Pulsar IO 简介
翻译:StreamNative——Sijia
Apache Pulsar 是业界领先的消息系统。使用消息系统时,一个较为常见的问题就是:将数据移入或移出消息平台的最佳方法是什么?当然,用户可以使用 Pulsar 的 consumer 和 producer API 编写自定义代码,来传输数据。但除此之外,是否还有其他方法呢?
以下为用户提出的一些相关问题:
- 要将数据发布到 Pulsar 或使用 Pulsar 中的数据,我应该在哪里运行相应程序?
- 要将数据发布到 Pulsar 或使用 Pulsar 中的数据,我应该怎样运行相应程序?
用户之所以会提出这些问题,是因为其他消息/发布-订阅系统没有提供有组织且容错的方式来帮助用户从外部系统输入数据或将数据输出到外部系统,因而用户需要寻求自定义解决方案并手动运行。
为了解决上述问题并简化这一过程,我们推出了 Pulsar IO。Pulsar IO 通过利用现有的 Pulsar Functions 框架来输入/输出数据。而 Pulsar Functions 框架的所有优势(如:容错性、并行性、弹性、负载平衡、按需更新等)都可以直接被 Pulsar 输入/输出数据的应用程序所利用。
而且,我们发现经常会出现这样的情况,用户花很大功夫(因为他们不是消息系统方面的专家,可能也不想成为这一领域的专家)去编写自定义程序,用于从消息传递系统访问数据。自定义编写这些应用程序不仅会很困难,而且我们发现,许多用户在尝试实现执行相同功能的应用程序时,做了相同的工作。归根结底,消息系统只是用于移动数据的工具,因此,在设计 Pulsar IO 框架时,我们的主要目标之一就是易用性。我们希望用户能够在不编写任何代码,也不用同时成为 Pulsar 和外部系统专家的情况下,可以从外部系统输入数据或将数据输出到外部系统。我们将在下文介绍如何达成这一目标。
Pulsar IO 框架是什么样的?
首先,我们定义两个应用程序,一个作为 source 将数据输入到 Pulsar ,另一个作为 sink 从 Pulsar 接收数据。

图 1. Pulsar source 和 sink
Source 将数据从外部系统导入 Pulsar,而 sink 将数据从 Pulsar 导出到外部系统。具体来看,source 从外部系统读取数据,并将数据写入 Pulsar topic,而 sink 从一个或多个 Pulsar topic 读取数据,并将数据写入外部系统。
Pulsar IO 框架在现有的 Pulsar functions 框架上运行。 单个 source 和 sink 可以像 function 一样与 Pulsar broker 一起运行,如图 2 所示。
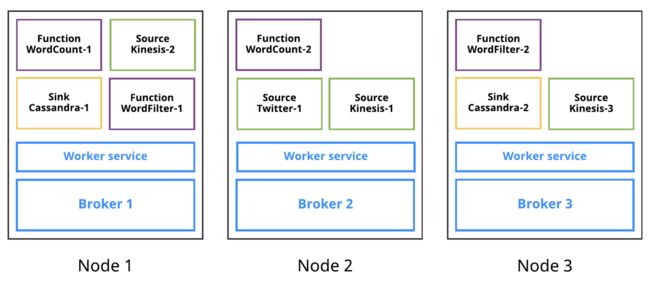
图 2. 运行在 broker 上的 source、sink、function
因此,Pulsar Functions 框架的所有优势都适用于 Pulsar IO 框架,即 sink 和 source 应用程序。
正如前面提到的,我们的设计目标包括用户无需编写任何自定义应用程序,也无需编写任何代码就可以将数据移入或移出 Pulsar。因此,Pulsar IO 框架中有多种内置 source 和 sink(Kafka、Twitter Firehose、Cassandra、Aerospike 等,还会支持更多),用户只需使用一个命令便可运行。用户因此可以关注于业务逻辑,而无需担心实现细节。
如何使用 Pulsar IO
使用 Pulsar IO 框架很容易。用户可以在命令行界面使用一行简单的命令启动内置 source 或 sink。例如,用户可以用下面的命令来提交 source 到已有的 Pulsar 集群,命令格式如下:
$ ./bin/pulsar-admin source create \
--tenant \
--namespace \
--name \
--destinationTopicName \
--source-type
以下示例为运行 twitter firehose source 的命令,用于将 Twitter 中的数据导入 Pulsar:
$ ./bin/pulsar-admin source create \--tenant test \
--namespace ns1 \
--name twitter-source \
--destinationTopicName twitter_data \
