MySQL学习---->第二练:语句初步(SQL概述、数据定义、查询)
一、SQL概述
1.SQL语言主要分为三类:
数据定义(DDL):create,drop,alter数据操纵(DML):insert,update,delete,select
数据控制(DCL):grant,revoke
2.SQL对数据库三级模式结构的支持:

·视图(view):对应于外模式。
是从基本表或其他视图中导出的虚表,不存储。
·基本表:对应于模式。
特点:
一个基本关系 <---> 一个基本表;
多个基本表 ---> 一个存储文件;
一个基本表可带多个索引,放在存储文件中。
·存储文件:逻辑结构 <---> 内模式,物理结构任意。
基本表和视图都是关系,都用SQL语言进行操作。
二、数据定义
1、定义概述
|
表
|
视图
|
索引
|
|
| 创建 | CREATE TABLE | CREATE VIEW | CREATE INDEX |
| 删除 | DROP TABLE | DROP VIEW | DROP INDEX |
| 修改 | ALTER TABLE |
#没有修改索引、视图的操作,只能删除重建。
2.定义、删除与修改基本表
2.1 定义基本表
一般格式:
CREATE TABLE <表名> (
<列名> <数据类型> [列级完整性约束],
<列名> <数据类型> [列级完整性约束],
...
<表级完整性约束条件>
) ;
<表名>:基本表的名字,
<列名>:基本表所含的属性(列)的名字,一个或多个。
<列级完整性约束>:规定列要满足的一些约束条件(仅涉及一个属性,如:NOT NULL、UNIQUE、单属性主码、外码等)
<表级完整性约束条件>:规定表要满足的一些约束条件(涉及一个或多个属性,如:单属性或组合的主码、外码等)
<数据类型> :指明属性的数据类型及长度。
;为语句结束标志。
例1:创建基本表
Student(Sid,Sname,Ssex,Sage)
Course(Cid,Cname,Cteacher)
SC(Sid,Cid,Grade)
Sid,Cid分别为Student,Course的外键。
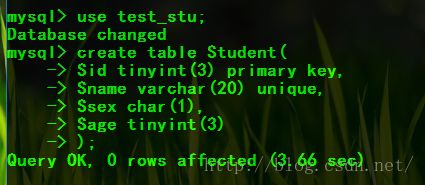
修改Sid为unsigned tinyint型
建表结果:
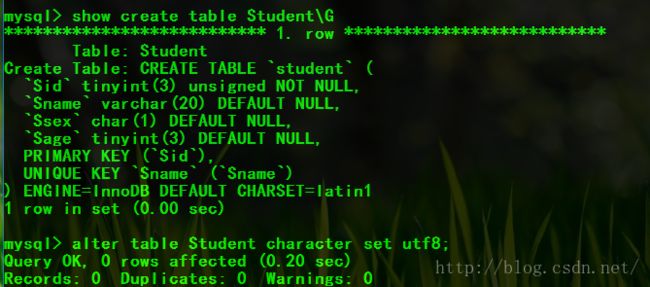
大意忘记更改字符集:
alter table Student character set utf8;
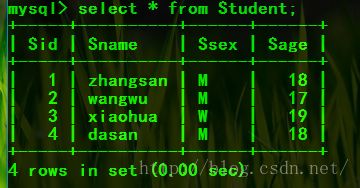
插入一些数据:
insert into Student
(Sid,Sname,Ssex,Sage)
values
(1,'zhangsan','M',18),
(2,'wangwu','M',17),
(3,'xiaohua','W',19),
(4,'dasan','M',18);
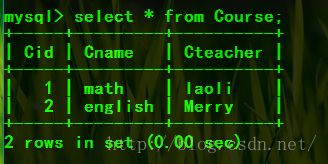
CREATE TABLE Course (
Cid TINYINT(4) UNSIGNED PRIMARY KEY,
Cname VARCHAR(20),
Cteacher VARCHAR(20)
)charset=utf8;
insert into Course
(Cid,Cname,Cteacher)
values
(001,'math','laoli'),
(002,'english','Merry');
2.2 修改基本表
一般格式:
ALTER TABLE <表名>
[ ADD <新列名> <数据类型> [完整性约束] ]
[ DROP <COLUMN列名> ]
[ MODIFY <COLUMN列名> <数据类型> [ [NOT] NULL] ]
[ DROP [CONSTRAINT] <完整性约束名> ]
<表名>: 指定要修改的基本表;
ADD子句: 用于增加新列和新的完整性约束;
DROP COLUMN子句: 用于删除指定列 ;
MODIFY COLUMN 子句:用于修改原有的列定义 ;
DROP [CONSTRAINT] 子句:用于删除完整性约束;
例2.1:向Student表增加Scity。
alter table Student add Scity varchar(20);
向Scity中插入数据:
update Student set Scity='武汉' where Sid=1;
例2.2:将年龄数据类型改为smallint,并默认为0。
alter table Student modify Sage smallint not null default '0';
insert into Student (Sid,Sname,Ssex,Scity) values (5,'sansan','W','西安');
删除基本表:
DROP TABLE <表名>,...
