TorchText 详解
TorchText 流程
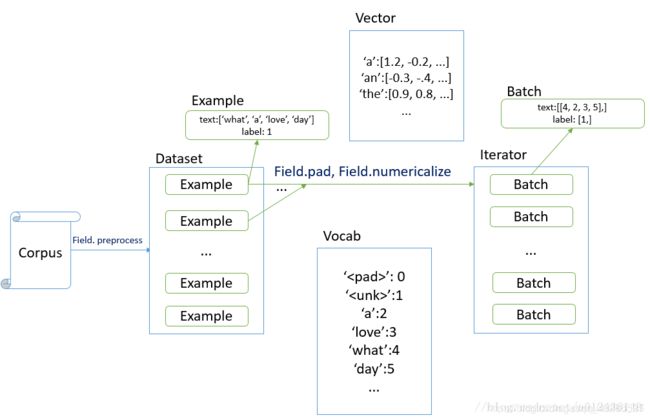
TorchText 对数据的处理可以概括为:
Filed、Dataset以及迭代器
1.torchtext.data.Field : 用来定义字段的处理方法(文本字段,标签字段)
创建 Example时的预处理
from torchtext.data import Field
tokenize = lambda x: x.split()
TEXT = Field(sequential=True, tokenize=tokenize, lower=True)
LABEL = Field(sequential=False, use_vocab=False)
tokenize 传入一个函数,表示如何将文本str变成token,同时可以对分词去除常用词
sequential表示是否切分数据,如果数据已经是序列化的了而且是数字类型的,则应该传递参数use_vocab = False和sequential = False
2.构建Dataset
Fields知道怎么处理原始数据,现在我们需要告诉Fields去处理哪些数据。这就是我们需要用到Dataset的地方。Torchtext中有各种内置Dataset,用于处理常见的数据格式。 对于csv/tsv文件,TabularDataset类很方便。
train, test = data.TabularDataset.splits(
path=path, format='tsv', skip_header=True,
train='train.tsv', validation='test.tsv',
fields=[
#(None, None), # 根据原文格式选择field
('label', label_field),
('text_a', text_field)
]
)
from torchtext.data import TabularDataset
tv_datafields = [("id", None), # 我们不会需要id,所以我们传入的filed是None
("comment_text", TEXT), ("toxic", LABEL),
("severe_toxic", LABEL), ("threat", LABEL),
("obscene", LABEL), ("insult", LABEL),
("identity_hate", LABEL)]
trn, vld = TabularDataset.splits(
path="data", # 数据存放的根目录
train='train.csv', validation="valid.csv",
format='csv',
skip_header=True, # 如果你的csv有表头, 确保这个表头不会作为数据处理
fields=tv_datafields)
tst_datafields = [("id", None), # 我们不会需要id,所以我们传入的filed是None
("comment_text", TEXT)]
tst = TabularDataset(
path="data/test.csv", # 文件路径
format='csv',
skip_header=True, # 如果你的csv有表头, 确保这个表头不会作为数据处理
fields=tst_datafields)
fields必须与列的顺序相同。对于我们不使用的列,我们在fields的位置传入一个None。
3.生成词表
Torchtext将单词映射为整数,但必须告诉它应该处理的全部单词。 在我们的例子中,我们可能只想在训练集上建立词汇表,所以我们运行代码:TEXT.build_vocab(trn)。这使得torchtext遍历训练集中的所有元素,检查TEXT字段的内容,并将其添加到其词汇表中。Torchtext有自己的Vocab类来处理词汇。Vocab类在stoi属性中包含从word到id的映射,并在其itos属性中包含反向映射。 除此之外,它可以为word2vec等预训练的embedding自动构建embedding矩阵。Vocab类还可以使用像max_size和min_freq这样的选项来表示词汇表中有多少单词或单词出现的次数。未包含在词汇表中的单词将被转换成。
text_field.build_vocab(train, test) #构建词表
label_field.build_vocab(train, test) #构建标签表
4.构造迭代器
对于验证集和训练集合使用BucketIterator.splits(),目的是自动进行shuffle和padding,并且为了训练效率期间,尽量把句子长度相似的shuffle在一起。
对于测试集用Iterator,因为不用sort。
sort 是对全体数据按照升序顺序进行排序,而sort_within_batch仅仅对一个batch内部的数据进行排序。
sort_within_batch参数设置为True时,按照sort_key按降序对每个小批次内的数据进行降序排序。当你想对padded序列使用pack_padded_sequence转换为PackedSequence对象时,这是必需的。
注意sort和shuffle默认只是对train=True字段进行的,但是train字段默认是True。所以测试集合可以这么写testIter = Iterator(tst, batch_size = 64, device =-1, train=False)写法等价于下面的一长串写法。
repeat 是否连续的训练无数个batch ,默认是False
device 可以是torch.device
from torchtext.data import Iterator, BucketIterator
train_iter, val_iter = BucketIterator.splits((trn, vld),
# 我们把Iterator希望抽取的Dataset传递进去
batch_sizes=(25, 25),
device=-1,
# 如果要用GPU,这里指定GPU的编号
sort_key=lambda x: len(x.comment_text),
# BucketIterator 依据什么对数据分组
sort_within_batch=False,
repeat=False)
# repeat设置为False,因为我们想要包装这个迭代器层。
test_iter = Iterator(tst, batch_size=64,