--sourceConfigFile examples/twitter.yml \
--source-type twitter
经过以上步骤,用户即可向 Pulsar 输入数据,而无需编写或编译任何代码。唯一可能需要的是一个配置文件,用于为该 source 或 sink 指定某些配置。用户可以通过以下格式的命令向现有的 Pulsar 集群中提交待运行的内置 sink:
$ ./bin/pulsar-admin sink create \
--tenant \
--namespace \
--name \
--inputs \
--sink-type
以下为运行 Cassandra sink 的示例命令,用于将数据从 Pulsar 导出到 Cassandra:
$ ./bin/pulsar-admin sink create \
--tenant public \
--namespace default \
--name cassandra-test-sink \
--sink-type cassandra \
--sinkConfigFile examples/cassandra-sink.yml \
--inputs test_cassandra
更多关于如何运行 Cassandra source 的信息,参阅快速入门指南。
以上命令显示了如何在“集群”模式下(即作为现有 Pulsar 集群的一部分)运行 source 和 sink。除此之外,还可以在“本地运行”模式下将 source 和 sink 作为独立进程运行,这一模式会在机器上生成本地进程并且运行 source 或者 sink 的逻辑。本地运行模式有助于测试和调试,但是,需要用户自行监控和监督。以下为在本地运行模式下运行 source 的命令示例:
$ ./bin/pulsar-admin sink localrun \
--tenant public \
--namespace default \
--name cassandra-test-sink \
--sink-type cassandra \
--sinkConfigFile examples/cassandra-sink.yml \
--inputs test_cassandra
由于 Pulsar IO 框架在 Pulsar Functions 上运行,因此可以通过更新参数和配置来动态更新 source 或 sink。例如,当希望利用前面提到的 Twitter firehose source 将数据输入到另一个 Pulsar topic 时,可以执行以下命令:
$ ./bin/pulsar-admin source update \--tenant test \
--namespace ns1 \
--name twitter-source \
--destinationTopicName twitter_data_2 \
--sourceConfigFile examples/twitter.yml \
--source-type twitter
也可以使用同样格式的命令更新 sink。大多数 source 和 sink 的更新都可以在运行时进行配置,从而简化修改、测试、部署等流程。
如果要自定义实现一个小众的用例,则可以通过实现一个简单的界面来创建 source 或 sink。但是,Pulsar IO 的目的是帮助用户直接使用现有的内置 source 或 sink,而不必自己手动实现 source 或 sink。
实现自定义 source
要创建自定义 source,用户需要编写一个实现 source 接口的 Java 类:
public interface Source extends AutoCloseable {
/**
* Open source with configuration
*
* @param config initialization config
* @throws Exception IO type exceptions when opening a connector
*/
void open(final Map config) throws Exception;
/**
* Reads the next message from source.
* If source does not have any new messages, this call should block.
