we need 2-phase aggregation so put remote subplan
* on top of the result_plan. When adding result agg on top of
* RemoteSubplan first aggregation phase will be pushed down
* automatically.
*/
static Plan *
grouping_distribution(PlannerInfo *root, Plan *plan,
int numGroupCols, AttrNumber *groupColIdx,
List *current_pathkeys, Distribution **distribution)实现查询执行的方法
ExecutorStart
#ifdef PGXC
case T_RemoteQuery:
result = (PlanState *) ExecInitRemoteQuery((RemoteQuery *) node,
estate, eflags);
break;
#endif#ifdef XCP
case T_RemoteSubplan:
result = (PlanState *) ExecInitRemoteSubplan((RemoteSubplan *) node,
estate, eflags);
break;
#endif /* XCP */ExecutorRun
主要是通过,下面两个函数来完成的,分别处理query和subplan。
#ifdef PGXC
case T_RemoteQueryState:
result = ExecRemoteQuery((RemoteQueryState *) node);
break;
#endif
#ifdef XCP
case T_RemoteSubplanState:
result = ExecRemoteSubplan((RemoteSubplanState *) node);
break;
#endif /* XCP */数据交换
pgxl的数据交换方式是通过这样的方式完成:
- 节点完成局部结果之后,把结果持续不断的写入叫做的ShareQueue结果,这是一个生产者(局部计算得到的结果)消费者(目标的节点,也就是需要distribute的结果)模型。
- 一个节点的输入可能来自多个节点的,循环读取结果即可。
- 如果需要的话,用Combiner完成排序。
上述ShareQueue每个dataNode上各有一个。
数据分布方式
/*----------
* DistributionType - how to distribute the data
*
*----------
*/
typedef enum DistributionType
{
DISTTYPE_REPLICATION, /* Replicated */
DISTTYPE_HASH, /* Hash partitioned */
DISTTYPE_ROUNDROBIN, /* Round Robin */
DISTTYPE_MODULO /* Modulo partitioned */
} DistributionType;DISTRIBUTE BY Note: The following description applies only to
Postgres-XLThis clause specifies how the table is distributed or replicated among
Datanodes.REPLICATION Each row of the table will be replicated to all the
Datanode of the Postgres-XL database cluster.ROUNDROBIN Each row of the table will be placed in one of the
Datanodes in a round-robin manner. The value of the row will not be
needed to determine what Datanode to go.HASH ( column_name ) Each row of the table will be placed based on the
hash value of the specified column. Following type is allowed as
distribution column: INT8, INT2, OID, INT4, BOOL, INT2VECTOR,
OIDVECTOR, CHAR, NAME, TEXT, BPCHAR, BYTEA, VARCHAR, FLOAT4, FLOAT8,
NUMERIC, CASH, ABSTIME, RELTIME, DATE, TIME, TIMESTAMP, TIMESTAMPTZ,
INTERVAL, and TIMETZ.Please note that floating point is not allowed as a basis of the
distribution column.MODULO ( column_name ) Each row of the table will be placed based on
the modulo of the specified column. Following type is allowed as
distribution column: INT8, INT2, OID, INT4, BOOL, INT2VECTOR,
OIDVECTOR, CHAR, NAME, TEXT, BPCHAR, BYTEA, VARCHAR, FLOAT4, FLOAT8,
NUMERIC, CASH, ABSTIME, RELTIME, DATE, TIME, TIMESTAMP, TIMESTAMPTZ,
INTERVAL, and TIMETZ.Please note that floating point is not allowed as a basis of the
distribution column.If DISTRIBUTE BY is not specified, columns with UNIQUE constraint will
be chosen as the distribution key. If no such column is specified,
distribution column is the first eligible column in the definition. If
no such column is found, then the table will be distributed by
ROUNDROBIN.
事务处理
算法就是两阶段提交,显然并不是所有的操作都需要两阶段提交的。触发两阶段提交的条件
/*
* Returns true if 2PC is required for consistent commit: if there was write
* activity on two or more nodes within current transaction.