device=-1,
sort=False,
sort_within_batch=False,
repeat=False)
填充量由batch中最长的序列决定。因此,当序列长度相似时,填充效率最高。BucketIterator会在在后台执行这些操作。需要注意的是,你需要告诉BucketIterator你想在哪个数据属性上做bucket。在我们的例子中,我们希望根据comment_text字段的长度进行bucket处理,因此我们将其作为关键字参数传入sort_key = lambda x: len(x.comment_text)
BucketIterator和Iterator的区别是,BucketIterator尽可能的把长度相似的句子放在一个batch里面。
训练模型
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
class SimpleLSTMBaseline(nn.Module):
def __init__(self, hidden_dim, emb_dim=300, num_linear=1):
super().__init__()
# 词汇量是 len(TEXT.vocab)
self.embedding = nn.Embedding(len(TEXT.vocab), emb_dim)
self.encoder = nn.LSTM(emb_dim, hidden_dim, num_layers=1)
self.linear_layers = []
# 中间fc层
for _ in range(num_linear - 1):
self.linear_layers.append(nn.Linear(hidden_dim, hidden_dim))
self.linear_layers = nn.ModuleList(self.linear_layers)
# 输出层
self.predictor = nn.Linear(hidden_dim, 6)
def forward(self, seq):
hdn, _ = self.encoder(self.embedding(seq))
feature = hdn[-1, :, :] # 选择最后一个output
for layer in self.linear_layers:
feature = layer(feature)
preds = self.predictor(feature)
return preds
em_sz = 100
nh = 500
model = SimpleBiLSTMBaseline(nh, emb_dim=em_sz)
编写训练循环
import tqdm
opt = optim.Adam(model.parameters(), lr=1e-2)
loss_func = nn.BCEWithLogitsLoss()
epochs = 2
for epoch in range(1, epochs + 1):
running_loss = 0.0
running_corrects = 0
model.train() # 训练模式
for x, y in tqdm.tqdm(train_dl): # 由于我们的封装,我们可以直接对数据进行迭代
opt.zero_grad()
preds = model(x)
loss = loss_func(y, preds)
loss.backward()
opt.step()
running_loss += loss.data[0] * x.size(0)
epoch_loss = running_loss / len(trn)
# 计算验证数据的误差
val_loss = 0.0
model.eval() # 评估模式
for x, y in valid_dl:
preds = model(x)
loss = loss_func(y, preds)
val_loss += loss.data[0] * x.size(0)
val_loss /= len(vld)
print('Epoch: {}, Training Loss: {:.4f}, Validation Loss: {:.4f}'.format(epoch, epoch_loss, val_loss))
现在来产生我们的预测
test_preds = []
for x, y in tqdm.tqdm(test_dl):
preds = model(x)
preds = preds.data.numpy()
# 模型的实际输出是logit,所以再经过一个sigmoid函数
preds = 1 / (1 + np.exp(-preds))
test_preds.append(preds)
test_preds = np.hstack(test_preds)
我们可以将我们的预测写入一个csv文件。
import pandas as pd
df = pd.read_csv("data/test.csv")
for i, col in enumerate(["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]):
df[col] = test_preds[:, i]
df.drop("comment_text", axis=1).to_csv("submission.csv", index=False)
https://zhuanlan.zhihu.com/p/31139113
https://www.jianshu.com/p/e5adb235399e
https://blog.csdn.net/u012436149/article/details/79310176
https://www.jianshu.com/p/71176275fdc5
https://state-of-art.top/2018/11/28/torchtext%E8%AF%BB%E5%8F%96%E6%96%87%E6%9C%AC%E6%95%B0%E6%8D%AE%E9%9B%86/
https://state-of-art.top/2018/11/28/%E6%96%87%E6%9C%AC%E9%A2%84%E5%A4%84%E7%90%86/
https://github.com/bigboNed3/chinese_text_cnn
https://github.com/649453932/Chinese-Text-Classification-Pytorch