* @return next message from source. The return result should never be null
* @throws Exception
*/
Record read() throws Exception;
}
这是一个 source 实现的简单示例:
public class TestSource implements Source {
private int i = 0;
@Override
public void open(Map config) throws Exception {
}
@Override
public Record read() throws Exception {
return () -> i++;
}
@Override
public void close() throws Exception {
}
}
在上面的 source 示例中,单调递增的整数被传入到 Pulsar。实现 “Record” 接口的对象需要通过 “read” 方法返回,因为 “Record” 接口包含可用于实现不同消息传递语义或保证的字段,例如 exactly-once/effectively-once。在后续文章中,我将详细讨论如何执行此操作。
实现自定义 sink
要创建自定义 sink,用户需要编写一个实现 sink 接口的 Java 类:
public interface Sink extends AutoCloseable{
/**
* Open Sink with configuration
*
* @param config initialization config
* @throws Exception IO type exceptions when opening a connector
*/
void open(final Map config) throws Exception;
/**
* Write a message to Sink
* @param inputRecordContext Context of value
* @param value value to write to sink
* @throws Exception
*/
void write(RecordContext inputRecordContext, T value) throws Exception;
}
例如,一个简单的 sink 实现:
public class TestSink implements Sink {
private static final String FILENAME = "/tmp/test-out";
private BufferedWriter bw = null;
private FileWriter fw = null;
@Override
public void open(Map config) throws Exception {
File file = new File(FILENAME);
// if file doesnt exists, then create it
if (!file.exists()) {
file.createNewFile();
}
fw = new FileWriter(file.getAbsoluteFile(), true);
bw = new BufferedWriter(fw);
}
@Override
public void write(RecordContext inputRecordContext, String value) throws Exception {
try {
bw.write(value);
bw.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void close() throws Exception {
try {
if (bw != null)
bw.close();
if (fw != null)
fw.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
以上示例说明 sink 如何从 Pulsar 读取数据并写入文件。与 source 接口类似,sink 接口中的 “write” 方法有一个 RecordContext 参数。此参数为 sink 提供需要写入外部系统的值的 context。RecordContext 参数可用于实现能够提供不同级别的消息传递语义或保证(如:Exactly-once/Effective-once)的 sink。在后续文章中,我们将对此进行更深入的讨论。
用户可以通过类似于运行内置 source 和 sink 的方式来提交自定义 source 和 sink:
$ ./bin/pulsar-admin source create \
--className \
--jar \
--tenant \
--namespace \
--name \
--destinationTopicName
命令示例如下:
$ ./bin/pulsar-admin source create \
--className org.apache.pulsar.io.twitter.TwitterFireHose \
--jar \~/application.jar \
--tenant test \
--namespace ns1 \
--name twitter-source \
--destinationTopicName twitter_data
在现有 Pulsar 集群中提交待运行的自定义 sink 的命令格式如下:
$ ./bin/pulsar-admin sink create \
--className \
--jar \
--tenant test \
--namespace \
--name \
--inputs
命令示例:
$ ./bin/pulsar-admin sink create \
--className org.apache.pulsar.io.cassandra \
--jar \~/application.jar \
--tenant test \
--namespace ns1 \
--name cassandra-sink \
--inputs test_topic
使用 Pulsar IO 框架的优势
如上所述,Pulsar IO 框架在现有的 Pulsar Functions 框架上运行。Pulsar IO 充分利用了现有的 Pulsar Functions 框架。作为 Pulsar IO 的组成部分,source 和 sink 拥有 Pulsar Functions 的所有优势:
| 优势 | 详细介绍 |
|---|---|
| 执行灵活性 | Source 和 sink 都可以作为现有集群的一部分或作为本地进程来运行 。 |
| 并发性 | 要增加 source 或 sink 的吞吐量,只需添加简单的配置即可运行更多 source 和 sink 实例。 |
| 负载均衡 | 当 source 和 sink 以集群模式运行时,能达到负载均衡。 |
| 容错、监控、metrics | 如果 source 和 sink 以“集群”模式运行,则作为 Pulsar function 框架一部分的 worker 服务将自动监控已部署的 source 和 sink。当节点发生故障时,将自动重新部署 source 和 sink 到运作节点,并自动收集 metrics。 |
| 动态更新 | 动态更新多项配置,如:单个 connector 的并行性、源代码、输入/输出 topic 等。 |
| 数据本地化 | 由于 broker 为 topic 的读写请求提供服务,因此在 broker 附近运行 source 和 sink 可以减少网络延迟和网络带宽的使用率。 |
如何试用?
希望本文清楚地向你展现了 Pulsar IO 的框架,易于使用的原因,以及如何将数据导入/导出 Pulsar。Pulsar IO 框架随 Pulsar 2.1.0 官方发行版一起正式发布。
更多文档,点击这里。