*/
bool
IsTwoPhaseCommitRequired(bool localWrite)关于两阶段提交,这里不赘述,下面这段注释来自postgresql-xc。不过xl应该也是类似的逻辑,相关的代码,一方面在backend/pgxc/pool里,另一方面在PG正常的事务处理中。
/*
* Do pre-commit processing for remote nodes which includes Datanodes and
* Coordinators. If more than one nodes are involved in the transaction write
* activity, then we must run 2PC. For 2PC, we do the following steps:
*
* 1. PREPARE the transaction locally if the local node is involved in the
* transaction. If local node is not involved, skip this step and go to the
* next step
* 2. PREPARE the transaction on all the remote nodes. If any node fails to
* PREPARE, directly go to step 6
* 3. Now that all the involved nodes are PREPAREd, we can commit the
* transaction. We first inform the GTM that the transaction is fully
* PREPARED and also supply the list of the nodes involved in the
* transaction
* 4. COMMIT PREPARED the transaction on all the remotes nodes and then
* finally COMMIT PREPARED on the local node if its involved in the
* transaction and start a new transaction so that normal commit processing
* works unchanged. Go to step 5.
* 5. Return and let the normal commit processing resume
* 6. Abort by ereporting the error and let normal abort-processing take
* charge.
*/杂项
barrier
barrier
CREATE BARRIER
Name
CREATE BARRIER -- create a new barrier
Synopsis
CREATE BARRIER barrier_name
Description
Note: The following description applies only to Postgres-XL
CREATE BARRIER is new SQL command specific to Postgres-XL that creates a new XLOG record on each node of the cluster consistently. Essentially a barrier is a consistent point in the cluster that you can recover to. Note that these are currently created manually, not autoatically. Without barriers, if you recover an individual component, it may be possible that it is not consistent with the other nodes depending on when it was committed.
A barrier is created via a 2PC-like mechanism from a remote Coordinator in 3 phases with a prepare, execute and ending phases. A new recovery parameter called recovery_target_barrier has been added in recovery.conf. In order to perform a complete PITR recovery, it is necessary to set recovery_target_barrier to the value of a barrier already created. Then distribute recovery.conf to each data folder of each node, and then to restart the nodes one by one.
The default barrier name is dummy_barrier_id. It is used when no barrier name is specified when using CREATE BARRIER.pause\unpause
pause
PAUSE CLUSTER Name
PAUSE CLUSTER -- pause the Postgres-XL cluster Synopsis
PAUSE CLUSTER Description
Note: The following description applies only to Postgres-XL
PAUSE CLUSTER is a SQL command specific to Postgres-XL that pauses
cluster operation.Pause blocks any new transactions from starting and waits until
existing transactions complete, then returns. Existing sessions are
still connected to Coordinators, it is just that any new statements
will be held up and not be executed.The session that paused the cluster can perform tasks exclusively on
the cluster. This is useful for maintenance tasks to resolve a
problem, restart a Datanode, manually failover a Datanode, etc.
Applications will not receive error messages unless they themselves
timeout, statement execution will just be briefly suspended.Once the DBA has completed whatever tasks were needed, the command
UNPAUSE CLUSTER can be used.Compatibility
PAUSE CLUSTER does not conform to the SQL standards, it is a
Postgres-XL specific command.
unpause
UNPAUSE CLUSTER Name
UNPAUSE CLUSTER -- unpause the Postgres-XL cluster Synopsis
UNPAUSE CLUSTER Description
Note: The following description applies only to Postgres-XL
UNPAUSE CLUSTER is a SQL command specific to Postgres-XL that unpauses
cluster operation.If the DBA previously paused the cluster via the command PAUSE
CLUSTER, the DBA can resume operation vi UNPAUSE CLUSTER.Compatibility
UNPAUSE CLUSTER does not conform to the SQL standards, it is a
Postgres-XL specific command.