#字段改名
#alter table Student change Sage Sage1 int(4);
#modify和change都可以修改列的定义,不同的是change 后面要写两次列名,不方便但是可惜修改列名。
2.3 建立与删除索引
索引是加快查询速度的有效手段。
一般格式:
CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名> (<列名>[<次序>] ,<列名>[<次序>] ... )
<表名>:指定要建索引的基本表。
<列名>:指定要建索引的列名。索引可以建在一列或多列上,各列名之间用逗号分隔。
<次序>:每个<列名>后可指定索引值的排列次序,包括ASC(升序)和DESC(降序)两种,缺省值为ASC。
UNIQUE:表明每一个索引值只对应唯一的数据记录。
CLUSTER:建立聚簇索引:表中的记录按索引项的顺序存放。一个基本表最多只能建立一个聚簇索引。
聚簇索引列数据的更新会导致表中记录的物理移动,代价较大,因此经常更新的列不宜建聚簇索引。
例3:为Student建立索引。
create index S_NO on Student(Sid desc);
删除索引:
DROP INDEX <索引名> ON <表名>
查看索引:
SHOW INDEX FROM <表名>
1)索引一经建立,就由DBMS使用和维护它,不需用户干预;
2)如果数据增删改频繁,系统会花费许多时间来维护索引, 这时,可以删除一些不必要的索引。
三、查询
1 查询概述
MySQLSQL用SELECT语句进行查询
一般格式为:
SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>]...
FROM <表名或视图名> [,<表名或视图名>] ...
[WHERE <条件表达式>]
[GROUP BY <列名列表1> [HAVING <条件表达式>] ]
[ORDER BY <列名列表2> [ASC|DESC]]
2 单表查询
2.1 列查询
1)查询指定列
eg:查询全体学生的学号与姓名。---> select Sid,Sname from Student;
2)查询所有列(全表查询)
select * from Student;
3)查询计算列
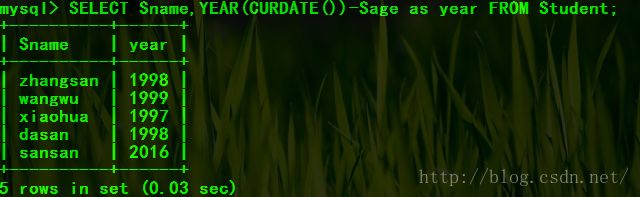
eg:查询所有学生的出生年份
SELECT Sname,YEAR(CURDATE())-Sage as year FROM Student;
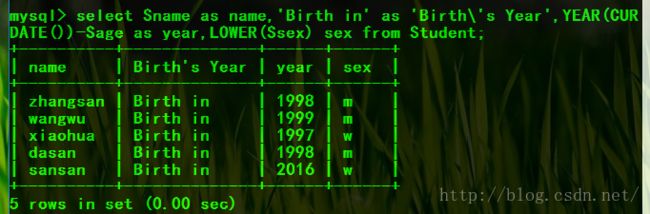
eg:查全体学生的姓名、出生年份和性别,要求用小写字母表示性别。
select Sname,'Birth in',YEAR(CURDATE())-Sage as year,LOWER(Ssex) from Student;
select Sname as name,'Birth in' as 'Year of Birth',YEAR(CURDATE())-Sage as year,LOWER(Ssex) sex from Student;
select Sname as name,'Birth in' as 'Birth\'s Year',YEAR(CURDATE())-Sage as year,LOWER(Ssex) sex from Student;(将出生年份列的别名改为Birth's Year)
结果:
2.2 行查询
1)消除重复行
eg:select DISTINCT Sage from Student;
2)查询满足条件的行
通过WHERE语句来实现
条件
比较大小 =,>,<,>=,<=,!=,<>,!>,!<
确定范围 BETWEEN AND,NOT BETWEEN AND
确定集合 IN, NOT IN
字符匹配 LIKE, NOT LIKE
空值判断 IS NULL,IS NOT NULL
组合条件 NOT,AND,OR
a.比较大小
eg:查询全部的男生。--->select * from Student where Ssex='M';
eg:查询年纪在19岁 以下的学生--->select * from Student where Sage<19;
b.确定范围
eg:查询年龄在19到23的学生的姓名、性别。
select Sname,Ssex from Student where Sage between 19 and 23;(不在19-23:select Sname,Ssex from Student where Sage NOT between 19 and 23 )
c.确定集合
eg:查找地址在上海和西安的学生。
select * from Student where Scity in ('西安','上海');
d.字符匹配
%:代表任意字符串。如a%b:a开头b结尾,长度>=2
_:代表任意一个字符。如a_b:a开头b结尾, 长度为3
eg:查看地址带有‘安’字的学生信息。
select * from Student where Scity like '%安%';
e.空值判断
eg:找出地址为空的学生姓名。
select Sname from Student where Scity is null;
f.组合条件查询
用NOT、AND、OR和括号连接多个简单查询条件,形成一个复杂查询条件。
eg:查询地址在西安,性别男性的学生。
select * from Student where Scity='西安' and Ssex='M';
2.3 使用函数
COUNT(*) 统计元组个数
COUNT(<列名>) 统计列值的个数(不统计null)
SUM(<列名>) 计算数值型列的总和
AVG(<列名>) 计算数值型列的平均值
MAX/MIN(<列名>) 求列的最大值/最小值
#如果指定DISTINCT,则在计算时要取消重复值。eg:COUNT([DISTINCT] <列名>)
eg:查询学生的总人数--->select count(*) from Student;
查询不同的城市数--->select count(distinct Scity) from Student;
此外,函数还有字符串函数,日期时间函数,流程函数等,不再一一尝试。
2.4 对查询结果进行分组
用GROUP BY子句按列值相等的原则对查询结果进行分组。
eg:学生中男生女生的人数
select Ssex,count(*) from Student group by Ssex;
2.5 使用HAVING筛选分组
WHERE与HAVING的区别:作用对象不同。
WHERE作用于表,选择元组,不能直接包含集函数。
HAVING作用于组,选择组,常包含集函数。
eg: select Ssex,count(*) from Student group by Ssex having count(*)>2;
2.6 对查询的结果排序
用ORDER BY指定按某些列升序(ASC)或降序(DESC) ,其中ASC为缺省值。
eg:将id号进行从大到小排序。
select * from Student order by Sid desc;
(只有男生)select * from Student where Ssex='M' order by Sid desc;
3. 连接查询
1)等值查询
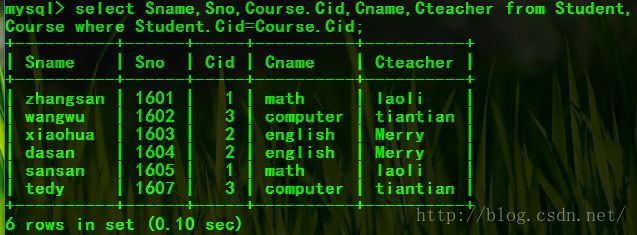
eg:查询学生及其选课情况
select Sname,Sno,Course.Cid,Cname,Cteacher from Student,Course where Student.Cid=Course.Cid;
两种特殊的连接:广义笛卡儿积、自然连接。
2)自身连接
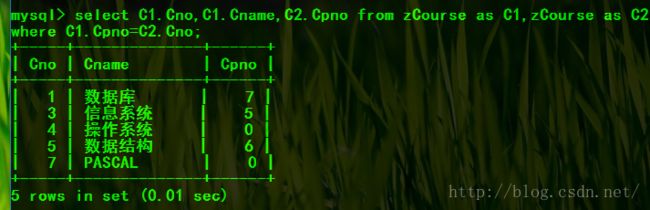
准备课表zCourse 每节课都有先行课,找出每门课的先行课的先行课。


select C1.Cno,C1.Cname,C2.Cpno from zCourse as C1,zCourse as C2 where C1.Cpno=C2.Cno
表别名的作用:
1)若FROM后有相同的表,则要取不同的别名,否则无法表达目标列和连接条件 。
2)表名较长时为了缩短目标列和连接条件, 可取较短的别名。
3)AS可以省略(与目标列别名相同)
3)外连接
Student表和Course表的左连接:
select Sid,Sname,Sno,S.Cid,Cname from Student S left join Course C on S.Cid=C.Cid group by Sid;
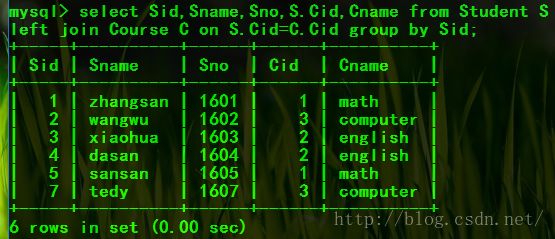
Student表和Course表的右连接:
select Sid,Sname,Sno,C.Cid,Cname from Student S right join Course C on C.Cid=S.Cid;

#理解左连接查询方式(以两表id相等作为on的条件):
先将左表数据查出,然后根据on后面的条件,将右表中凡是id与左表id相等的记录都查出来,与匹配的左表记录依次排成一行或多行,若无匹配的记录,则显示null。(右连接也同样)
4)复合连接
WHERE中有多个条件的连接
查询学生(Student)的学号,姓名,课程名(Course)及成绩(CS)。
SELECT Student.Sno, Sname, Cname, Grade
FROM Student, SC, Course
WHERE Student.Sno=SC.Sno
AND SC.Cno=Course.Cno
#含n张表的连接查询至少应有n-1个连接条件,否则在某些位置将蜕化为笛卡尔积。
4.嵌套查询
1)带有IN运算符的子查询
eg:确定与‘刘晨’同学科的同学
分步实现:
①确定“刘晨”所在系
SELECT Sdept FROM Student
WHERE Sname='刘晨'
②查找所有IS系或MA系的学生。
SELECT Sno, Sname, Sdept FROM Student
WHERE Sdept IN ('IS', 'MA' )
用嵌套查询实现:
SELECT Sno, Sname, Sdept
FROM Student
WHERE Sdept IN ( SELECT Sdept
FROM Student
WHERE Sname=‘刘晨’ )
2)带有比较运算的子查询:父查询与子查询之间用比较运算符连接。
eg:查询“刘晨”所在系的每个学生比“刘晨”大多少岁。
SELECT Sname, Sage-( SELECT Sage
FROM Student
WHERE Sname = '刘晨' )
FROM Student
WHERE ( SELECT Sdept FROM Student
WHERE Sname= '刘晨' ) = Sdept
3)带ANY或ALL的子查询:子查询结果包含多个单列元组时使用比较运算符+ANY或ALL:
eg:查询其他系中比IS系某个学生年龄小的学生名单
SELECT * FROM Student
WHERE Sdept <> 'IS' AND Sage
SELECTSage FROM Student
WHERE Sdept='IS' )
ORDER BY Sage DESC
4)带EXISTS的子查询:EXISTS:存在量词,用来对子查询进行检查,若结果非空则返回 true,否则返回 false
eg:查询与“刘晨” 同系的学生:
SELECT Sno, Sname, Sdept FROM Student AS s
WHERE EXISTS (
SELECT * FROM Student AS t
WHERE t.Sname='刘晨' AND t.Sdept=s.Sdept)
说明:a) 子查询的目标列用*,给出列名无意义。
b) 子查询依赖于父查询的元组--->相关子查询。
c) 相关子查询的处理过程:需多次执行子查询